Hi all, i have a box with 2 ethernet cards in a simple LEDE bridge configuration. Dnsmasq and firewall are both disabled. The box is placed in between my gateway router and my 600 customers. eth0 is connected to the gateway side and eth1 is connected to the customer side. I have cake setup on eth1 with my upload and download values reversed. The limits work and bufferbloat testing shows good results. I am using "piece of cake" in the sqm and cake is using the default triple isolate.
My question is, is this setup seeing my internal ip's and doing per ip sharing? Or is using an interface for cake that is part of a bridge the wrong thing to do?
If the box cake runs on does not actually perform NAT for your network (and your network actually requires NAT, for all I know you might have enough IPv4 addresses to supply to your 600 customers) then I predict that you only get per-flow fairness, that is cake will try to treat each flow equally.
However in your setup all internal address are fully visible to cake and NAT would only change the internal address, so cake should have the necessary information to perform per internal IP fairness.
You should be able to test this by running a few flows on one of your internal hosts and many flows on another one (obviously the flows need to cross the cake box and should terminate in the wider internet to test the NAT issue). If both machines get roughly equal accumulative bandwidth then this indicates per IP fairness, if the bandwidth is distributed according to the ratio of few to many you have simple per-flow fairness. Please note that per-flow fairness is not too bad, and that you might want to use the dual-srchost and dual-dsthost options as triple-isolate does not guarantee strict per-internal-IP fairness. With the dual options you need dual-scrhost on the interface that handles the internet upload traffic and dual-dsthost on the interface that handles the internet download traffic.
A more interesting question will be how cake's inbuilt number of hash bins (see #define CAKE_QUEUES (1024) in sch_cake.c) will be sofficient for 600 connected machines. You might want to compile/bake your own cake module with more cake_queues (I would recommend you bring your questions to the cake mailing list (https://lists.bufferbloat.net/listinfo/cake), where Jonathan Morton, cake's principle author has a chance to chime in)
You can you please share with us more details about your configuration? What device do you use as "transparent cake box", how fast is your internet speed if dnsmasq and firewall is disabled then what device is doing them? Can you maybe post here your configuration files that would show us how did you manage to configure the "cake box" or you can PM me if you'd like that.
I'm asking because I'm thinking about doing something similar but I'm not sure exactly how to do it to fully use all the features that cake provides.
I am personally looking forward to see the result of this test since I'm thinking about doing a similar or the same setup.
Yes, but doesn't the cake box see all the internal IPs since all the traffic is coming though it?
The box is a dual core pentium with 4gb ram running an x86 64 build of lede. It has 2 intel gigabit nics both bridged together and one relatek onboard nic in dhcp client mode for management purposes. The config was done purely through the Luci interface and i just disabled dnsmasq and firewall on startup. The internet connection is 300/100 dedicated fiber. During peak, all 300mbits are being used and cpu usage is around 1% from what i can tell. Its very very low. The 600 customers are actually 600 standard home routers. The customers are going through the cake box to get to the nat gateway and the customers share 1 external ip address. Today i will recompile lede with a bigger number of hash bins for cake. Does anyone know what sting i should be using in the advanced settings for dual-srchost and dual-dsthost options?
Interesting, with that setup you could forgo the ifb-based ingress shaping and shape on the egress interface of both intel nics, which might save around 5% overhead (very rough number). I would try to instantiate the shapers on the physical interfaces instead on the bridged interface. And then test whether this actually works as intended?
I actually have it applied to the physical interface. Having it applied to the bridge interface didn't work at all. Also, applying to the egress of each interface works, i just wasnt sure about the ip visibility but in theory it should see them from either interface.
I just recompiled lede with #define CAKE_QUEUES (65535) Anything higher than 65535 cause lede to crash on bootup. I will also begin testing a duplicate box with a few machines to confirm sharing is working.
Ah, great that it works. As far as I can tell the larger CAKE_QUEUES gets the less cache friendly cake behaves, so maybe you should test a few sizes to figure out how many parallel flows you actually ever encounter and only set the the closest power of two? Cake uses, IIRC a set assoziative hash list, so that it will avoid false sharing unless unavoidable so cake probably gets away with fewer CAKE_QUEUES than fq_codel would.
