I am starting up a subproject to go and validate that fq_codel is implemented correctly, in the nss drivers, as well as attempting to take it apart as for the interactions with other subsystems in the kernel, such as GRO, device drivers, and the wifi implementation. Along the way I hope to have a few teaching moments as to how to use flent, understanding network behaviors at various RTTs, etc.
There's so much hardware using this algo now that I hope to rein in some support for each test from the community here.
ISP speed is ~100Mbps/35Mbps. I have configured 95000 down and 30000 up.
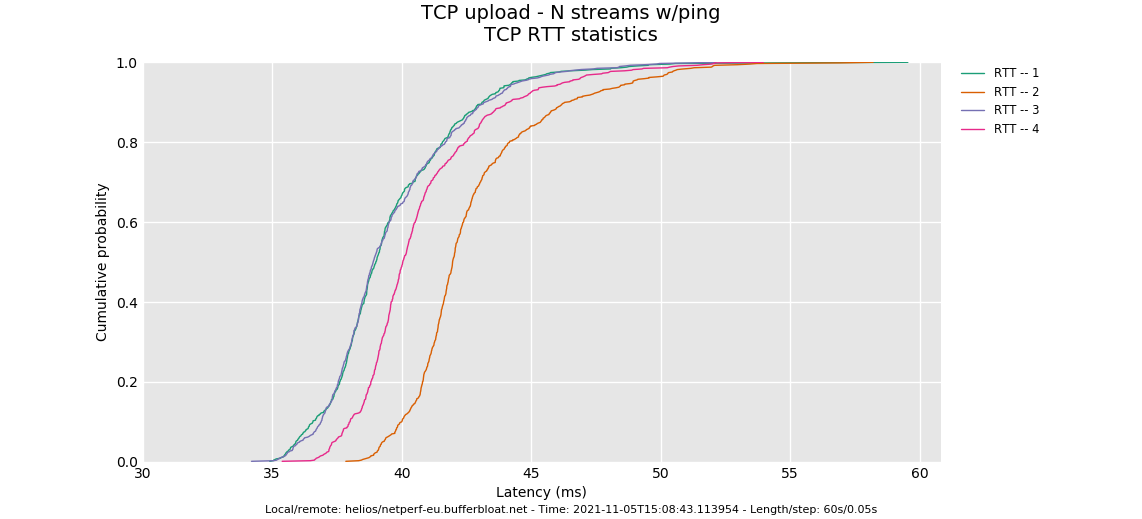
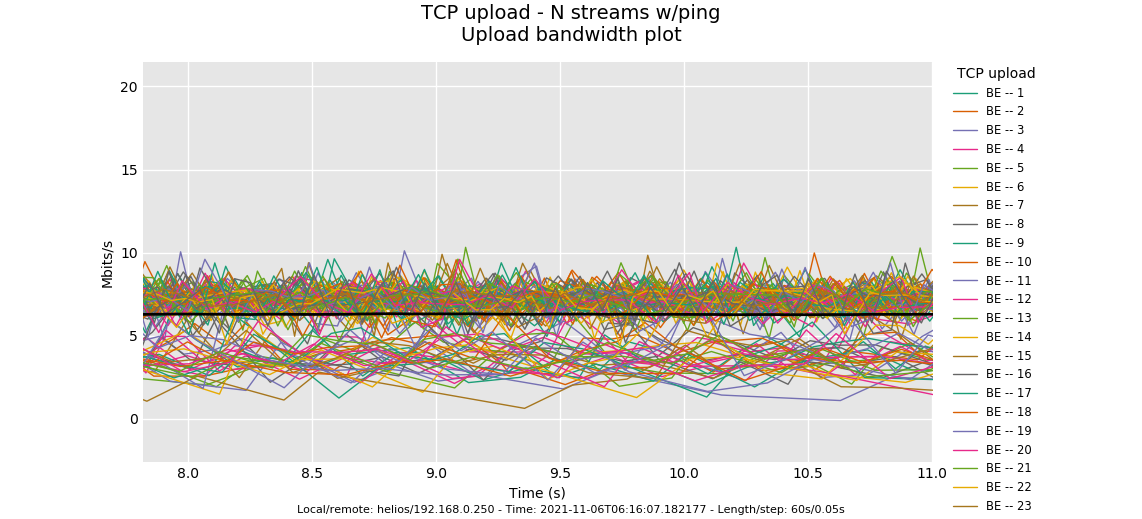
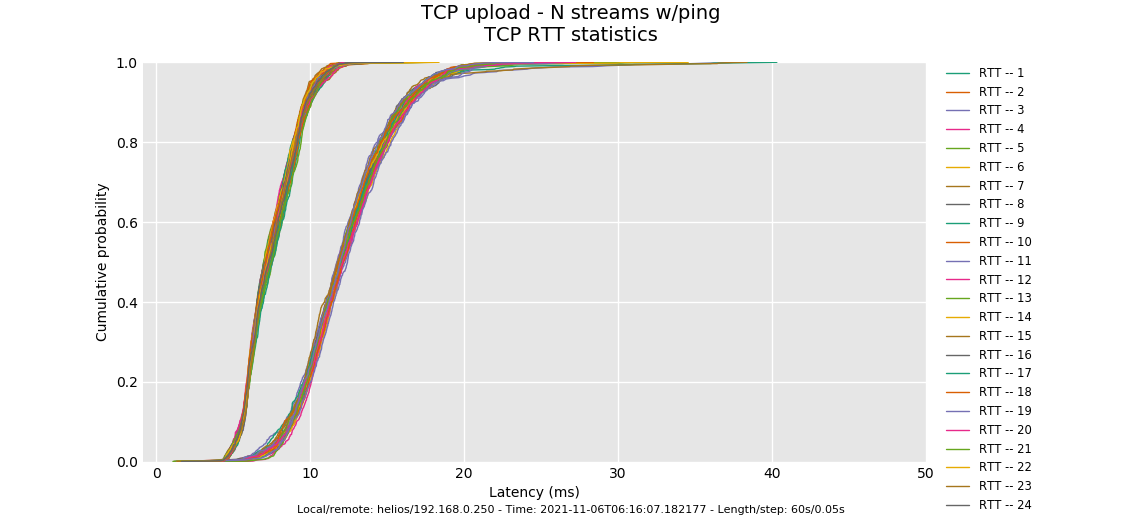
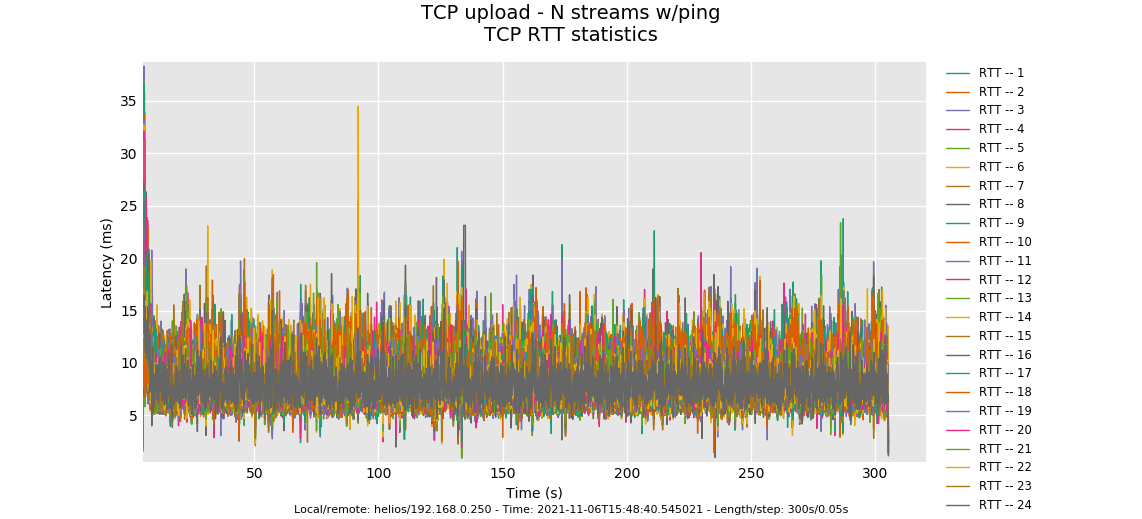
--socket-stats only works on the up. Both the up and down look ok, however the distribution of tcp RTT looks a bit off. These lines should be pretty identical.
