Hi Martin,
I just did a quick test and I get pretty much the same decent simple.qos performance independent whether I instantiate on pppoe-wan or on eth0 (the cpu port facing the internal switch). So it is not switch per se...
Best Regards
Hi Martin,
I just did a quick test and I get pretty much the same decent simple.qos performance independent whether I instantiate on pppoe-wan or on eth0 (the cpu port facing the internal switch). So it is not switch per se...
Best Regards
I guess I need to repeat the same test on my turris omnia, since that has a different switch than the old netgear...
I tried running speedtest-cli directly on the router to remove everything else from the equation. Best result so far is with layer_cake, with ping spiking during download whether I set ingress to 120Mbit or 12Mbit. If the switch was problematic I would expect the ping to decrease at 12Mbit, but it's around 500ms in both cases.
64 bytes from 8.8.8.8: seq=10 ttl=57 time=23.585 ms
64 bytes from 8.8.8.8: seq=11 ttl=57 time=24.711 ms
64 bytes from 8.8.8.8: seq=12 ttl=57 time=24.721 ms
64 bytes from 8.8.8.8: seq=13 ttl=57 time=144.967 ms
64 bytes from 8.8.8.8: seq=14 ttl=57 time=259.637 ms
64 bytes from 8.8.8.8: seq=15 ttl=57 time=476.899 ms
64 bytes from 8.8.8.8: seq=16 ttl=57 time=97.625 ms
64 bytes from 8.8.8.8: seq=17 ttl=57 time=158.811 ms
64 bytes from 8.8.8.8: seq=18 ttl=57 time=535.147 ms
64 bytes from 8.8.8.8: seq=19 ttl=57 time=308.608 ms
64 bytes from 8.8.8.8: seq=20 ttl=57 time=262.847 ms
64 bytes from 8.8.8.8: seq=21 ttl=57 time=293.383 ms
64 bytes from 8.8.8.8: seq=22 ttl=57 time=358.182 ms
64 bytes from 8.8.8.8: seq=23 ttl=57 time=23.244 ms
64 bytes from 8.8.8.8: seq=24 ttl=57 time=21.289 ms
64 bytes from 8.8.8.8: seq=25 ttl=57 time=22.303 ms
If I limit download speed with curl, ping remains low. It only increases when it hits the SQM ingress limit.
I tried 12MBps with this file.
curl --limit-rate 12m "http://ovh.net/files/1Gio.dat" > /dev/null
Good idea, unfortunately this test stresses different pathways than routing (plus it puts additional load on the router's CPU). I believe in this case it did not make a difference as both routed packets as well as router-originating/terminating packets cause the nasty ingress bufferbloat in spite of sqm.
Yeah, this confirms that something is wonkey. It could still be the switch it that keeps buffering incoming packets, but at one point the tcp senders should get the signal to slow down and given enough time, things should normalize (that is for long running TCP flows that saturate the link ICMP probes should after some time come back to sane levels). Are you by any chance using ECN, if yes disable it on the end host used for testing, if no enable it, just to see whether that changes anything.
Best Regards
I had similar issues on a TP Link Archer C7v2, using Gargoyle QoS. Ping times went to the roof (from 40 ms to 900 ms or so). Never found an explanation.
Then I moved to LEDE and cake/PoC, and also got worse results than without SQM.
Again, no explanations...
ECN was enabled. I tried NOECN and didn't notice any difference.
@deuteragenie, thanks for the comment. I've had the Archer C7v2 for years and I swear QoS used to work just fine at 30Mbps. I only hit issues when I upgraded my Internet plan and started messing with latest nightly builds. I bought the WRT3200ACM thinking it needed a 1.8Ghz dual core. 
I'm having the same issue. 100Mbit/s cable plan but as soon as SQM is enabled the bandwith drops down to about 4-5MBit/s independently of which queue discipline or queue setup script is set.
cable is usually very bursty.
i have seen better results after raising rtt, like:
option iqdisc_opts 'nat dual-dsthost rtt 200ms'
also try with 300ms see if that helps
Are you selecting eth0.2 (or whatever your specific wan interface's name is) ? I remember facing a similar issue when I had eth0 selected. i.e. You shouldn't enable it on eth0, but the specific wan interface (eth0.2 in my case).
okay, I suspect something went completely wrong with configuration and stuff, so I reflashed and erased all configuration.
But now I can't install certain packages due to a mismatch in the packages hash. I will report back as sonn as I'm able to reinstall everything. (Probably when rc-2 is released)
Thanks for your help though.
okay I was able to reinstall SQM. Bandwith doesn't drop extremely low any more. I probably should try clean flashes next time before complaining 
Just use --force-checksum and it will install.
I did, but some dependencies weren't even available. There was a problem with the package builds for mips_24kc but that has been resolved yesterday.
