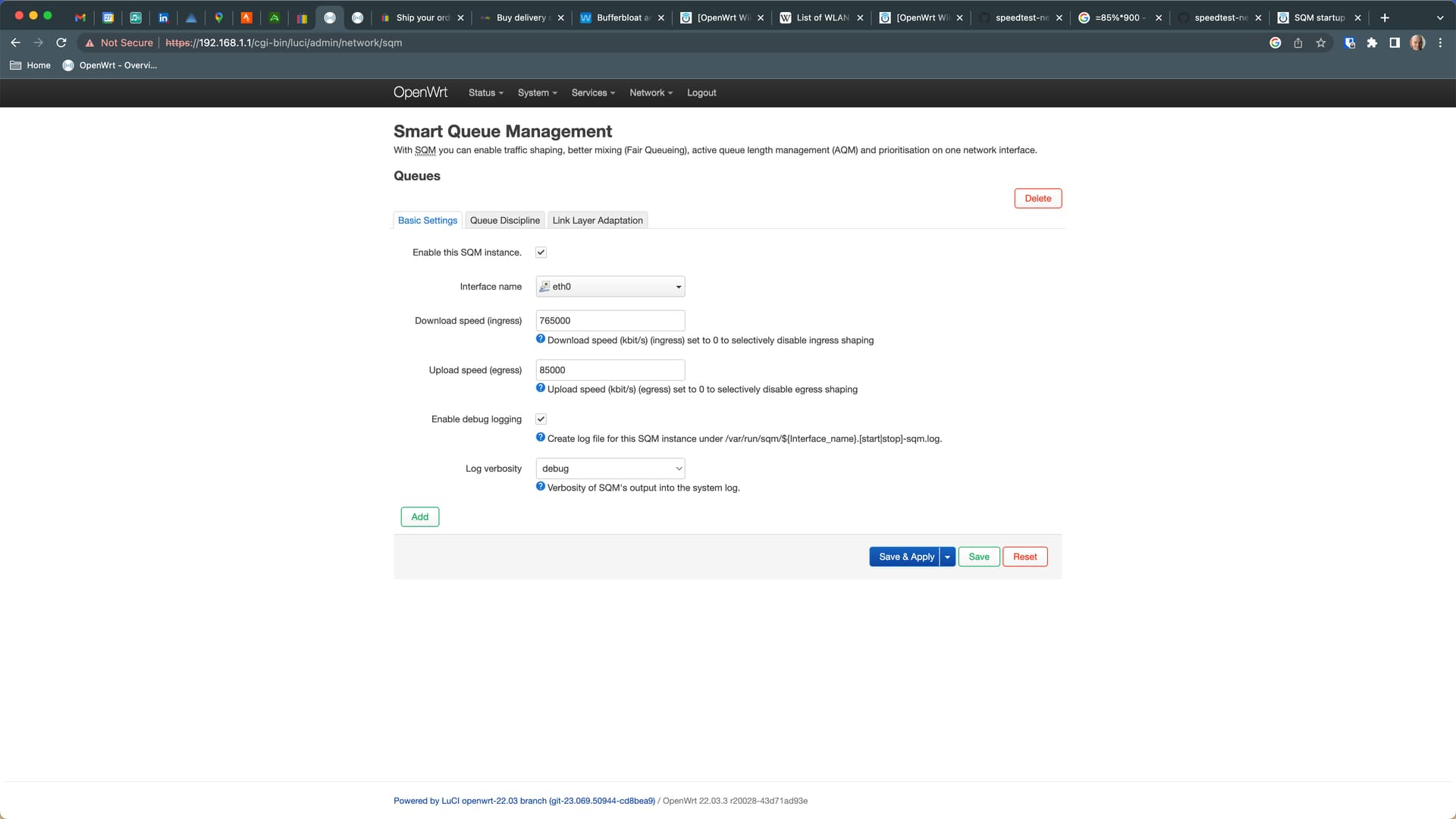
Hi, I'm getting several startup errors seen in the SQM log below. Are these anything to be concerned about please? Platform is Rpi 4, Internet is 900/100 BT UK Full Fibre to the Prem. Its shaped at 85% for testing as per the attached image and adaptation layer is set to 44 bytes.
Why do I ask? 1) I'd like to be sure its working as well as I can get it 2) I am seeing odd behaviours - speedtest.netperf.sh is showing a similar low latency with SQM turned on AND off, yet Waveform Speedtest from a macbook pro m2 cannot get A+ until I shape SQM to 65%)
start-sqm: Log for interface eth0: Thu Apr 27 09:58:49 UTC 2023
Thu Apr 27 09:58:49 UTC 2023: Starting.
