I am using wrt3200acm as my non-wifi border router and it is having a hard time running bidirectional CAKE for 330/330Mbps line if the client opens many hundreds of connections: CPU usage spikes close to 100% on both cores then other clients experience packet drops and generally very slow performance, especially when I am uploading tons of data.
I have been limiting the damage by constraining the number of concurrent downloads/uploads aws cli is allowed to use to <100 or so, but the problem is that the number of connections should be higher for small files and could be lower for large files, so it is never perfect.
I do not want to use x64 yet, so the question is: what is currently the fastest non-x64 router (wifi is not needed) with at least two ports and in a similar price range? I have seen dev boards for >$1K, which is not an option. I also want to avoid using Ethernet dongles.
UPDATE: A good old x86_64 has solved the problem. Looks like no ARM is up to the task yet.
I've heard your resentment against x86_64, but still have a look at Tips for getting cheap used x86-based firewall with full Gbit NAT (a PC Engines APU) if you are in the US, there are some quite nice devices among the listed examples (four 1000BASE-T ports, no wireless) which may go for 50-80 EUR in lightly used condition. The more modern Sophos sg/ xg range, gateprotect FW-7543B-GP1, Barracuda F18 or Cyberoam CR25ing with baytrail-d (j1900 or E38xx) - just avoid anything older (AMD jaguar, Atom N450/ N270, the various VIA CPUs).
Alternatives include:
RPi4 + USB3 (r8152) ethernet or the dfrobot baseboard with RPi CM4
NanoPi r4s
qoriq (e.g. watchguard M300; source-only for now)
things like the MikroTik RB5009UG
Octeon III+ (fast, but scarce, a dying breed)
Apart from the watchguard M300 (it's out of support, so used devices are often sold out for a bargain) and some of the Octeon III+ all of the examples above will be more expensive than a second hand x86_64 router appliance.
A more traditional approach would be the Belkin rt3200, which should still cope with your requirements - only time will tell if ipq807x can play ball (it has a lot of potential and the development for it has progressed nicely, but there is lots of optimization potential in the network drivers, so I wouldn't bet my horses on these, yet).
Thx, but are you saying that this one with 2 x 1,380 MHz CPUs is faster than 2 x 1,866 MHz CPUs in wrt3200acm?
I do need to run bidirectional CAKE on my PPPoE connection and have no plans to upgrade my line just yet. I also have 17 VLANs (each wired device is isolated and I am only using a single LAN port on my router), but I am not sure if that increases CPU usage.
I don't own either of those, so I'm only relying on the reported figures from various users here. Both 'should' cope with symmetric 330 MBit/s, but you are comparing 2*1.8 GHz cortex A9 (ARMv7) against 2*1.35 GHz cortex A53 (ARMv8) - so arithmetics aren't quite as easy as comparing MHz values (apart from the very different I/O specs).
What I do know, is that baytrail-d/ j1900 can do my 400/200 MBit/s with sqm/cake in practice (and up to 830 MBit/s symmetric in iperf3 benchmarking).
Yeah, every single claim is relative: I was pretty happy with this router for casual use and light work related d/u with a small number of connections. Single connection game download also worked just fine and everyone else was happy. The trouble started when I started to scale out to download a lot of files of very different sizes. This is probably expected, but CAKE seems to need more and more CPU as the number of active connections increases.
Sure, that is expected. Cake aims for really fine-grained optimization, so the number of concurrent data streams directly impacts the calculation work needed. (Intuitively, the calculations might even be somewhat exponential to the number of data streams, but I haven't verified that thought.)
The easiest solution for you might be dropping cake, and switching SQM to e.g. simple / fq_codel. (sure, you said that you need cake, but you might test with other qdiscs)
Cake developers started to recognize already in 2018 that it had become CPU heavy. Quite many bells and whistles were added to it during the long development process.
See this interesting discussion from 2018 starting here: https://lists.bufferbloat.net/pipermail/cake/2018-April/003384.html
The cake development had apparently been done with slower connections, so CPU cycles could be burned for overly complex calculation, but these current half-gigabit speeds were not really the design target when considering embedded device CPUs' calculation power.
My observation is that a9 seems to be a faster core than a53... so a higher clocked a9 is likely faster, however a router's speed depends on more than pure CPU performance....
@fantom-x please post the output of tc -s qdisc from a period when you stress your link.
