Netserver should be able to drive the network harder than that. A rrul test on apu2 class hardware should be able to crack 500Mbits over ethernet. (low latency at the cost of this much bandwidth seems odd)
Are you using BBR?
Netserver should be able to drive the network harder than that. A rrul test on apu2 class hardware should be able to crack 500Mbits over ethernet. (low latency at the cost of this much bandwidth seems odd)
Are you using BBR?
No, I don't use BBR. I have to check if Fedora (installed on my laptop) sets any fancy networking options, but I doubt that.
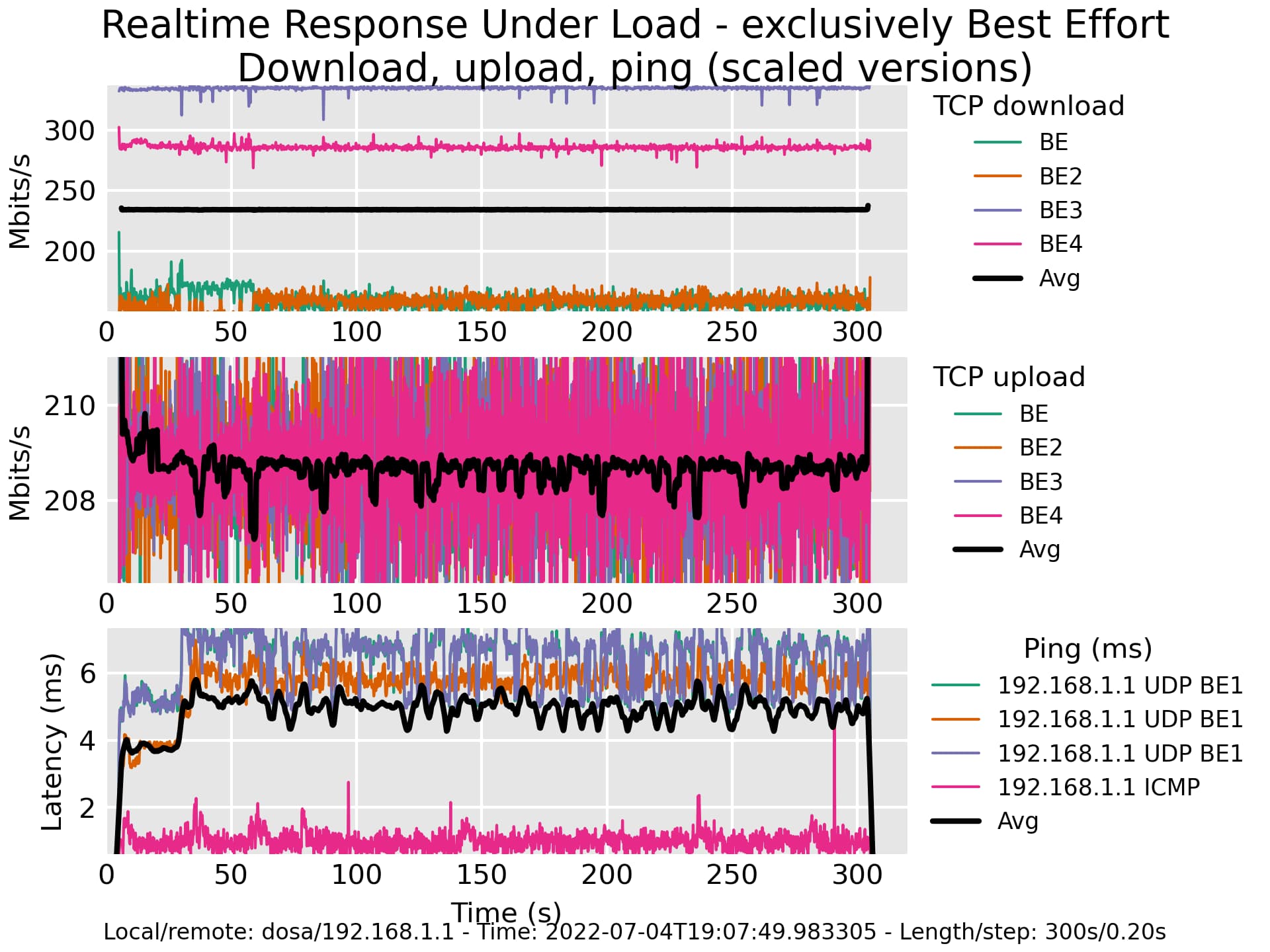
Here is a flent plot of a run via ethernet:
This also shows a big difference between flows. But since this doesn't seem to be related to wifi, should I open another thread? This one is already huge...