Three possible causes: 1) your overlarge burst parameter. At 35Mbit you shouldn't need more than 8k!! The last flow has started up late and doesn't quite get back into fairness with the others. 2) They aren't using a DRR++ scheduler, but DRR. 3) Unknown. I always leave a spot in there for the unknown and without a 35ms rtt path to compare this against I just go and ask you for more data
No need for more down tests at the moment.
A) try 8 and 16 streams on the up.
B) try a vastly reduced htb burst.
A packet capture of a simple 1 stream test also helps me on both up and down, if you are in a position to take one. I don't need a long one (use -l 20) and tcpdump -i the_interface -s 128 -w whatever.cap on either the server or client will suffice.
I am temporarily relieved, it's just that the drop scheduler in the paper was too agressive above 100mbit... and we haven't tested that on this hardware....
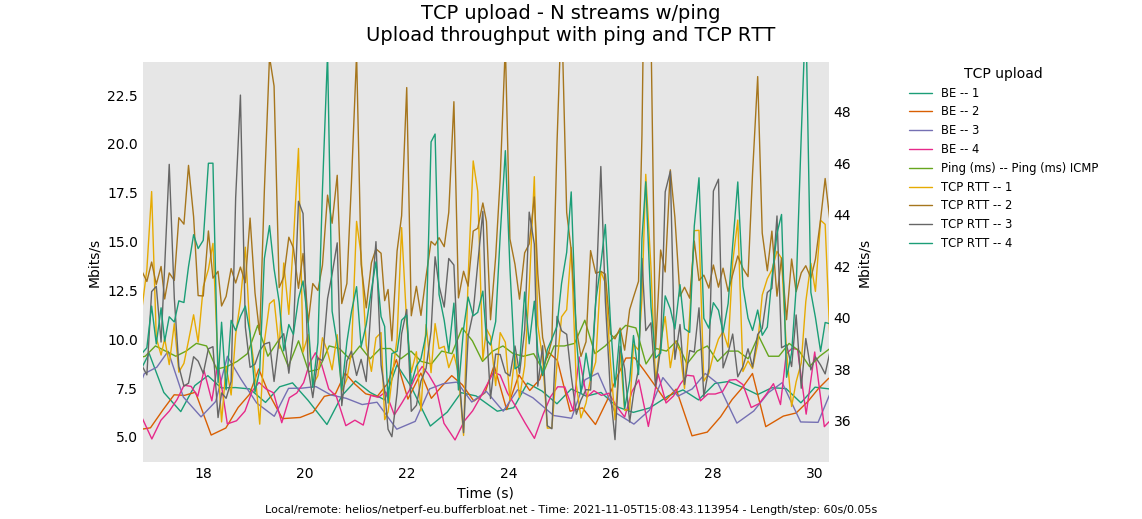
Anyway this more clearly shows two of the flows are "stuck":
I ran another test. This time I set up netserver on wan side. Set up/download for my nss.qos to 500000 and tested using: flent --step-size=.05 --socket-stats --te=upload_streams=4 tcp_nup -H 192.168.1
.250
Please: Hit it with 128 flows at that speed. We should see some hash collisions, which is ok, and from those we can infer how many flows they really have.
THEN the all seeing all knowing rrul test.
I'm very impressed that it only eats 3% of cpu at this speed. I'd be even more impressed if it operated correctly.
