Do you know if this fix has been applied to the ZyXEL NBG6817? It has the same hardware as the R7800.
It should be because as you said:
The main R7800 page (https://openwrt.org/toh/netgear/r7800) still says to do this.
echo 35 > /sys/devices/system/cpu/cpufreq/ondemand/up_threshold
echo 10 > /sys/devices/system/cpu/cpufreq/ondemand/sampling_down_factor
I haven't heard anyone mention this in awhile; is this still recommended/needed with the latest openwrt (19.07.3)?
2 Likes
Why not just run performance governor at max freq all the time and not search for the perfect settings anymore? Heat is not a problem on the R7800 but do monitor it:
cut -c1-2 /sys/devices/virtual/thermal/*/temp
With an aggressive ondemand up_threshold value you will pretty much spend most time at max frequency anyway, bouncing between min and max frequencies.
I don't think many realize what up_threshold means, it is not the load to step up to the next freq, but rather to jump up all the way to max freq. I tried it with min=800, max=1.7 and up_threshold=20 and it just flip-flops between 800 and 1.7, the frequencies in between (1.0, 1.4) are never used.
From the kernel documentation:
https://www.kernel.org/doc/html/v5.4/admin-guide/pm/cpufreq.html
up_threshold
If the estimated CPU load is above this value (in percent), the governor will set the frequency to the maximum value allowed for the policy. Otherwise, the selected frequency will be proportional to the estimated CPU load.
(useful to also read the explanation for sampling_down_factor)
After you make governor changes, you can:
# Reset stats
echo 1 > /sys/devices/system/cpu/cpufreq/policy0/stats/reset
echo 1 > /sys/devices/system/cpu/cpufreq/policy1/stats/reset
Then run it for a bit and:
# View stats
cat /sys/devices/system/cpu/cpufreq/policy*/stats/time_in_state
3 Likes
Why not just run
performancegovernor at max freq all the time and not search for the perfect settings
To be clear, do you mean doing just this and skipping the other stuff?
echo performance > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor
echo performance > /sys/devices/system/cpu/cpufreq/policy1/scaling_governor
Exactly.
This is what I have in my /etc/rc.local so I can easily uncomment the governor I want to use and comment out the other 2:
# min scaling frequency: set to 800MHz because of L2 cache issues
echo 800000 > /sys/devices/system/cpu/cpufreq/policy0/scaling_min_freq
echo 800000 > /sys/devices/system/cpu/cpufreq/policy1/scaling_min_freq
sleep 1
# ondemand governor
#echo ondemand > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor
#echo ondemand > /sys/devices/system/cpu/cpufreq/policy1/scaling_governor
#echo 100000 > /sys/devices/system/cpu/cpufreq/ondemand/sampling_rate
#echo 75 > /sys/devices/system/cpu/cpufreq/ondemand/up_threshold
#echo 10 > /sys/devices/system/cpu/cpufreq/ondemand/sampling_down_factor
# schedutil governor
#echo schedutil > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor
#echo schedutil > /sys/devices/system/cpu/cpufreq/policy1/scaling_governor
#echo 100000 > /sys/devices/system/cpu/cpufreq/schedutil/rate_limit_us
# performance governor
echo performance > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor
echo performance > /sys/devices/system/cpu/cpufreq/policy1/scaling_governor
# Reset stats
echo 1 > /sys/devices/system/cpu/cpufreq/policy0/stats/reset
echo 1 > /sys/devices/system/cpu/cpufreq/policy1/stats/reset
3 Likes
Can anyone tell me where to check to figure out why my R7800 restarts randomly? For the third time it has restarted at the most inopportune time (conference call, middle of game, etc.). I am running hnyman's build - trying different "tuning" that people post, but the same thing always happens. I have looked in /var/log and found nothing. I looked at the kernel and system logs in the GUI and found nothing. Where do I go to see what is causing these crashes? Anyone know?
Thanks!
DeadEnd
Serial console output during the actual crash. To prevent flash wear, logs are written to ram, so they do not survive a reboot.
P.s. One known/suspected reason for occasional crashes has been jumbo frames from other devices. There was apparently a bug in the kernel driver for fixed ethernet, but that should have been fixed before kernel 5.4.
Okay, so not really an easy way to figure it out...
I just update from r13628-870588b6eb-20200625 to r13881-bae4204e34-20200718.
I'll see if my some miracle that fixes anything.