I read this entire thread twice and it's been very helpful to trouble some latency spikes I was getting. It's been bothering me for months. I'm using the ethernet 28 bytes overhead, disabled generic receive offload via ethtool, and added "option shaper_burst 1" to /etc/config/sqm. Now I get consistent results and I'm able to increase my up/down speeds 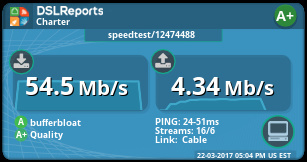 My subscribed speeds with Charter (Slidell,LA) are 60 down/4 up. I average 66.1-66.5 down && 5.5-5.9 up without Cake SQM. I'm not exactly sure whether the ethernet overhead or the shaper option, or both, solved the problem. I've exhausted my "no activity and restricted testing" window with the roomies, Have to narrow it down later. For the moment, it's 99 percent effective.
My subscribed speeds with Charter (Slidell,LA) are 60 down/4 up. I average 66.1-66.5 down && 5.5-5.9 up without Cake SQM. I'm not exactly sure whether the ethernet overhead or the shaper option, or both, solved the problem. I've exhausted my "no activity and restricted testing" window with the roomies, Have to narrow it down later. For the moment, it's 99 percent effective.
config queue 'eth1'
option interface 'eth1'
option debug_logging '0'
option verbosity '5'
option qdisc 'cake'
option script 'piece_of_cake.qos'
option enabled '1'
option qdisc_advanced '1'
option squash_dscp '1'
option squash_ingress '1'
option ingress_ecn 'ECN'
option egress_ecn 'NOECN'
option qdisc_really_really_advanced '0'
option shaper_burst '1'
option linklayer 'ethernet'
option overhead '28'
option download '59400'
option upload '4500'
Congratulation, that you got your system working well!
That said, please let me add two comments.
This will do something for the HTB shaper used by simple.qos and siplest.qos, but will not do anything for cake as a shaper. Since you have:
I am confident that getting rid of [quote="mindwolf, post:35, topic:1087"]
"option shaper_burst 1"
[/quote]
in your /etc/config/sqm will not change the decent shaper performance ![]() (really have a look in /usr/lib/sqm/functions.sh to convince yourself that I am not confused).
(really have a look in /usr/lib/sqm/functions.sh to convince yourself that I am not confused).
And finally you might want to add the following two lines to your /etc/config/sqm:
option iqdisc_opts 'nat dual-dsthost mpu 64'
option eqdisc_opts 'nat dual-srchost mpu 64'
This will effectively distribute bandwidth fair to all concurrently active internal IP addresses/computers. See [option iqdisc_opts 'nat dual-dsthost' option eqdisc_opts 'nat dual-srchost'](http://option iqdisc_opts 'nat dual-dsthost' option eqdisc_opts 'nat dual-srchost') for a description how to configure this via the GUI.
Please note that cake specific keywords in iqdisc_opts/eqdisc_opts will make HTB based shaper scripts and non-cake qdiscs break silently, so remember to remove this before switching away from cake.
Best Regards
Thank you very much for your info! I'm still confused about the ethernet overhead bit. Some documentation states linux accounts for 14 bytes. ethernet is 14, plus udp 8 tcp 20. Is this the remaining 28 bytes?
I just found your article moeller0 from another site: https://forum.turris.cz/t/how-to-use-the-cake-queue-management-system-on-the-turris-omnia/3103/61
WELL....DONE.... SIR
So depending on the interface type linux will add a variable amount of overhead automatically; for IP interfaces like eth1 it typically adds 14 bytes (2 dst MAC, 6 src MAC, 2 ethertype) while for say pppoe interfaces it adds 0 bytes. Cake however learned how to undo that accounting, so that with recent sch_cake modules you simply specify the wanted amount of overhead independent of the interface type. If you run "tc -s qdisc" you will see something like:
qdisc cake 8008: dev ifb4pppoe-wan root refcnt 2 bandwidth 46246Kbit diffserv3 dual-dsthost nat rtt 100.0ms noatm overhead 34 via-ethernet
the via-ethernet part tells you that cake is auto accounting for the kernel.
Side note, since I instantiate that shaper on an pppoe interface the kernel sees maximal packet sizes of 1492, so if we add 34 bytes we end up the 1492+34 = 1526 Bytes that we know the on-the-wire packets to be. If the same effect should be gotten, by instantiating the shaper on the "physical" interface underneath pppoe, I only would have set the overhead to 26. In the former case the packet size as seen by cake does not yet include the 8 byte pppoe header, while in the latter it does, but I digress.
Best Regards
Quick question:
How this: option iqdisc_opts 'mpu 64' is different from this: option tcMPU '64' ?