Heh. Just having baseline performance figures for this hardware also on this thread would be good, so no need to fork it. You've now shown that this device could - if it was working right - drive the wifi to saturation well past 40Mbit - well past 200Mbit and it isn't, due to yet some other problem we have not found yet. On some other bug thread here are people reporting problems with "ax" mode, try ac?
On the ethernet front...
My guess is that the APU2 has 4 hardware queues and you don't have irqbalance installed. (a "tc -s show dev the_lan_network_device" would show mq + 4 instances of fq_codel). In this test two flows landed in one hardware queue, another ended up well mapped to the right cpu, the other less so. tc -s qdisc show on your fedora box will probably also so mqs + fq_codel
A test of the lan ethernet device with just fq_codel on it (tc replace dev the_lan_device) will probably show the downloads achieving parity between each other but not a full gbit.
The icmp induced latency looks to be about right (it's usually ~500us) the induced udp latency of > 5ms surprisingly high. I'd suspect TSO/GRO. Trying cake on the lan interface (without mq but with the gso-split option) - would probably cut that (due to cutting BQL size). There are numerous other subsystems in play like TSQ.
Trying 4 instances of cake with gso-split on mq would also be intersting.
The world keeps bulking up things on us. So much of linux's development is on really high end boxes and some recent modifications like running more of the stack on rx looked good on machines with large caches but I suspect hurt on everything else.
What does openwrt use for RT_PREEMPT and clock ticks these days?
Interesting may be:
https://git.kernel.org/pub/scm/linux/kernel/git/netdev/net-next.git/commit/?id=6fcc06205c15bf1bb90896efdf5967028c154aba
and
https://lwn.net/Articles/883713/
I apply patch:
--- a/drivers/net/wireless/ath/ath10k/mac.c
+++ b/drivers/net/wireless/ath/ath10k/mac.c
@@ -4764,7 +4764,6 @@ static void ath10k_mac_op_wake_tx_queue(struct ieee80211_hw *hw,
struct ieee80211_txq *txq)
{
struct ath10k *ar = hw->priv;
- int ret;
u8 ac;
ath10k_htt_tx_txq_update(hw, txq);
@@ -4777,11 +4776,9 @@ static void ath10k_mac_op_wake_tx_queue(struct ieee80211_hw *hw,
if (!txq)
goto out;
- while (ath10k_mac_tx_can_push(hw, txq)) {
- ret = ath10k_mac_tx_push_txq(hw, txq);
- if (ret < 0)
- break;
- }
+ if (ath10k_mac_tx_can_push(hw, txq))
+ ath10k_mac_tx_push_txq(hw, txq);
+
ieee80211_return_txq(hw, txq, false);
ath10k_htt_tx_txq_update(hw, txq);
and mayble is better- I not visible bug in log ath10k_ahb a000000.wifi: failed to lookup txq for peer_id X tid X until about 24h used (max 7 clients and internet connection with maximum load). Connect in 10 meters test room is better ( now is about 15-20Mbits; without patch was about 2Mbits and somtimes 12-15)...
How long tests will are good? I no know yet ![]()
we won't be ready for BIG tcp for a few more years. Certainly I can see the core google devs not testing anything on weak hw.