Starting SQM script: piece_of_cake.qos on eth0, in: 765000 Kbps, out: 85000 Kbps
fn_exists: function candidate name: sqm_start
fn_exists: TYPE_OUTPUT: sqm_start: not found
fn_exists: return value: 1
Using generic sqm_start_default function.
fn_exists: function candidate name: sqm_prepare_script
fn_exists: TYPE_OUTPUT: sqm_prepare_script is a function
fn_exists: return value: 0
sqm_start_default: starting sqm_prepare_script
cmd_wrapper: COMMAND: /sbin/ip link add name SQM_IFB_dd205 type ifb
cmd_wrapper: ip: SUCCESS: /sbin/ip link add name SQM_IFB_dd205 type ifb
cmd_wrapper: COMMAND: /sbin/tc qdisc replace dev SQM_IFB_dd205 root cake
cmd_wrapper: tc: SUCCESS: /sbin/tc qdisc replace dev SQM_IFB_dd205 root cake
QDISC cake is useable.
cmd_wrapper: COMMAND: /sbin/ip link set dev SQM_IFB_dd205 down
cmd_wrapper: ip: SUCCESS: /sbin/ip link set dev SQM_IFB_dd205 down
cmd_wrapper: COMMAND: /sbin/ip link delete SQM_IFB_dd205 type ifb
cmd_wrapper: ip: SUCCESS: /sbin/ip link delete SQM_IFB_dd205 type ifb
cmd_wrapper: COMMAND: /sbin/ip link add name SQM_IFB_db42f type ifb
cmd_wrapper: ip: SUCCESS: /sbin/ip link add name SQM_IFB_db42f type ifb
cmd_wrapper: COMMAND: /sbin/tc qdisc replace dev SQM_IFB_db42f root cake
cmd_wrapper: tc: SUCCESS: /sbin/tc qdisc replace dev SQM_IFB_db42f root cake
QDISC cake is useable.
cmd_wrapper: COMMAND: /sbin/ip link set dev SQM_IFB_db42f down
cmd_wrapper: ip: SUCCESS: /sbin/ip link set dev SQM_IFB_db42f down
cmd_wrapper: COMMAND: /sbin/ip link delete SQM_IFB_db42f type ifb
cmd_wrapper: ip: SUCCESS: /sbin/ip link delete SQM_IFB_db42f type ifb
sqm_start_default: Starting piece_of_cake.qos
ifb associated with interface eth0:
Currently no ifb is associated with eth0, this is normal during starting of the sqm system.
cmd_wrapper: COMMAND: /sbin/ip link add name ifb4eth0 type ifb
cmd_wrapper: ip: SUCCESS: /sbin/ip link add name ifb4eth0 type ifb
fn_exists: function candidate name: egress
fn_exists: TYPE_OUTPUT: egress is a function
fn_exists: return value: 0
egress
cmd_wrapper: tc: invocation silenced by request, FAILURE either expected or acceptable.
cmd_wrapper: COMMAND: /sbin/tc qdisc del dev eth0 root
cmd_wrapper: tc: FAILURE (2): /sbin/tc qdisc del dev eth0 root
cmd_wrapper: tc: LAST ERROR: Error: Cannot delete qdisc with handle of zero.
LLA: default link layer adjustment method for cake is cake
cake link layer adjustments: overhead 44 mpu 0
cmd_wrapper: COMMAND: /sbin/tc qdisc add dev eth0 root cake bandwidth 85000kbit overhead 44 mpu 0 besteffort
cmd_wrapper: tc: SUCCESS: /sbin/tc qdisc add dev eth0 root cake bandwidth 85000kbit overhead 44 mpu 0 besteffort
sqm_start_default: egress shaping activated
cmd_wrapper: COMMAND: /sbin/ip link add name SQM_IFB_6e150 type ifb
cmd_wrapper: ip: SUCCESS: /sbin/ip link add name SQM_IFB_6e150 type ifb
cmd_wrapper: COMMAND: /sbin/tc qdisc replace dev SQM_IFB_6e150 ingress
cmd_wrapper: tc: SUCCESS: /sbin/tc qdisc replace dev SQM_IFB_6e150 ingress
QDISC ingress is useable.
cmd_wrapper: COMMAND: /sbin/ip link set dev SQM_IFB_6e150 down
cmd_wrapper: ip: SUCCESS: /sbin/ip link set dev SQM_IFB_6e150 down
cmd_wrapper: COMMAND: /sbin/ip link delete SQM_IFB_6e150 type ifb
cmd_wrapper: ip: SUCCESS: /sbin/ip link delete SQM_IFB_6e150 type ifb
fn_exists: function candidate name: ingress
fn_exists: TYPE_OUTPUT: ingress is a function
fn_exists: return value: 0
ingress
cmd_wrapper: tc: invocation silenced by request, FAILURE either expected or acceptable.
cmd_wrapper: COMMAND: /sbin/tc qdisc del dev eth0 handle ffff: ingress
cmd_wrapper: tc: FAILURE (2): /sbin/tc qdisc del dev eth0 handle ffff: ingress
cmd_wrapper: tc: LAST ERROR: Error: Invalid handle.
cmd_wrapper: COMMAND: /sbin/tc qdisc add dev eth0 handle ffff: ingress
cmd_wrapper: tc: SUCCESS: /sbin/tc qdisc add dev eth0 handle ffff: ingress
cmd_wrapper: tc: invocation silenced by request, FAILURE either expected or acceptable.
cmd_wrapper: COMMAND: /sbin/tc qdisc del dev ifb4eth0 root
cmd_wrapper: tc: FAILURE (2): /sbin/tc qdisc del dev ifb4eth0 root
cmd_wrapper: tc: LAST ERROR: Error: Cannot delete qdisc with handle of zero.