I already made the adjustment of adding
echo 800000 > /sys/devices/system/cpu/cpufreq/policy0/scaling_min_freq
echo 800000 > /sys/devices/system/cpu/cpufreq/policy1/scaling_min_freq
to the local startup commands as I had read that it fixes some issues with crashing.
It did greatly reduce the amount of transitions the CPU's were doing.
I thought that had fixed it, but the random crashes still persist.
They next thing I might try is changing the governor to performance - this basically just runs at full clock speed correct?
If I get another crash, that'll be the next time.
Thanks for the help!
Could this help?
No.
The crashlog feature is disabled for most common router processor architectures.
To my knowledge, it only works for some MIPS devices in practice.
1 Like
Think commit in ndb's stanging repo sounds interesting:
kernel: add patch that adds support for running threaded NAPI poll functions
This is helps on workloads with CPU intensive poll functions (e.g. 802.11) on multicore systems
For some drivers (especially 802.11 drivers), doing a lot of work in the NAPI poll function does not perform well. Since NAPI poll is bound to the CPU it was scheduled from, we can easily end up with a few very busy CPUs spending most of their time in softirq/ksoftirqd and some idle ones.
Introduce threaded NAPI for such drivers based on a workqueue. The API is the same except for using netif_threaded_napi_add instead of netif_napi_add.
In my tests with mt76 on MT7621 using threaded NAPI + a thread for tx scheduling improves LAN->WLAN bridging throughput by 10-50%. Throughput without threaded NAPI is wildly inconsistent, depending on the CPU that runs the tx scheduling thread.
With threaded NAPI it seems stable and consistent (and higher than the best results I got without it).
(I haven't tested it yet.)
1 Like
Sounds like it helps mostly with mt76.
Any summary of recommended settings? i currently have 600/600 mb wan which is not able to manage. Use 19.07 (kong 2020-01) kernel 4.14.179.
I don't have anything in rc.local, what do you recommend to put?
Thank you.
I suspect this patch might just make the firmware crash faster if there are any undiagnosed race conditions hanging around. I'd love to see if it makes a difference with the R7800 though.
1 Like
Well so far 9.5 days on the above and no crashes.
Whatever was going on causing the crashes seems to be gone now.
I also found this and put it in my local startup - that might have helped... not sure:
# Put your custom commands here that should be executed once
# the system init finished. By default this file does nothing.
# min scaling frequency: set to 800MHz because of L2 cache issues
echo 800000 > /sys/devices/system/cpu/cpufreq/policy0/scaling_min_freq
echo 800000 > /sys/devices/system/cpu/cpufreq/policy1/scaling_min_freq
sleep 1
# ondemand governor
echo ondemand > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor
echo ondemand > /sys/devices/system/cpu/cpufreq/policy1/scaling_governor
echo 100000 > /sys/devices/system/cpu/cpufreq/ondemand/sampling_rate
echo 75 > /sys/devices/system/cpu/cpufreq/ondemand/up_threshold
echo 10 > /sys/devices/system/cpu/cpufreq/ondemand/sampling_down_factor
# schedutil governor
#echo schedutil > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor
#echo schedutil > /sys/devices/system/cpu/cpufreq/policy1/scaling_governor
#echo 100000 > /sys/devices/system/cpu/cpufreq/schedutil/rate_limit_us
# performance governor
#echo performance > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor
#echo performance > /sys/devices/system/cpu/cpufreq/policy1/scaling_governor
# Reset stats
echo 1 > /sys/devices/system/cpu/cpufreq/policy0/stats/reset
echo 1 > /sys/devices/system/cpu/cpufreq/policy1/stats/reset
exit 0
I believe ondemand was the default anyway, but when I checked the sampling was much much lower (if I remember correctly) so maybe these tweaks helped too? If anyone thinks one of these settings is wrong or could be improved, I'm always happy to hear it!
Thanks as always for the community support!
DeadEnd
One thing to consider- Using 800mhz as your minimum frequency you’ll probably never see a frequency increase with an up threshold of 75. This will hurt performance for max 5ghz wifi speeds or as you approach near gig wired speeds.