Cake really does not care much about number of connections the basic hash calculation is the same cost for all packets.
However, the number of concurrently active flows will have an effect, cake only has 1024 hash bins and will do a search if the currently hashed binid is already used (cake operates like an associative cache so will not simply give up on a hash collision, resulting in better flow isolation over fq_codel for the same number of hash bins). You might want to patch your cake to use more has bins (IIRC there is a hard limit around 65K), but there are steps when fq_codel and cake? need to search linearly through all hash bins*, so making the number of bins larger comes at a cost. IIRC the accounting information for fq_codel for 1024 comes down to a single 4K memory page, if you increase that number you might see higher search delay.
*) Mainly when the qdisc is overloaded and needs to drop packets, it searches for the flow with the most queued up packets to drop from.
The MT7622 in the Belkin RT3200 uses Hardware Acceleration for routing, its cpu load is almost 0% when doing a speedtest at 1Gbps. But this hardware NAT doesn't work if you use SQM. and in this case the WRT3200acm will be faster because it is clocked higher.
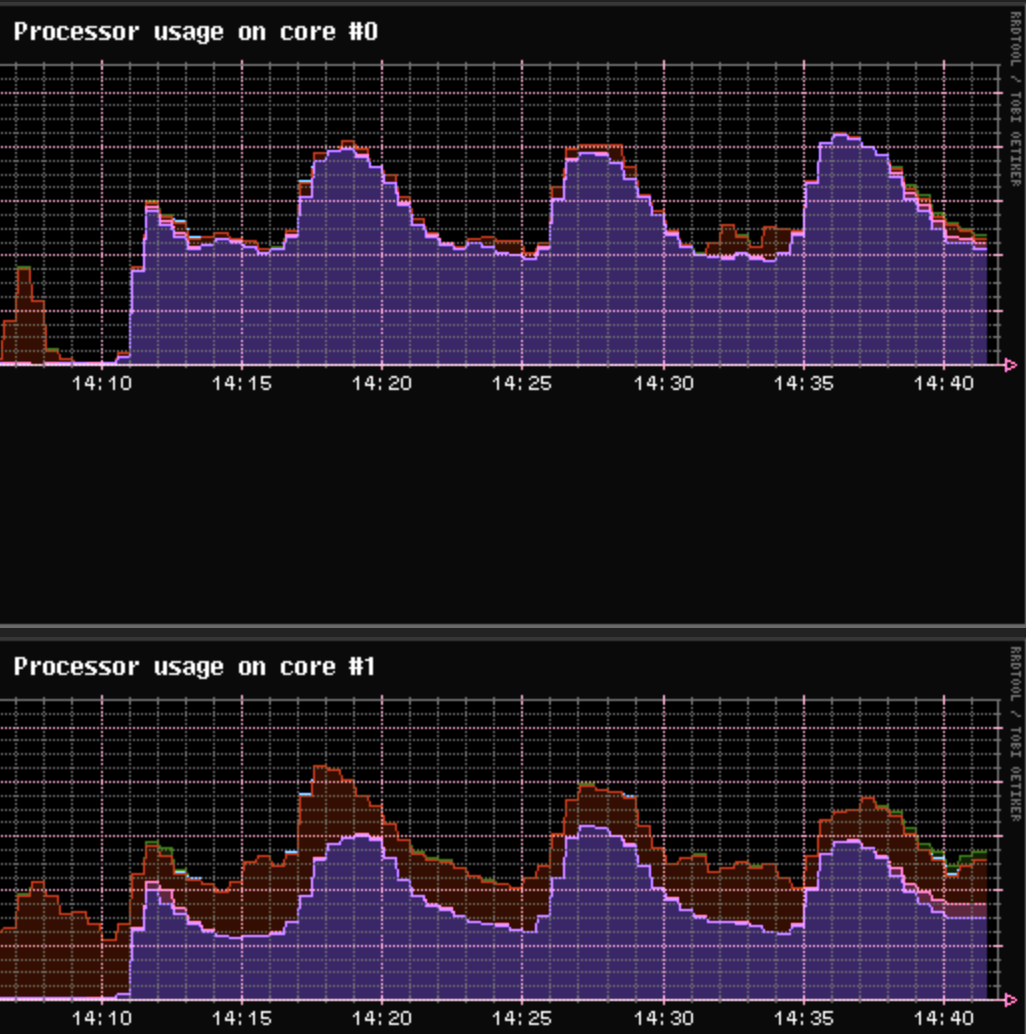
I started the upload and reproduced the issue (I am seeing ~10% of pings to 8.8.8.8 dropped at this time and the pings are 3+ times longer). I do not know how much historical data tc keeps, so I restarted SQM ~1 minute into the upload and ran it for 10 minutes. CPU0 core is at 95..100%, while CPU1 is at 60..70%.
