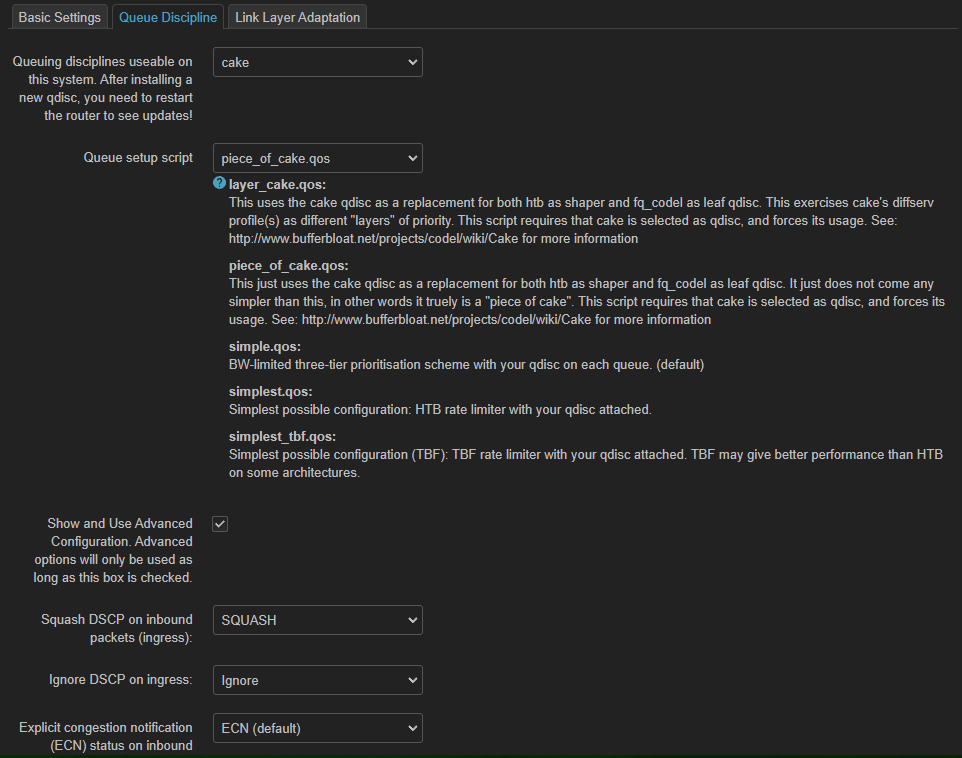
Thank you, much easier to read for me. This looks like things are working out for you, both ingress and egress cake instances show traffic in only Best Effort and Voice, as expected from your configuration.
If you want to configure the overhead manually, just add overhead 18 mpu 64 to both:
So ACK filter will aggregate queued up ACKs, so let's assume for a given TCP flow, we have say three ACK packets in the egress queue, now if this queue is serviced again we could either send these three ACKs back to back or (since ACKs are accumulative) we could drop the first two ACKs and only send the last one with the highest sequence number. The receiver of the ACKs will perform more or less the same whether three consecutive ACKs arrive back to back of only the last one, but we removed 66% of the traffic volume of that ACK burst. AND if we would not have send all three ACKs at the same time, but say only the first two the improvement not only affects the ACK volume, but the ACK signal of the last ACK would be delayed, potentially stalling the sender (while with an ACK filter the most recently received segment would be acknowledged quicker).
In short on bursty MAC layers like DOCSIS ack-filtering can help.
ACK filtering should have zero impact on pure UDP flows, but in theory ACK filtering might overload your CPU. But I wonder how you assessed "clearly felt better", because that can be a fluke...
That said, for your gaming issue ACK-filtering is completely orthogonal, as long as your game traffic is the only traffic in the Voice priority class your game should not care much about what happens with TCPs....
