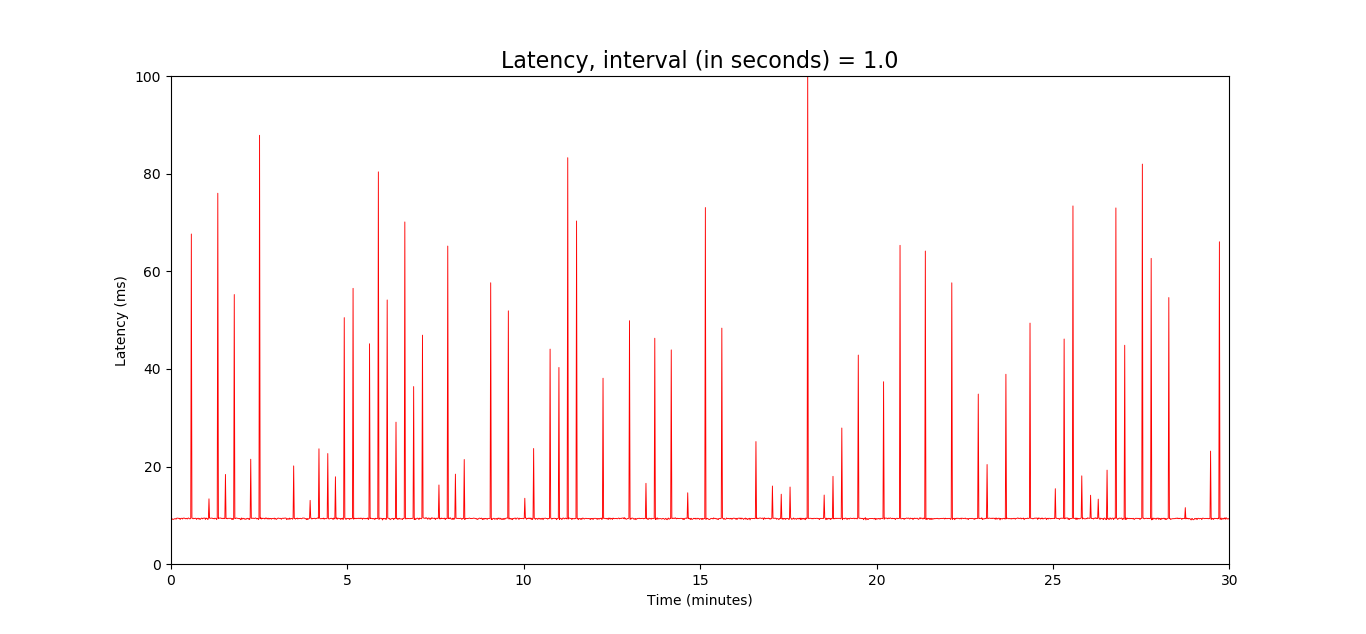
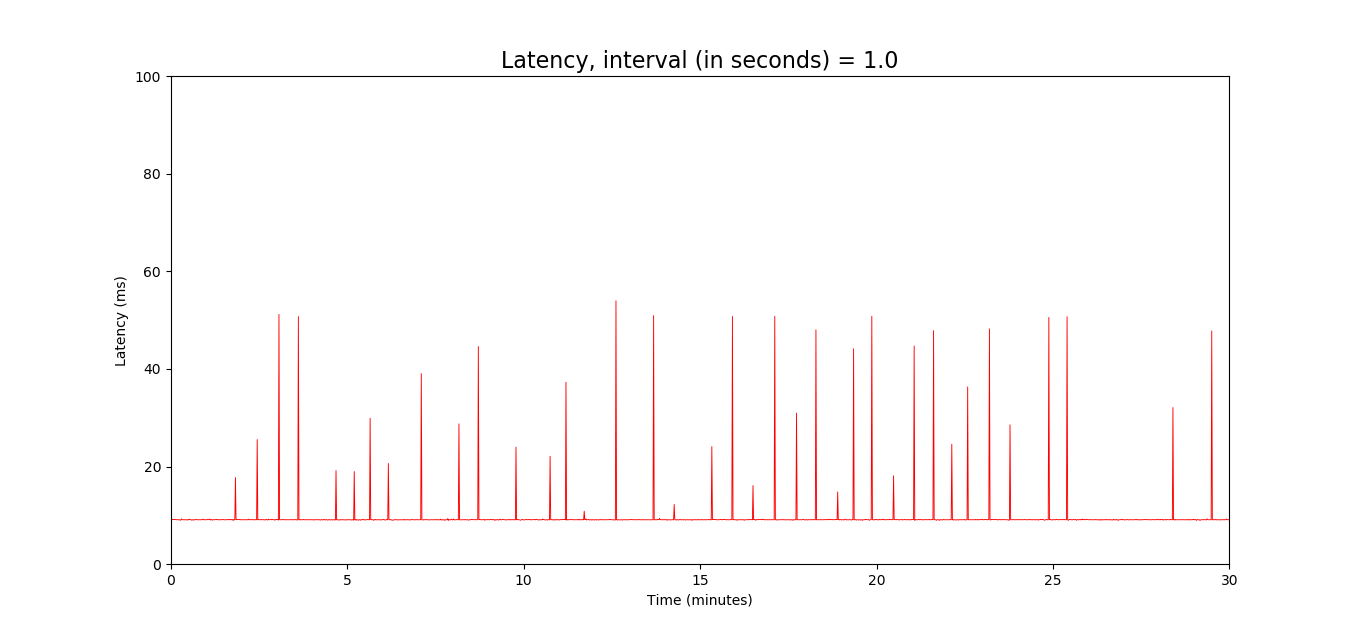
I've been looking into the R7800 latency issue detailed in this previous forum thread:
First of all I tried and succeeded in reproducing the latency spikes. Here I'm pinging 8.8.8.8 directly from the R7800 every second:
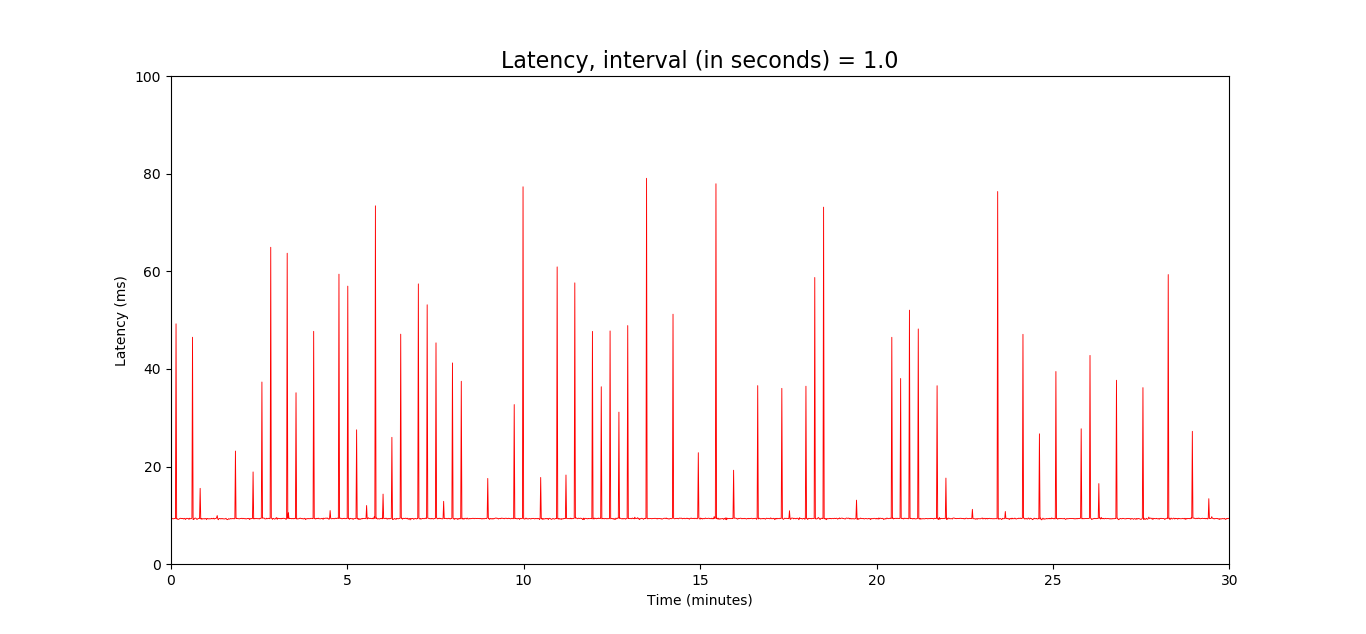
I also tried doing the same from my computer connected to the router by ethernet. And a ping frequency of 1 per second didn't give me any large spikes:
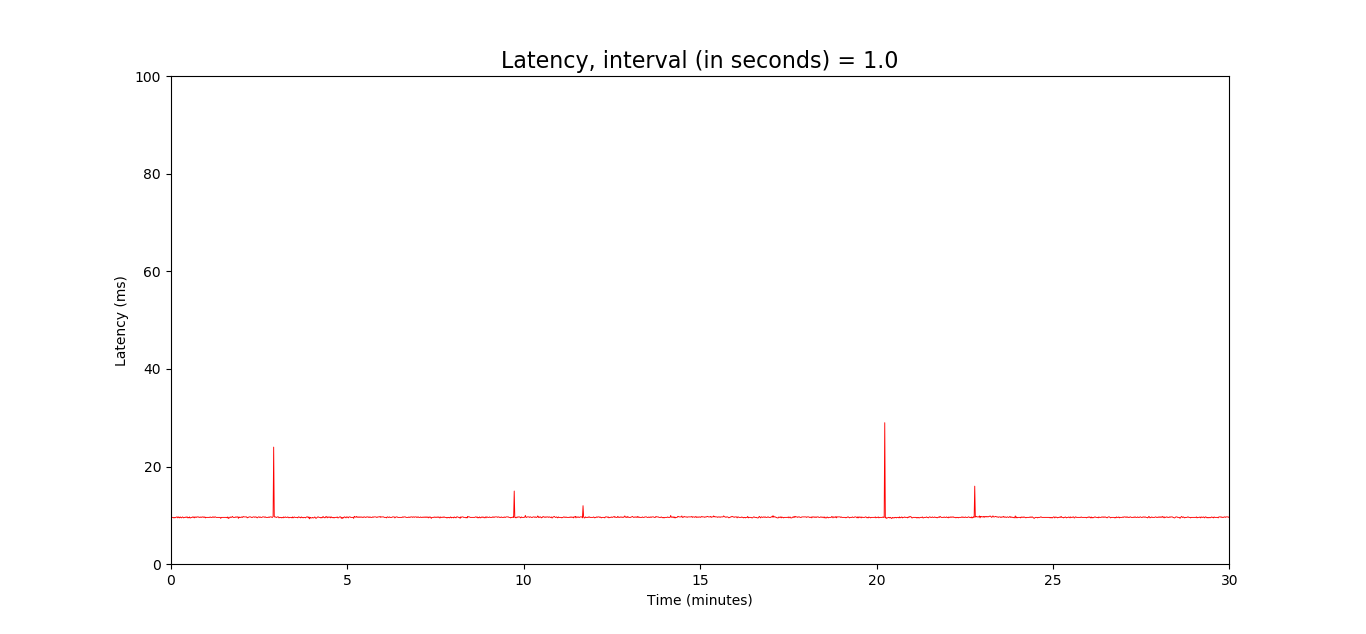