The estimated completion time is a little off, at first I thought flent just got stuck
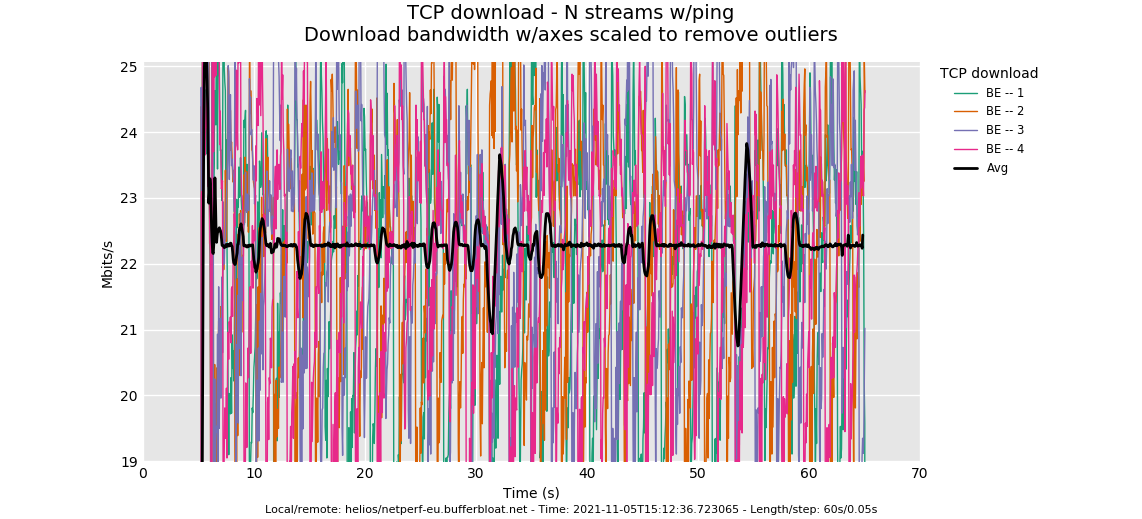
I set 900000 up/down in qos settings:
tc -s qdisc | grep burst
qdisc nsstbl 1: dev eth0 root refcnt 2 buffer/maxburst 112500b rate 900Mbit mtu 1514b accel_mode 0
qdisc nsstbl 1: dev nssifb root refcnt 2 buffer/maxburst 112500b rate 900Mbit mtu 1514b accel_mode 0
Still pretty much no load on the router. The box where netserver runs is only a tiny Celeron(Intel(R) Celeron(R) N4100 CPU @ 1.10GHz) hopefully it is fast enough to not cause any issues in the runs.
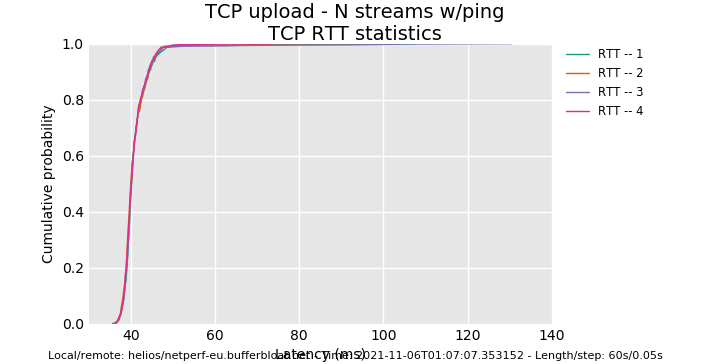
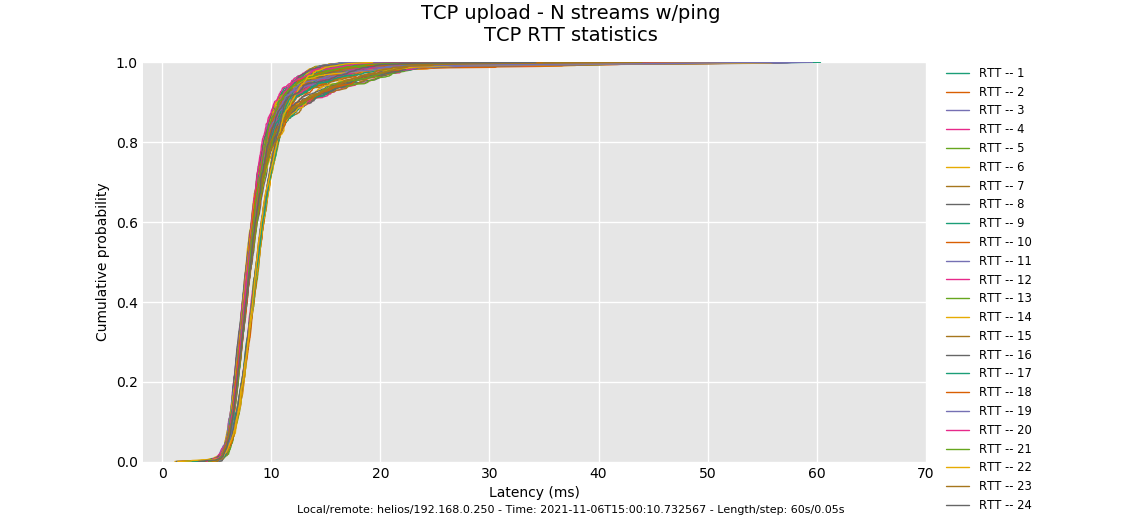
OK, that's puzzling. The odds were good that we'd see a third tier hash collission here, and we don't, and the bimodal distribution is odd... way too many flows in this other tier to be a birthday paradox at flows 1024.