Just to illustrate the issue though, with classic TCP Reno there will be one small ACK packet for every two full MSS segment received, assuming MTU 1500 and IPv4/TCP a pure ACK packet is roughly 1/20 the size of a full-MTU/full-MSS packet, and one ACK every two full segments gives us: ACK/Data = 1/40
So for a saturating download on a 1 Gbps link you can expect 1000/40 = 25 Mbps of reverse ACK upload traffic, on a 1000/50 link that is already 50% of you upload capacity...
More modern TCPs than Reno, especially with aggregation techniques like GRO/GSO will emit noticeably fewer ACKs ameliorating the problem.
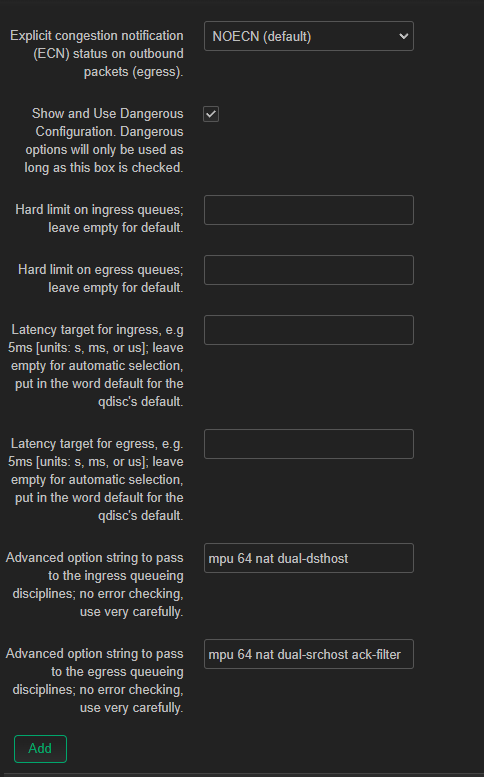
my shots didnt register right (same server) but i tried it with overhead 18 mpu 64 ack-filter
i will try it later again with overhead 22 mpu 64 ack-filter
Again, unlikely to be involved in your issue. Overhead 18 or 22 is unlikely to be an issue unless you saturate at least one direction of your link with really small packets,.
So unless you did heavily load your internet acces link in parallel to playing your game this is unlikely to affect your game at all.
I understand that testing responsiveness in games is quite tricky and I do net envy you....
I think this will answer your question: The ingress & egress setup calls
egress() {
SILENT=1 $TC qdisc del dev $IFACE root
$TC qdisc add dev $IFACE root cake bandwidth ${UPLINK}kbit \
$( get_cake_lla_string ) ${EGRESS_CAKE_OPTS} ${EQDISC_OPTS}
# Put act_ctinfo on the egress interface to set DSCP from the stored connmark.
# This seems counter intuitive but it ensures once the mark is set that all
# subsequent egress packets have the same stored DSCP. This avoids the need
# for iptables to run/mark every packet.
$TC filter add dev $IFACE matchall \
action ctinfo dscp ${DSCP} ${DSCPS}
}
ingress() {
SILENT=1 $TC qdisc del dev $IFACE handle ffff: ingress
$TC qdisc add dev $IFACE handle ffff: ingress
SILENT=1 $TC qdisc del dev $DEV root
[ "$ZERO_DSCP_INGRESS" -eq "1" ] && INGRESS_CAKE_OPTS="$INGRESS_CAKE_OPTS wash"
$TC qdisc add dev $DEV root cake bandwidth ${DOWNLINK}kbit \
$( get_cake_lla_string ) ${INGRESS_CAKE_OPTS} ${IQDISC_OPTS}
$IP link set dev $DEV up
# restore DSCP from conntrack mark into packet
# redirect all packets arriving in $IFACE to ifb0
$TC filter add dev $IFACE parent ffff: matchall \
action ctinfo dscp ${DSCP} ${DSCPS} \
action mirred egress redirect dev $DEV
}
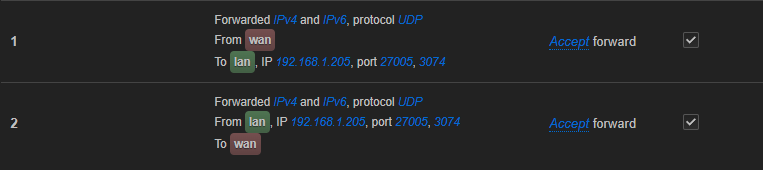
I guess not, since there would be no scheduler to honors priorities. One more issue, NAT can/will remap the internal-port numbers so it might be safer to attach your rules to the remote port ranges instead. (I might be misreading your screenshot though, maybe better post the relevant sections from your \etc/config/firewall as text?)
