OK, that's puzzling. The odds were good that we'd see a third tier hash collission here, and we don't, and the bimodal distribution is odd... way too many flows in this other tier to be a birthday paradox at flows 1024.
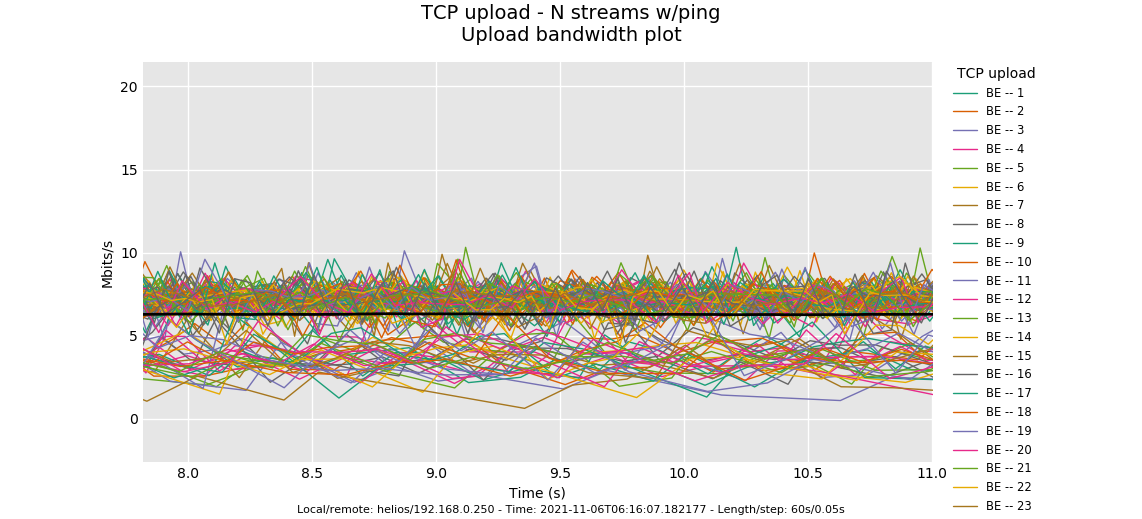
And that's And codel, should have controlled all the RTTs here despite the collision - throughput should have been different but observed latencies eventually the same.
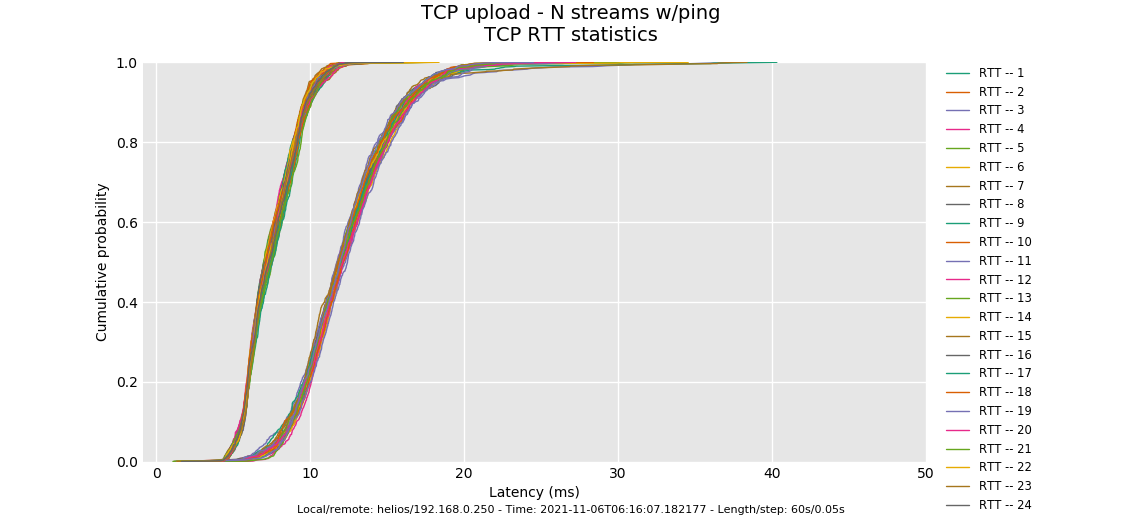
Do you know what the default is for the flows parameter? To see if this distribution moves around any try flows 16.
You can also try knocking the burst parameter down to about 32k. The autoscaling stuff we did there was designed for a software implementation of htb.