My problem with installing a cake box between my router and clients is that the router is a Peplink that aggregates. There are 4 WANs attached to the Peplink of 10 mbps each. As a result putting a cake box where you do puts it on the "fat pipe" that is, in practice, about 37-38 mbps download and about 2.5 mbps upload. The bufferbloat occurs on each of the WANs so a cake box where you have it doesn't work: really needs to be at the other end...between the transparent bridged modems and the Peplink. So a cake box appears needed for each of the WANs in the Peplink. So far I have had difficulties in getting strong DNS when I put cake boxes between the bridged modems and the Peplink.
Hi all,
I'm in a similar situation: I'd like to put a transparent instance at the office between the lan's interface of our gateway router and the main switch. The router is doing nat and is the only one in our network.
I'd like to know if it's possible to have per-host fairness and how to do it.
I've already prepared a test box configured as following:
wlan as control interface
2 unmanaged interfaces eth0.1 eth0.2 bridged together
this is an old wap with no separate interfaces for wan and lan, so I'm using vlans, could this be a problem?
At that point incoming packets already use the internal IP address as dst and outgoing use the internal IPs as src, so per-internal-IP fairness should work. So pick the VLAN that connects to the router and create an sqm instance for it and then add: the following to your /etc/config/sqm (and then restart sqm)
option iqdisc_opts 'dual-dsthost'
option eqdisc_opts 'dual-srchost'
That should give you IPv4 internal-host fairness (IPv6 will also work correctly). Now, I do not know how this will interact with a bridge, and it might be a good idea to set the ingress bandwidth on the WAN-VLAN to zero and instantiate another sqm-instance on LAN-VLAN where you only configure egress (but since LAN egress + internet ingress that will work fine), only then just add:
option eqdisc_opts 'dual-srchost'
to WAN-VLAN and:
option eqdisc_opts 'dual-dsthost'
to LAN-VLAN (please note here it is dual-dsthost, not dual-srchost). Make sure to properly test all of this, I am certain that I am overlooking things here and stuff might break/misbehave...
It works, indeed it works very well!!
I tried the simple setup with only one cake instance on the wan interface and I'm surprised what a cheap box can do thanks to the work of some clever developers
The change looks nice, but I believe yu still need to test whether the per-interanal-IP fairness actually works..., try running flent from multiple internal hosts against an external one, and use rrul_cs8 to get a test that uses 8 flows per direction, in the end the total bandwidth of the ruul host and the rrul_cs8 host need to be somewhat equal...
But nice that it works, btw could you post the result of "tc -s qdisc" from your shaper appliance, please?
Hi moeller0,
my colleagues mostly use Windows pc so I'm not able to run multiple flent test at the same time. Maybe I can deploy some virtual machines, but it would take some time to organize the test because I can play only in the late afternoon when everyone else is gone.
I'm not sure the charts are showing the right numbers, we have a 20/20 fiber link and usually I see ~20ms ping, so I need to re-check also these results.
Now I'm home and can't connect to the appliance (our VPN doesn't route wifi signals ) but I will post it tomorrow from the office.
That looks good. I guess the only obvious improvement would be to specify the correct per-packet-overhead, which for fiber links unfortunately is somewhat hard to get right... (that and testing whether internal host isolation works*)
*) you do not actually need to run flent on multiple internal hosts; as long as you have one flent-capable host simply use the dslreports speedtest (configured for multiple streams on the windows hosts, make sure to extend the test duration to 30 seconds or more). Then expect the flent measured throughput to scale back to the (1/concurrently active hosts) fraction whenever the windows hosts have their speedtests running. BTW https://www.dslreports.com/forum/speedtestbinary gives command line clients for the dslreports speedtest, making testing a bit simpler.
This is the most important one as this sort of summarizes how you ended up configuring cake. Since it says "raw" instead of "overhead NN" I believe that you did not configure the per packet overhead explicitly and hence mentioned it.
The fact that there were drops tells me the shaper is doing its job...
AFAIK, this shows the peak delay cake induced, it looks quite nice.
This tells me only very few of your data flows use ECN, as otherwise there would be less drops and more marks.
And this shows that you do not suffer from large meta-packages (from GRO or GSO) as otherwise max_len would be larger, 1514 is typical for MTU 1500 packets as the linuk kernel skb structure will add the size of the ethetype and the two ethernet MAC addresses (the kernel fills these fields and hence 1514 is true from the kernel's perspective, even though it is not really suitable for any shaper).