A) If the IFB goes away for what ever reason (say the underlaying pppoe interface ceased to exist) the action will also be gone for good? Or put differently is there anything else required than a $TC qdisc del dev $DEV root to get rid of the action?
B) What requirement for additional packets exists for using this (I would like to add this great capability to a variant of layer_cake.qos in the main repository, but want to make it safe even on systems lacking the requirements)
Please note: my idea is to keep actual egress marking rules out of the scripts and delegate users to using the firewalls DSCP classification action to set egress DSCPs to their hearts content, so all we need would be two additional tc lines guarded by a check whether the required functionality exists on the system...
Hrm, that is a bit of a show stopper for me right now, as my iptables tells me:
root@turris:~# iptables -t mangle -A MANGLE_CHAIN_HERE -j CONNMARK --set-dscpmark help
iptables v1.8.3 (legacy): unknown option "--set-dscpmark"
Try `iptables -h' or 'iptables --help' for more information.
Yes, the command would fail as exercised anyway, but I guess unknown option "--set-dscpmark" also tells my that my iptables is not usable right now, which makes testing a tad tricky...
Also, if I want to use the firewall GUI to set the marking rules, I guess (naively?) that I need a generic mangle rule here that copies the existing DSCP into the connmark somehow.
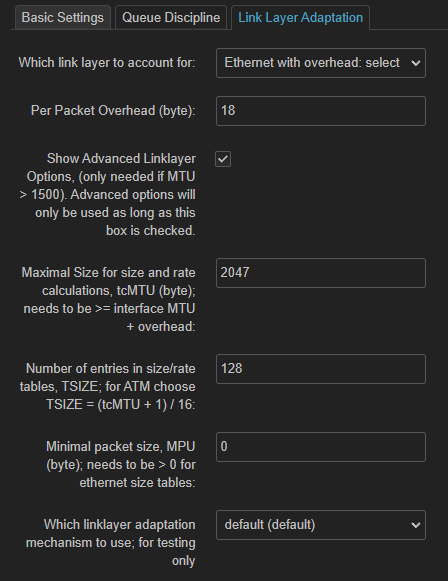
That is the actual text in the GUI, which admittedly is not correct, since adjusting the MPU is required as the default of 0 is correct only increasingly rarely (on some ATM encapsulations).
For cable/DOCSIS you really should set mpu 64 how you do that, via the e/ingress options or via the GUI does not matter anymore (cake will honor the mpu value in the GUI.
As a non-gamer I would say probably, I might try to add the ingress keyword to the advanced option string for ingress, but that is all I can see. However if gaming sucks you might want to switch to layer_cake.qos and carefully up-priritize only the gaming packets. But that is a whole different kettle of fish.
Personally I would always first try without prioritization, but then I stopped reaction-time gated gaming shortly after the original quake came around, so have little first hand experience to base my recommendations on.
Same here. For various reasons, I need to stay on 19.07.x, is there a patch I can apply to that version of iptables (1.8.3 in my case) that would add in the set-dscpmark function ?
even if it's not reaction time gated... it can still suffer a lot from lag and lost packets. Something like Minecraft or Rocket League, you can get rubber-banding or crashing into things that you don't know are there or it doesn't register a jump... etc if that happens often enough even a game that can be played without fast reactions will be no fun.
@N1K - I (perhaps mistakenly) assume that since you're gaming, you're using a Windows desktop or laptop. If so, and if you're using a professional version of Windows, you can fairly easily add DSCP markings to the outgoing traffic by using gpedit.msc, the Group Policy Editor.