And that's And codel, should have controlled all the RTTs here despite the collision - throughput should have been different but observed latencies eventually the same.
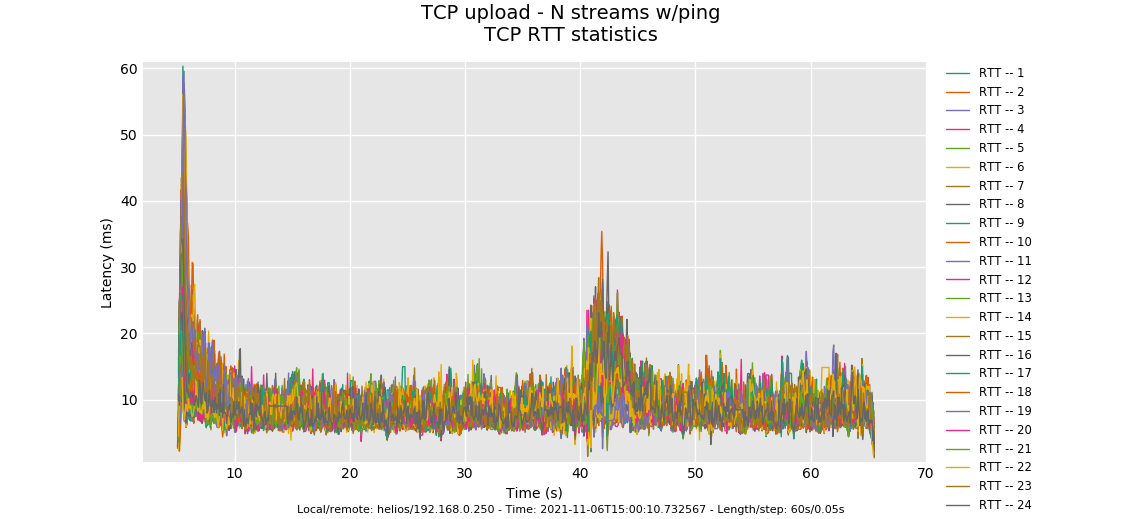
This one doesn't have that spike. Dang it. 50GB of memory used up for a good cause tho. Doing more than one plot OOMed my laptop also. Don't need to do -l 300 again for a while...
This is a pretty normal looking result. I note I am not recommending 16 flows to your end-users, it was just seeing if codel was correct.
OK, in looking at this and the 3 others, we hit a limit of 800Mbit/sec hard for some reason. Should have been about 870, I think, but haven't done the math. Add 20% or so to your burst parameter?