See no collisions at all (but also a pretty quit link).
As I said, either patch sch_cake.c in your own OpenWrt build from: #define CAKE_QUEUES (1024)
to say #define CAKE_QUEUES (65536)
or maybe smaller
or switch to simple.qos and configure fq_codel to use ' flows 65536` via the advanced/dangerous options and see whether any of this makes a difference...
Unclear, you might still be running out of CPU cycles so that might be on top. Are you by chance using smaller than usual packetsizes?
No, simple.qos and fq_codel (simple.qos will also allow cake as leaf qdisc, but that is not going to help with the hash bins unless you build a custom kernel/firmware. In sqm-scripts a given script operates in both directions. But yes, non standard options like flows 650000 should be added to both directions.
1508 on the WAN interface, which becomes 1500 on PPPoE-wan.
I tried fq_codel/simple.qos and ended up with a wave-like CPU usage with peaks being 10..15 minutes apart. When the CPU usage was at the peak (~70..80%), I would see dropped packets and higher latency. When the CPU usage was lower at 40..50%, it was all good. I saw the same behaviour with and without flows 65000. The uploading client reported stable and unchanged upload rate during the test, so I am unsure where the CPU wave-pattern comes from. Looks like CAKE with lower d/u concurrency works the best for me at this time.
I do not have time to build from source, so maybe flows parameter will be added to CAKE at some point hopefully soon. The use case of d/u-ing lots of files is becoming more and more common.
Other than that, it looks like there is no reasonably priced non-x64 platform that is faster that my wrt3200acm...
Nice link, found this test linked by Toke as a pdf further along on that thread. It's interesting that from this (in 2018 at least) fq_codel is indeed a bit lighter on CPU hitting 300Mbit, but cake is still putting out a tighter ping spread where the device is not CPU limited at 250Mbit here. So both have their advantages.
Nah, I do not care about a few dozen bytes more like 536byte packetsbor smaller?
That is a bit odd and feels a bit like an unrelated issue, maybe the CPU scales down frequency, voltage or overheats cyclically?
So cake is unlikely to grow a flows keyword anytime soon.
Typically uploading/downloading files is not done with >= 1 flows per file.... so I think I still do not understand you use case.
At least not a significantly faster platform. If I might ask, why the apparent x86 dislike?
Should not be: aws s3 sync is uploading files in multiple chunks. I seriously doubt they would be using too small packets here, because the goal is throughput.
This router does not have a cpu scaling driver and the temperature stays stable at 70 C under load and 60 idle. I can easily reproduce this when using fq_codel with hundreds of upload streams. This does not show up when using CAKE: CPU usage is stable to flat.
That is a misunderstanding when working with cloud storages like S3. Large files are uploaded/downloaded concurrently and also in multiple chunks at the same time. A single stream is relatively slow, so the way to scale is to do more concurrently. Solution is the same for smaller files: multiple concurrent uploads/downloads. Single S3 downloads and uploads will not saturate my link for sure, not to mention multi gigabit links. aws s3 sync or s4cmd/s5cmd are using concurrent d/u to increase throughput.
aws s3 sync in either direction of a few hundred GBs of files that range from 1K to 5K
The same command but applied to a few hundred of GBs of audio files: 10..100MB each
It is either many many small files or many many smallish file chunks to take advantage of all bandwidth available.
Small size low power are expensive and I do not trust Aliexpress. USFF/SFF are bulky and draw more power while I want to extend the runtime of my UPS. apu2/etc require BIOS update once in a while, which I do not want to keep track of. I prefer a simplicity and low power of an ARM router.
If building your own image it might be worthwhile to check as to MQPrio (replace MQ), and possibly FQ-PIE, to see if lighter weight processes can deliver required throughput on less %CPU.
Thx, but that will take me down a rabbit hole of wanting to optimize things to perfection It is usually hard for me to get out of that, so I prefer to stay with simple even though it might not be ideal.