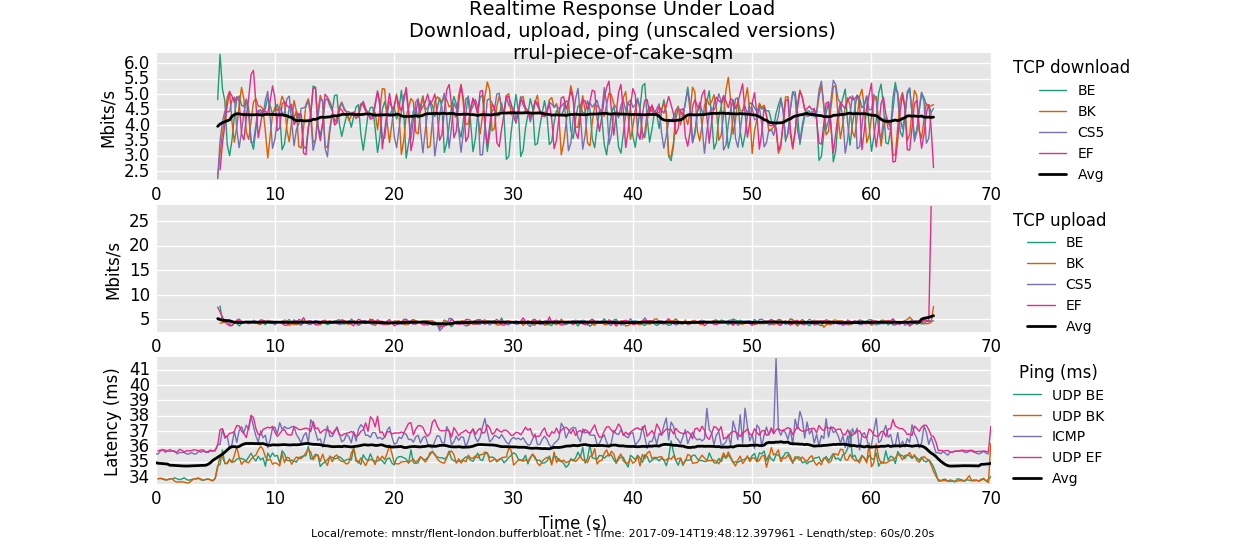
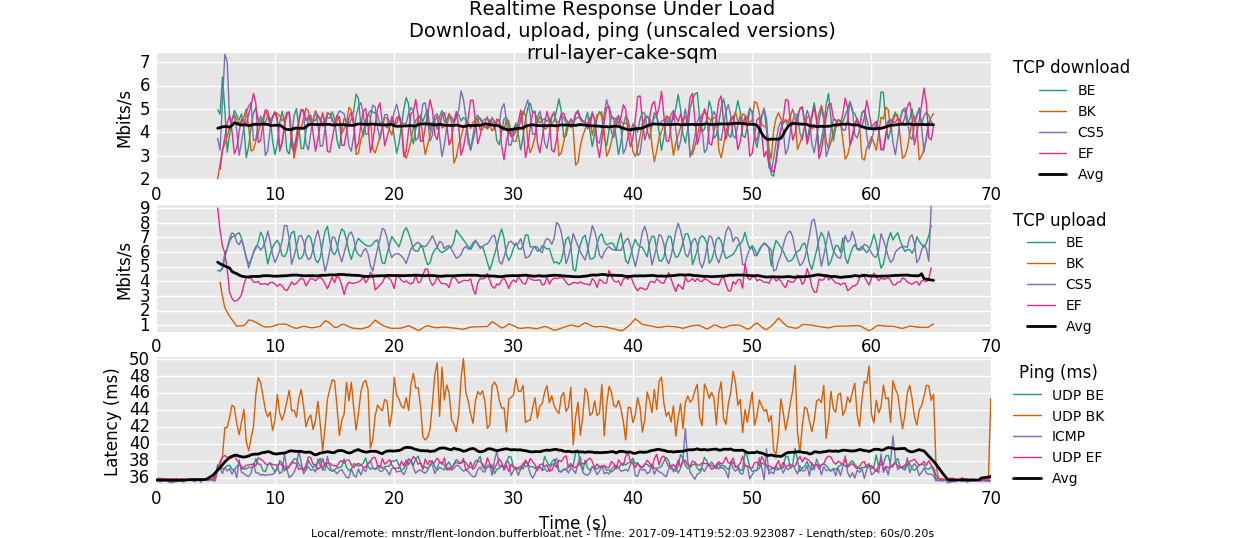
 ) but I will post it tomorrow from the office.
) but I will post it tomorrow from the office.