You are about the only person I know that can offer reasonably near-by RTT/OWD reflectors independent on whom from where ever asks ![]() Just waiting for mcmurdo.starlink.taht.net to come on-line
Just waiting for mcmurdo.starlink.taht.net to come on-line ![]()
Sorry, I should have made my homework...
irqbalance was installed but not enabled (something I regularly forget on new OpenWrt installs). With irqbalance and just cake on eth1+2, latency indeed looks great:
So back to the EAP245v3. It only supports 802.11ac, the previous plot was ac as well. It's still slow, but at least it looks less chaotic.
I don't know what happened after 250s, I had to reconect, but dmesg on the ap didn't reveal anything. This was right after a reboot. I'll test again after a few hours/days uptime, since wifi tends to get worse after a few days.
As it has been many months of effort for all concerned here, I am in search long term stability first, regaining performance later. How many other simultaneous bugs do we still have? mt76 still has a range problem at 2.4ghz, there's other ath10k chipsets to try (are you using -ct, stock, -ct-smallbuffers?), nobody's tested the ath9k lately, qosify vs wifi of any sort, the "
iphone leaving the network" problem, and I forget what else.
More https://en.wikipedia.org/wiki/Six_Sigma
Less agile.
If we can get down to where all that stuff goes away, my original goal this quarter was to find more ways of making wifi more capable of twitch and cloud gaming! There's a bunch of easy stuff along that road that I'd have hoped to have tried by now, but setting the bar right now at "not crashing", at "not doing weird stuff over long intervals", and getting confirmation from everyone testing that that's the results we're getting across more chipsets will make for a MUCH better next openwrt release, which I'd settle for!
Anyway your wifi result is very good. The latency inflation you see is typical of the codel settings (target 20ms), and number of txops (2 each way, max 5.7ms) we currently use. (I would like to reduce these in the future) It does seem to be quite a lot less than what ac is capable of, and the upload especially seems low. I don't know anything about the driver for that chipset.
One thing to explore is to try and figure out if it is the rate controller or some form of starvation that is limiting your bandwidth. (from your results above it "feels" like the rate controller) Doing an aircap during a short test can pull out what the advertised rates and typical transmissions actually are, google for "aircap tshark". I don't remember enough about how to get at ath10k rate controller stats from the chip, or even if that's possible. @nbd? @tohojo?
Another simpler test is to just test downloads and uploads separately.
flent -H APU -t the_test_conditions --step-size=.05 --te=download_streams=4 --socket-stats tcp_ndown
flent -H APU -t the_test_conditions --step-size=.05 --te=upload_streams=4 --socket-stats tcp_nup
Another is setting the range of rates manually.
Also if -l 300 is reliably cutting off after 250s that is either a flent bug, or a wifi bug! I can think of a multiplicity of causes for that - a dhcp renew failure, an overflow bug somewhere in the DRR implementation, if it's repeatable that would be weirdly comforting. If it were tied to the rate being achieved (say we got twice the throughput by testing tcp_ndown, and it crashes in half the time), that would also be "better".
-l 600, maybe. I'd be really happy if folk ran the rrul_be, rrul, and rtt_fair tests for days and days at a time (I think the upper limit is about 2000s per test). Six Sigma... one of the nice things about fq_codel derived solutions is that - when it's working right - you hardly notice when something else is saturating the system.
Going back to your excellent cake result, showing this hardware is suitable as a simpler test driver for wifi also...
x86 hardware and perhaps some new stuff like the R5S are the first things that I might recommend cake nat gso-split ran natively on, instead of defaulting to fq_codel. can you post the output of "tc -s qdisc show > /tmp/rrul_be_cake.stats" halfway through running this test?
capturing the bql stats would also be useful also in the middle of a test run.
cat /sys/class/net/eth*/queues/tx-*/byte_queue_limits/limit > /tmp/bql.stats
Not to rant, but the 1.5ms observed on this better test, is around 25x more than what is actually feasible for forwarding behavior under this workload. Each full size packet consumes about 13us on the wire (there's 4, so 52us), the acks 1us, the pings about the same.