However, increasing the ping frequency to every 0.2 seconds gave a different picture:
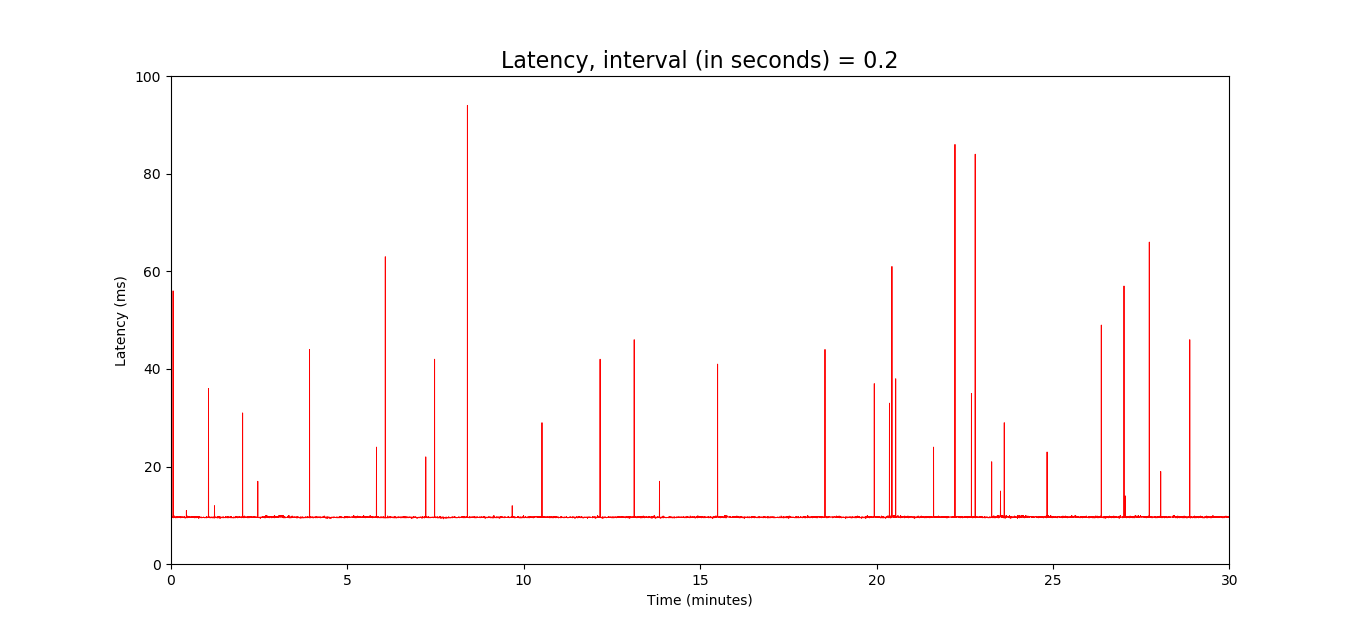
Pinging 8.8.8.8 with the computer connected to the modem directly didn't produce any spikes.
So, in trying to figure out what might cause this I had a look at what htop -d1 showed. htop -d1 updates every 1/10 of a second and I consistently spotted a kworker thread hogging 30-85 percent of core 2 approximately every 2 seconds. This high CPU load lasts for a fraction of a second.
I used ftrace to figure out what kworker was doing by following this guide:
What I found was this:
kworker/1:2-83 [001] dns. 278.480327: workqueue_queue_work: work struct=bf1f6004 function=gc_worker [nf_conntrack] workqueue=dd480400
Running a ping session on the router with timestamps I was able to correlate the high latency to a proceeding kworker spike. Here are some examples:
kworker/1:2-83 [001] dns. 278.480327: workqueue_queue_work: work struct=bf1f6004 function=gc_worker [nf_conntrack] workqueue=dd480400
278.50 64 bytes from 8.8.8.8: seq=15 ttl=59 time=53.656 ms
kworker/1:2-83 [001] dns. 347.600138: workqueue_queue_work: work struct=bf1f6004 function=gc_worker [nf_conntrack] workqueue=dd480400 req_cpu=4 cpu=1
<idle>-0 [000] dnh. 347.629976: workqueue_queue_work: work struct=dccf33c0 function=dbs_work_handler workqueue=dd480200 req_cpu=0 cpu=0
347.63 64 bytes from 8.8.8.8: seq=84 ttl=59 time=85.801 ms
kworker/1:2-83 [001] d.s. 416.730239: workqueue_queue_work: work struct=bf1f6004 function=gc_worker [nf_conntrack] workqueue=dd480400 req_cpu=4 cpu=1
416.75 64 bytes from 8.8.8.8: seq=153 ttl=59 time=66.578 ms
It seems that something related to nf_conntrack is misbehaving.