Well since afpacket doesn't work probably not the problem is that the queue is limited but I don't know what I suspect an internal kernel limit or a bug. Can you post the performance with only one connection or queue?
That is clear that with the flush command you have probably deleted the queue. I reach up to 75 Mbit max usually around the 60 since the difference between us is so large that indicates a Cpu limit does not surprise me. see if the performance goes up if you reduce the rule set many rules are unnecessary since intended for servers.
Yes, that two-chain ruleset is correct (you can delete those "meta l4proto" comment lines, they were just an experiment that was resolved with the "4-6" syntax). See also the hidden section "inet snort table with three chains" in 16, above.
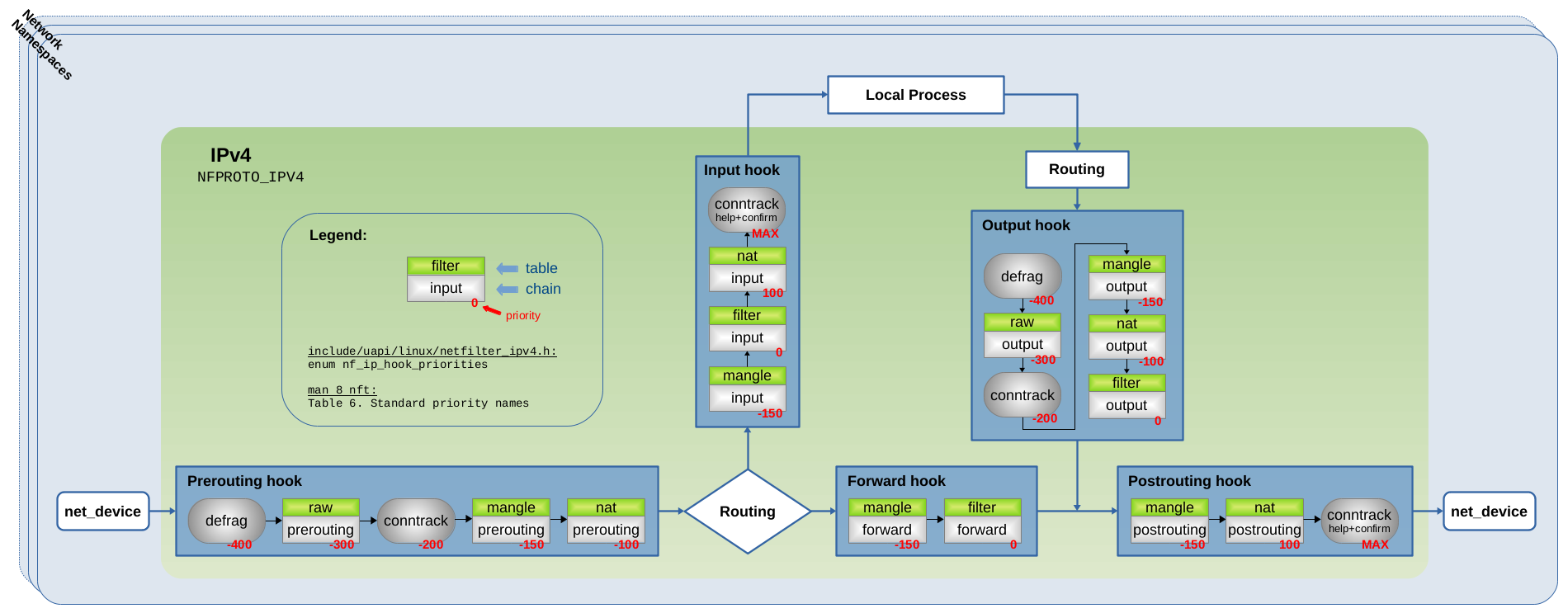
I'm not looking at speed yet, as I'm still trying to fully understand where I can intercept all packets that originate from, destined for or pass through the router. From this excellent set of articles I read last fall, it looks like the only reliable hook is postrouting, as prerouting misses local processes (e.g., ping from router) and other hooks depend on routing decision. I'm still trying to figure out whether it makes more sense to check before or after the nat priority.
Well there is another way to create a queue with Conntrackd https://conntrack-tools.netfilter.org/manual.html under user space helpers. But I have no idea how and if this works my attempts failed because of some syntax errors.
The local queue is also not recommended, but the chain with the hook output performed a bit better than the one with the hook input.