Not happy with the periodic spike above 1.5ms either! Don't know where that is coming from. PREEMPT_RT might help.
In a more ideal universe we'd be finding ways to tune NAPI down, have ddpk as an option, and offloads for more stuff and be shooting for sub 250us induced latency and it would behave consistently like a "fluid model", but a "mere" 1.5ms latency inflation at 1gbit is remarkably good for current hw. Getting to sub-250us would make for a "tighter" interface to wifi which cannot do much better than than that.
PS, you get wider, more detailed plots, if you use symbolic names like APU rather than 192.168.1.1. Stick in your /etc/hosts file
192.168.1.1 APU
I also tend to do the same thing for the whatever.starlink.taht.net cloud, and/or add starlink.taht.net to my /etc/resolv.conf file
Regarding the sub thread about flent on macos, the ever amazing @tohojo just fixed some annoying issues that existed between recent flent and macos monterey/python3.9.
Your enthusiasm for this topic is truly contagious - thank you so much for your insights and for dedicating so much time to the users here!
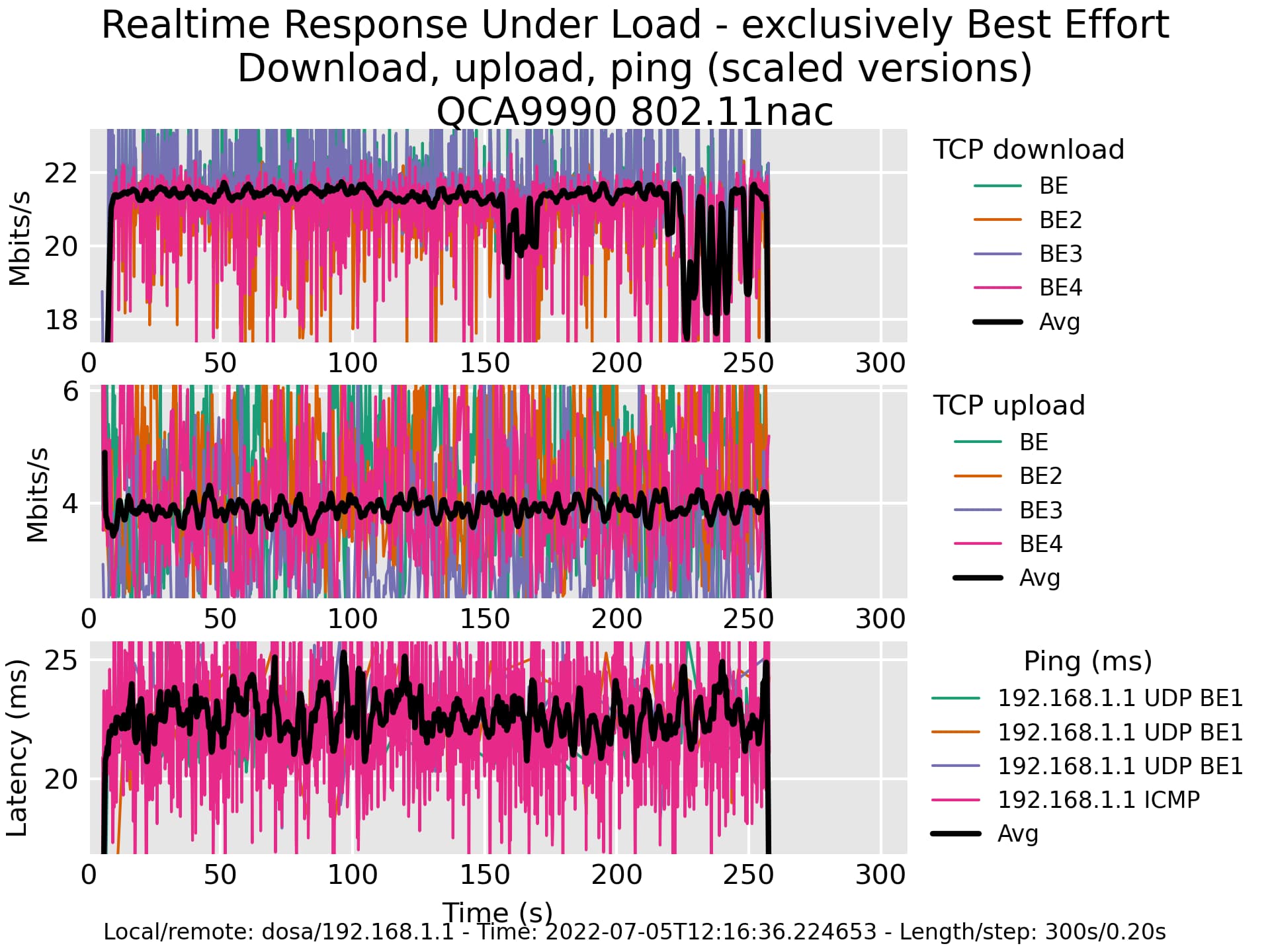
Here are the wifi up-/download results, I'll add the cake stats tomorrow.
Summary of tcp_ndown test run from 2022-07-05 20:58:56.825608
Title: 'QCA9990 802.11nac'
avg median # data pts
Ping (ms) ICMP : 21.30 20.60 ms 1399
TCP download avg : 22.05 N/A Mbits/s 1399
TCP download sum : 88.20 N/A Mbits/s 1399
TCP download::1 : 20.05 21.30 Mbits/s 1399
TCP download::2 : 21.22 21.65 Mbits/s 1399
TCP download::3 : 23.44 22.86 Mbits/s 1399
TCP download::4 : 23.49 22.94 Mbits/s 1399
