My ISP provides 1 gigabit downstream. Using a RPi4 to run SQM, I am finding that with either cake/piece_of_cake or fq_codel/simplest_tbf or fq_codel/simplest (750000 down and 22000 up), the best downstream I can achieve is around 565 Mbps. Watching htop on the RPi4, I see core0 is consistently loaded >99%. I read about the RPi4 being able to shape gigalan symmetrical connections so am wondering why mine is falling short.
Can someone with a fast connection and a RPi4 confirm the claim?
I am using DSA to run two VLANs on this RPi4, so perhaps that is limiting me assuming others with the hardware/connection and confirm better downstream speeds.
EDIT: For this entire thread with the exception of the final post, I believe I had the SQM target on a bridged interface rather than on the physical one. Putting it on the physical one gave the lowest CPU usage so keep that in mind when reading everything else in the thread.
I had irqbalance installed and active when I tested. Also had packet steering enabled. I can run a test again disabling it and see if it makes a difference. Key is SQM is single threaded though.
Hi, I can confirm it works. Connecting my computer directly to the RPi4 I can max out my gigabit connection and my upload bandwidth. My ISP's provided connection is 1000/50.
Yes, it uses kmod-usb-net-asix-ax88179. I did a test with iperf3 (no SQM) and found that this adapter is as fast as the internal NIC on the RPi4. I do not think it is to blame.
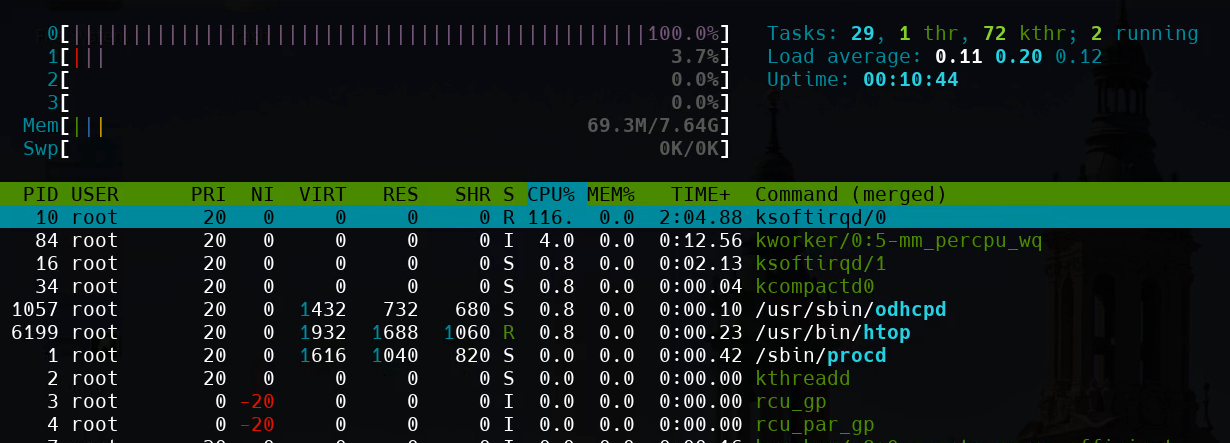
The test for bufferbloat does download first, then upload. The key I am seeing is single core saturation which I believe is limiting the speed achieved.
Can you share your SQM settings with me? How about your network setup? Are you using VLANs? Thanks!
Well, look at the load on the CPU during such a test... Regarding htop:
"Pressing F1 in htop, shows the color legend for the CPU bars, and F2 Setup → Display options → Detailed CPU time (System/IO-Wait/Hard-IRQ/Soft-IRQ/Steal/Guest), allows to enable the display of the important (for network loads) Soft-IRQ category."
I would not be amazed if the USB dongle by itself causes a noticeable CPU load, and addong SQM then drives the COU into overload...
Yes, I just finished swapping. It's about 8% faster but still about 1/2 what it should be.
Original setup:
WAN = eth1 (USB)
LAN = eth0 (internal)
Average download with SQM = 568 (580,561,562 ran 3x)
Average download without SQM = 907 (908,906 ran 2x)
Reversed setup:
WAN = eth0 (internal)
LAN = eth1 (USB)
Average download with SQM = 615 (622,617,605 ran 3x)
Average download without SQM = 776 (797,754 ran 2x)
It might be due to the fact that I am using VLANs via DSA on this setup. I have to in order to maintain my two networks on the dumb AP (main and guest).
Someone over at the launch RPI4 thread had a similar issue with an asix based dongle. Up next they tried a rtl8153 based dongle, and they could do gigabit speeds in both directions with CPU cycles to spare.
The TPLink UE300 is rtl8153 based (uses kmod-usb-net-rtl8152), see if you can get that one.
See also my RPi4 performance thread, this is exactly the issue. The ASIX driver seems to do a LOT more interrupts than the Realtek, which probably aggregates them.