Hanging the queue on the postrouting hook works but the performance drops compared to the forward hook. What also influences the performance is the --daq-var fanout_type=hash parameter.
I haven't tried the conntrack queues yet, but I did try an nft netdev table with an ingress hook, but it caused a kernel crash when snort started. Apparently don't do that!
My philosophy for "make sure it works first" has meant to me that all data paths should be processed by the snort rules (i.e., everything that passes between any of router, WAN and LAN in any direction). My assumption is that if an attacker compromises your router, then snort should try to scan the router->somewhere packets. I'm not sure that's a productive avenue to follow; we assume that the router is not going to be compromised for the most part (see recent forum post on SE Linux), so maybe that's the direction I should follow here.
If I discard my requirement that packets originating from the router itself be processed, then the obvious chain to use would be raw prerouting, as that precedes everything but defrag and hence should produce the best performance.
Side note: you should all change "flush table" to "delete table" in the setup script, as "flush" doesn't delete the chains and if you change it's hook, you'll get errors.
Exactly that was also my thought that's why I tried the prerouting hook but it didn't work but if I look at it it might work if we specify it more on raw prerouting. I'll see if I can make it work the nice thing is we only need to delete and recreate the rules without restarting snort that saves time.
//edit/ I have tested it again with prerouting the performance does not go over 50Mbit. So it remains the fastest is the forward hook the safest the postrouting hook everything else brings unacceptable performence.
//edit2/ It seems that with the Nfq Daq it is better to turn on gro and tso, only lro (software flow offloading) must remain off.
Yes that is clear. The Postrouting hook snort queue works with activated Generic Receive offload and tcp-segmentation-offload much faster I reach now with a single connection now almost my full bandwidth of 100 Mbit and the problems why the options should be disabled should not exist with Nfq because that works differently than afpacket what the article referred to then.
But better test also with activated reputation blacklist if the drop works correctly with Http/Https.
I have tested again something the fastest configuration is the postrouting hook with a priority of 300 there snort behaves as if it were bound with pcap to the Wan device, but is able to block on the idea I came after I have read here https://wiki.nftables.org/wiki-nftables/index.php/Netfilter_hooks#Priority_within_hook that the connection tracking helper work there. The WanDevice should be specified in the Snort.conf ( variables = { 'device=eth0' }, ) otherwise I could observe in my tests the strange behavior that one device was blocked on another but not or only partially blocked. Here is the modified queue script:
#!/bin/sh
verbose=false
nft list tables | grep -q 'snort' && nft flush table inet snort
nft -f - <<TABLE
table inet snort {
chain IPS {
type filter hook postrouting priority 300; policy accept;
ct state invalid drop;
# Add here accept or drop rules to bypass snort or drop traffic that snort not should see
# Note that if nat is enabled, snort will only see the address of the outgoing device for outgoing traffic,
# for example for wan port the wan ip address or if you are using vpn the device address of the virtual adapter
counter queue flags bypass to 4-6
}
}
TABLE
$verbose && nft list table inet snort
exit 0
I have slightly revised the script again the snaplen should be better 65531
Are you guys still testing setups? I am happy to test out some stuff when ready.
@xxxx - I tested your script one post above using the following. I got 165 Mbps download where running without snort is 950-1000 Mbps. Do I need to run any ethtool tweaks or modify anything?
My WAN NIC is eth1 by the way.
# ethtool -k eth1 | grep receive-offload
generic-receive-offload: on
large-receive-offload: off [fixed]
Activate for both network ports (wan, lan) also tso: ethtool -K eth0 (1) gro on tso on and change the s parameter (snaplen) from 64000 to 65531. But I'm afraid your Cpu is too weak for much more throughput I could increase the throughput on one queue also only about 25 percent this way.
No I don't test anymore it doesn't make sense to put the queue somewhere else because the performance is worse I have done all reasonable configurations what makes sense for example to exclude the vpn traffic by accept rule before the queue or the traffic if you have different internal networks (snort also controls the traffic between the internal networks). But these are adjustments that everyone must perform for themselves.
//edit I'm not sure if your file_policy option makes sense since Snort only says yes or no to the passing traffic and can't manipulate anything itself.
I am getting my full download bandwidth of around 650-700 Mbps. The CPU is a quad core and one of them hits >99% during the download test (other 3 are 30-40%).
So this is a win!
Next question is how to adjust the snort3 package config files to mimic this without the command line.