Summary of tcp_nup test run from 2022-07-05 21:00:28.855437
Title: 'QCA9990 802.11nac'
avg median # data pts
Ping (ms) ICMP : 3.77 2.96 ms 1317
TCP upload avg : 13.99 N/A Mbits/s 1399
TCP upload sum : 55.98 N/A Mbits/s 1399
TCP upload::1 : 14.03 14.63 Mbits/s 1399
TCP upload::1::tcp_cwnd : 6.36 6.00 963
TCP upload::1::tcp_delivery_rate : 14.17 12.72 963
TCP upload::1::tcp_pacing_rate : 22.19 21.22 963
TCP upload::1::tcp_rtt : 4.37 4.30 959
TCP upload::1::tcp_rtt_var : 1.04 0.88 959
TCP upload::2 : 14.00 14.22 Mbits/s 1399
TCP upload::2::tcp_cwnd : 6.26 6.00 963
TCP upload::2::tcp_delivery_rate : 14.25 13.30 963
TCP upload::2::tcp_pacing_rate : 22.09 20.91 963
TCP upload::2::tcp_rtt : 4.36 4.29 961
TCP upload::2::tcp_rtt_var : 1.04 0.90 961
TCP upload::3 : 14.26 14.62 Mbits/s 1399
TCP upload::3::tcp_cwnd : 6.46 6.00 963
TCP upload::3::tcp_delivery_rate : 14.46 13.40 963
TCP upload::3::tcp_pacing_rate : 22.75 21.56 963
TCP upload::3::tcp_rtt : 4.35 4.28 959
TCP upload::3::tcp_rtt_var : 1.03 0.89 959
TCP upload::4 : 13.69 14.22 Mbits/s 1399
TCP upload::4::tcp_cwnd : 6.28 6.00 963
TCP upload::4::tcp_delivery_rate : 14.07 13.07 963
TCP upload::4::tcp_pacing_rate : 22.19 21.00 963
TCP upload::4::tcp_rtt : 4.35 4.28 961
TCP upload::4::tcp_rtt_var : 1.04 0.90 961
what is your HT setting in /etc/config/wireless?
grep -i HT /etc/config/wireless
Speed in test room is yet fine (15-24Mbps of speedtest.net and 30-35Mbps with iperf; pings are about 25-28ms- but sometimes jumps) and is without a visible bugs about 3 days uptime (correct 2 days and 18 hours). I will apply another patch for testing in the evening.
