OK, then I think the stable solution is to limit aws s3 sync to a sane number of concurrent flows, just like that is the best solution for bittorrent as well.
Ah, OK even if each single file gets transferred in a single flow, you are only talking about a handful of packets, so most flows will not exit slow start and hence might not be responsive if cake tries to tell them to slow down...
This technique is called sharding and some folks consider that to be an hostile act...
What makes you believe that ARM devices can be trusted?
I like the APUs, but powerful they are not... by today's standards
I severely doubt that fq_pie is going to be noticeably more CPU efficient than cake or fq_codel based solutions, typically the big cost is not the AQM or scheduler, but the traffic shaper, and once you compare fq_pie with HTB you should be in the same ball park as HTB+fq_codel. Not saying that fq_pie is a bad qdisc, but not sure it would be a silver bullet.
I did not say that. I do not trust a random seller from Aliexpress and prefer to buy from a reputable name company that sells their world wide. That is a good compromise nowadays.
Fair enough. I bought a turris omnia years ago in the indiegogo campaign for similar reasons; for my nominal 100/40 link (sync 116.7/37, shaped to 105/36) it works well. However recent tests with small MSS values indicate that while 105/36 works comfortably the omnia has little reserves for much higher speeds, at least with my router application profile.
That is unfortunate. I wish the number of flows was configurable: if I limit the number of active streams on the client then I will never be able to saturate my link with small files. This approach could have been appropriate for BitTorrent (fun/leasure), but does not seem reasonable for cloud transfers (work)...
Well, I had good success transferring TBs worth of data using rsync over a single TCP flow.... albeit my TBs were mostly static and did not change day after day, and my link was slow enough that saturation was not my goal (the whole transfer took around 2 weeks, and I intended to use the internet during that time as well).
But in your position I would actually "limit the number of active streams on the client" to something giving acceptable performance for small files (which will always be inefficient to transfer) AND also try to increase cake's number of flows.