LLA: default link layer adjustment method for cake is cake
cake link layer adjustments: overhead 44 mpu 0
cmd_wrapper: COMMAND: /sbin/tc qdisc add dev ifb4eth0 root cake bandwidth 765000kbit overhead 44 mpu 0 besteffort wash
cmd_wrapper: tc: SUCCESS: /sbin/tc qdisc add dev ifb4eth0 root cake bandwidth 765000kbit overhead 44 mpu 0 besteffort wash
cmd_wrapper: COMMAND: /sbin/ip link set dev ifb4eth0 up
cmd_wrapper: ip: SUCCESS: /sbin/ip link set dev ifb4eth0 up
cmd_wrapper: COMMAND: /sbin/tc filter add dev eth0 parent ffff: protocol all prio 10 u32 match u32 0 0 flowid 1:1 action mirred egress redirect dev ifb4eth0
cmd_wrapper: tc: SUCCESS: /sbin/tc filter add dev eth0 parent ffff: protocol all prio 10 u32 match u32 0 0 flowid 1:1 action mirred egress redirect dev ifb4eth0
sqm_start_default: ingress shaping activated
/var/run/sqm/eth0.start-sqm.log
WITH SQM TURNED ON
root@OpenWrt:~# speedtest-netperf.sh --host "netperf-eu.bufferbloat.net"
2023-04-27 10:20:48 Starting speedtest for 60 seconds per transfer session.
Measure speed to netperf-eu.bufferbloat.net (IPv4) while pinging gstatic.com.
Download and upload sessions are sequential, each with 5 simultaneous streams.
.............................................................
Download: 705.19 Mbps
Latency: [in msec, 61 pings, 0.00% packet loss]
Min: 3.821
10pct: 3.986
Median: 4.116
Avg: 4.166
90pct: 4.337
Max: 4.717
CPU Load: [in % busy (avg +/- std dev) @ avg frequency, 57 samples]
cpu0: 38.8 +/- 7.9 @ 1729 MHz
cpu1: 45.8 +/- 8.4 @ 1658 MHz
cpu2: 40.8 +/- 7.2 @ 1689 MHz
cpu3: 63.3 +/- 0.0 @ 1637 MHz
Overhead: [in % used of total CPU available]
netperf: 32.2
.............................................................
Upload: 79.14 Mbps
Latency: [in msec, 61 pings, 0.00% packet loss]
Min: 3.904
10pct: 3.973
Median: 4.086
Avg: 4.101
90pct: 4.231
Max: 4.636
CPU Load: [in % busy (avg +/- std dev) @ avg frequency, 58 samples]
cpu0: 2.1 +/- 1.3 @ 938 MHz
cpu1: 2.5 +/- 1.4 @ 857 MHz
cpu2: 1.3 +/- 1.0 @ 900 MHz
cpu3: 5.9 +/- 2.2 @ 838 MHz
Overhead: [in % used of total CPU available]
netperf: 0.9
root@OpenWrt:~#
WITH SQM TURNED OFF
root@OpenWrt:~# speedtest-netperf.sh --host "netperf-eu.bufferbloat.net"
2023-04-27 10:48:39 Starting speedtest for 60 seconds per transfer session.
Measure speed to netperf-eu.bufferbloat.net (IPv4) while pinging gstatic.com.
Download and upload sessions are sequential, each with 5 simultaneous streams.
.............................................................
Download: 833.79 Mbps
Latency: [in msec, 61 pings, 0.00% packet loss]
Min: 5.346
10pct: 5.542
Median: 6.020
Avg: 6.136
90pct: 6.391
Max: 9.607
CPU Load: [in % busy (avg +/- std dev) @ avg frequency, 58 samples]
cpu0: 25.3 +/- 8.4 @ 1581 MHz
cpu1: 64.1 +/- 5.3 @ 1542 MHz
cpu2: 27.1 +/- 7.5 @ 1542 MHz
cpu3: 20.2 +/- 7.8 @ 1540 MHz
Overhead: [in % used of total CPU available]
netperf: 24.9
..............................................................
Upload: 101.40 Mbps
Latency: [in msec, 61 pings, 0.00% packet loss]
Min: 5.288
10pct: 5.401
Median: 5.915
Avg: 6.173
90pct: 6.918
Max: 11.704
CPU Load: [in % busy (avg +/- std dev) @ avg frequency, 59 samples]
cpu0: 1.6 +/- 1.2 @ 871 MHz
cpu1: 3.0 +/- 1.7 @ 826 MHz
cpu2: 5.3 +/- 2.2 @ 823 MHz
cpu3: 3.1 +/- 1.4 @ 805 MHz
Overhead: [in % used of total CPU available]
netperf: 1.0
root@OpenWrt:~#