It's 'VHT80'
I'm using the default ath10k-ct driver, I didn't mention that, yet.
oh, good, I thought people had given up on -ct. -ct has multiple other benefits, notably adhoc mode, and until these past few months seemed superior in every way to the stock driver.
@dtaht +1 I just want to call this out as an incredibly important goal. It doesn't matter how fast the links speeds are/how low the latency is: if the code ever does weird stuff, then whatever change you've introduced doesn't matter. Thanks.
OK I did another run via ethernet and captured the requested stats (sorry, took a bit longer - busy week...)
rrul_be_cake.stats
qdisc cake 8113: root refcnt 9 bandwidth unlimited diffserv4 triple-isolate nat wash no-ack-filter split-gso rtt 100ms noatm overhead 38 mpu 84
Sent 166414637654 bytes 118049788 pkt (dropped 153, overlimits 0 requeues 2108890)
backlog 331320b 220p requeues 2108890
memory used: 1123936b of 15140Kb
capacity estimate: 0bit
min/max network layer size: 28 / 1500
min/max overhead-adjusted size: 84 / 1538
average network hdr offset: 14
Bulk Best Effort Video Voice
thresh 0bit 0bit 0bit 0bit
target 5ms 5ms 5ms 5ms
interval 100ms 100ms 100ms 100ms
pk_delay 0us 3.86ms 703us 248us
av_delay 0us 2.23ms 127us 17us
sp_delay 0us 381us 15us 8us
backlog 0b 328308b 0b 0b
pkts 0 118018426 1903 29830
bytes 0 166413617361 255690 1306945
way_inds 0 168139 0 0
way_miss 0 13893 8 11
way_cols 0 0 0 0
drops 0 153 0 0
marks 0 0 0 0
ack_drop 0 0 0 0
sp_flows 0 8 1 1
bk_flows 0 4 0 0
un_flows 0 0 0 0
max_len 0 68130 5724 345
quantum 1514 1514 1514 1514
bql.stats
0
1573
2499
1952
1863
0
0
4702
4690
6024
10800
774
63315
120652
75363
Thank you for doing that, at that level of detail. BQL is bouncing around a lot more than I would like under the circumstances of this test, and the sparse cake stat is being smoothed too much by the ewma in it (of the cake stats for "latency" that's the most important IMHO), but that's a clear example of averages being misleading. (and downright dangerous when it comes to realtime data: https://www.thestar.com/news/insight/2016/01/16/when-us-air-force-discovered-the-flaw-of-averages.html )
There may be ways to control that better (in your prior post there is a clear 60s perodicity coming from somewhere), locking the test tool or cake to a smaller cpu set, or using a less memory or cpu intensive algo like fq-codel instead, unbatching gso (splitting) is costly too, but speculation as to the causes is never as good as an oprofile (perf nowadays) and flame graph. If somehow I could get more engineering mgmt focused on ripping more sources of latency out of the stack, and aiming for the 25x reduction I mentioned it would be great. ![]() Attempting a NAPI value of 32 - even 16! rather than the default of 64 hasn't been tried by anyone lately, if folk want to try that.
Attempting a NAPI value of 32 - even 16! rather than the default of 64 hasn't been tried by anyone lately, if folk want to try that.
... anyway the noise introduced here by running the test tool on an APU2 router is almost low enough to rule out a fateful interaction with how we batch packets up for wifi (but see this: https://lwn.net/Articles/757643/ it would be hilarious if that patch was missing or off by one) and I'm strongly inclined to point at your throughput limitation as caused by something else. An aircap would be revealing.