Now one more question, are you doing this over IPv4 or IPv6? Because you might also run into connection tracking issues on top of the traffic shaper ship-show
Mmmh, puzzling, why this would result in high numbers of hash collisions, however with 1024 hash bins, the excursion close to 1000 is sure to create hash collisions... Maybe it is time to increase the cake flows limit unconditionally, but that would require benchmarking the gains and the costs, and I am not setup to do that.
If you make it configurable first then more of us can pitch in...
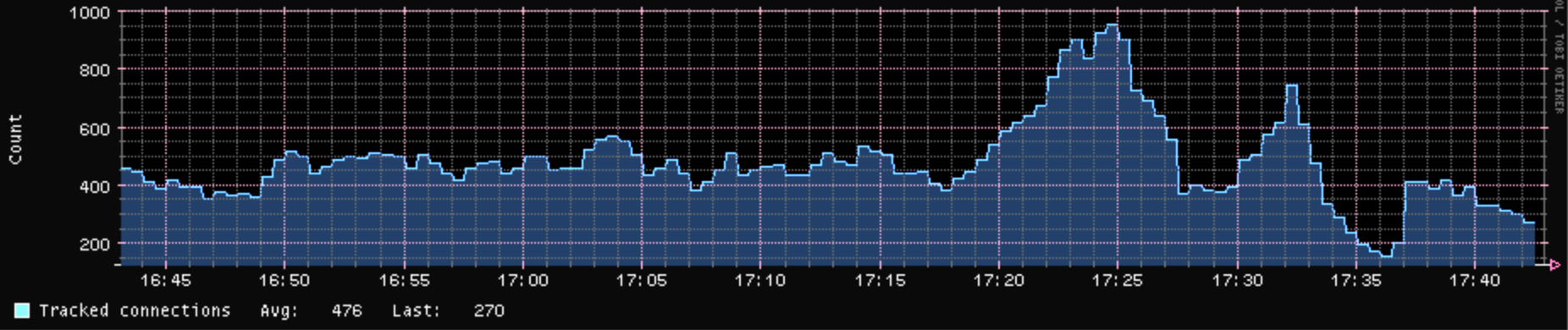
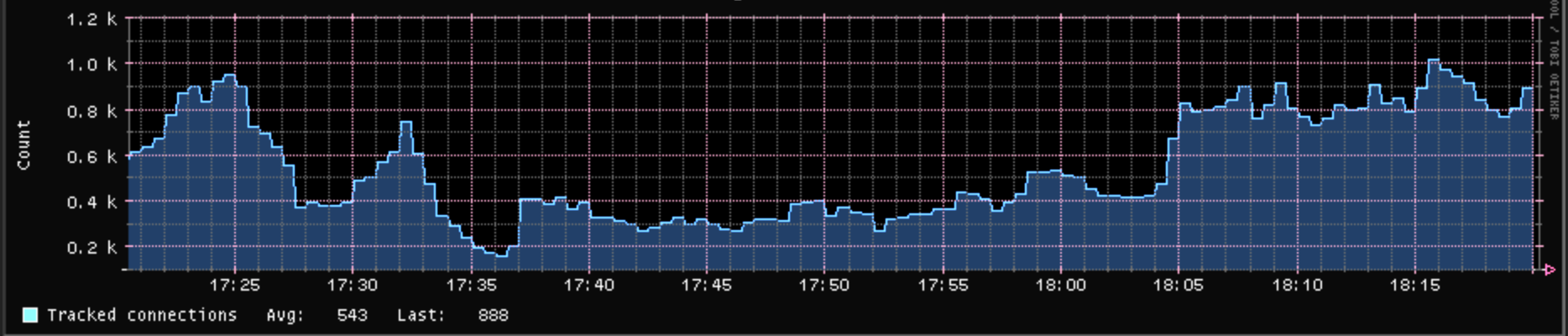
Well, that was when things are running nicely. When things get pear shaped, then I get contract entries very close to 1000 (the most right part of the chart):
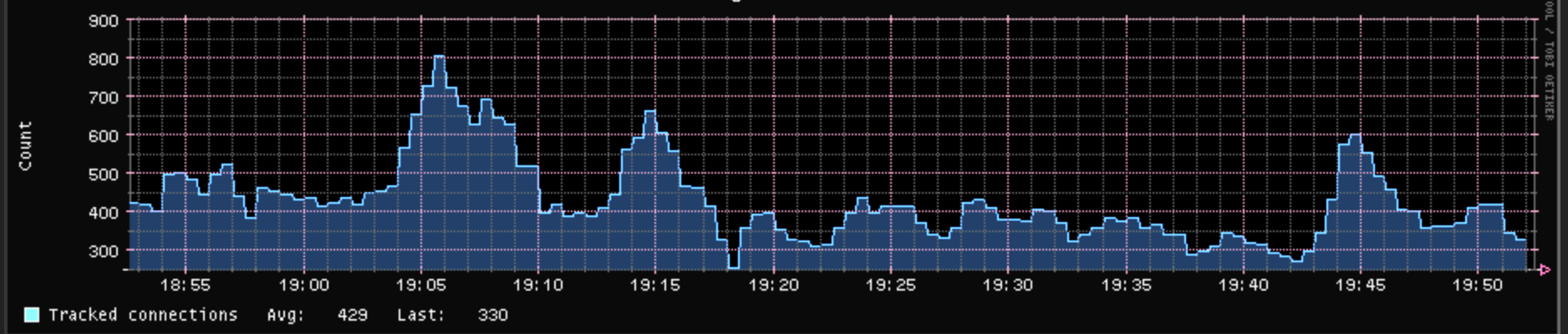
I do not know: the upload rate is constant. File sizes are different and maybe it sometime uploads smaller files and sometime bigger files? No-one else is using the network.
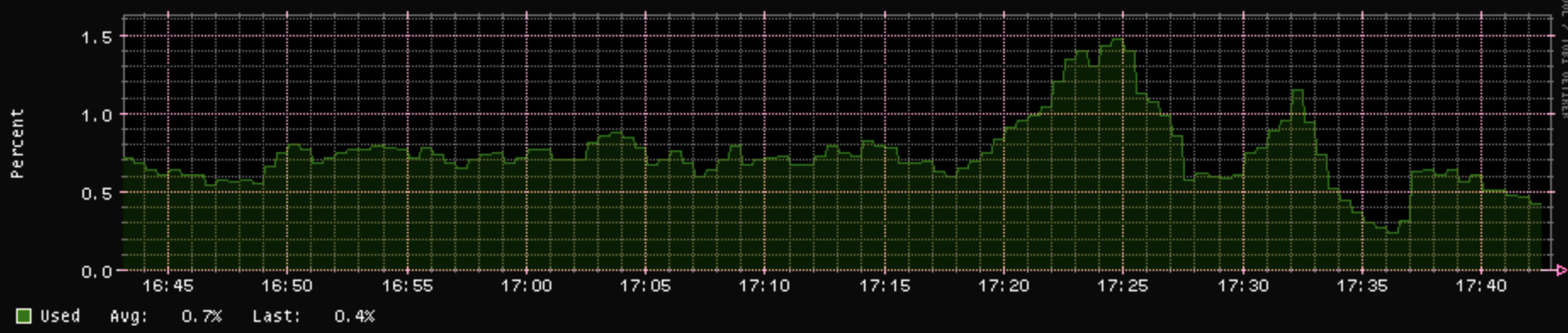
And to confuse things even more, here is the CPU0/1 usage over the last hour followed by contrack usage: there is no correlation. In this case, I am using CAKE & limiting the upload concurrency.
https://docs.aws.amazon.com/cli/latest/topic/s3-config.html has a default of 10 flows. Are you saying that for every file, amazon opens a new connection? We've had http 1.1 pipelining for 2 decades, rsync for longer... in the ideal case, one connection would suffice.
As for the cake flows limit... there is a major difference between cake and fq_codel. cake will hold on to the last packet in the queue and not drop it, so, with a thousand flows, cake accepts the latency hit and accepts and passes the packet.
fq_codel will drop even the last packet in the queue if it has not (it only turns off when the total queue size drops below a MTU, and I've long thought it shouldn't turn off even then). So fq_codel tries hard to bring in all flows eventually to a 5ms target while cake is willing to accept packets from all flows all the time.
In a world where we often see 64 * 1024 fq_codel queues, I viewed that that many packets in flight would make up for a packet dropped to empty a queue, and that essentially DDOSing a fq_codel'd network was less possible if we kept aiming for the target.
So, while I'm not mortally opposed to using more cake queues, the AQM gets less and less effective as you add flows.