Most people will use a more aggressive up threshold with 800mhz as their minimum. 20-35 is pretty popular. Personally I use the more aggressive end (90%+ of the time the router is at 800mhz, only a fraction of the time it ramps up to max frequency). This is what my startup settings are:
echo 800000 > /sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq
echo 800000 > /sys/devices/system/cpu/cpu1/cpufreq/scaling_min_freq
echo 20 > /sys/devices/system/cpu/cpufreq/ondemand/up_threshold
echo 60 > /sys/devices/system/cpu/cpufreq/ondemand/sampling_down_factor
echo 1000000 > /sys/devices/system/cpu/cpufreq/ondemand/sampling_rate
This what the time at each frequency looks like with these settings:
root@OpenWrt:~# cat /sys/devices/system/cpu/cpufreq/policy*/stats/time_in_state
384000 1138
600000 116
800000 26059202
1000000 237
1400000 177
1725000 64726
384000 2191
600000 111
800000 26078669
1000000 131
1400000 89
1725000 44405
I posted those settings so I can comment on them based on my use case and observations 
up_threshold 75 works quite well if you want to use pretty much all frequencies between 800-1.7 and have a gradual ramp up. I use mine in AP mode, most services turned off and it does get to 1.7 when laptops back up over wifi.
If you go aggressive 20-35 then you will just be jumping from 800 pretty much to 1.7, you don't use 1 or 1.4, because up_threshold is the load to go all the way up to max, not to the next frequency. At least in my case when I tried aggressive settings I never saw 1.4 being used. Not that it really matters, because ...
I use the performance governor, locked at 1.7, I don't see much benefit in transitioning between frequencies a lot. This is not a phone, you're not trying to save battery.
FWIW, I noticed schedutil to not be aggressive at all, with 800 min freq, I rarely see moves up to higher frequencies.
Router has been stabling running for over 10 days - so that makes me happy .
Here are the charts for the last week with the 75/10 up threshold/sampling down factor:

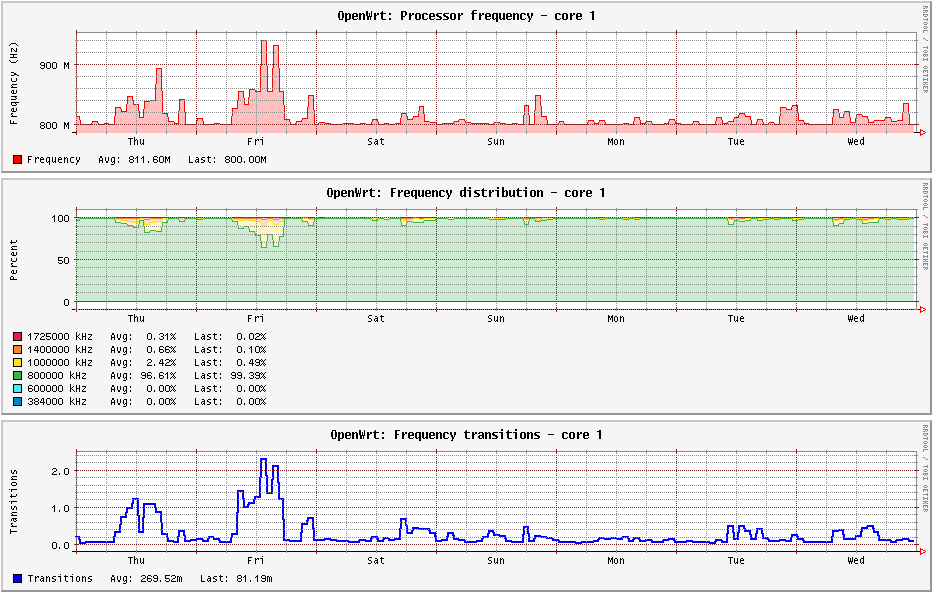
So yes, I rarely go up past the 800Mhz - but my WAN is only 30/5 - so there probably isn't a ton of stress on the system anyway  . Since WAN speed is probably a non-issue I'm more happy with stability and WiFi between devices. Again though, I would be happy to test other settings to see how they work - but as of now, its not broke, lol.
. Since WAN speed is probably a non-issue I'm more happy with stability and WiFi between devices. Again though, I would be happy to test other settings to see how they work - but as of now, its not broke, lol.
Cheers!
Thanks for the feedback!
DeadEnd
update: past 15 days now... so I have a good feeling whatever was causing the restart every 4-6 days is now fixed. Very happy as like many others, Work from Home is the new normal and I needed this to be reliable.
Cheers!
2 Likes
I didn't see your Exit 0. I'm assuming you also have...
echo 2 > /proc/irq/31/smp_affinity
echo 2 > /proc/irq/32/smp_affinity
... in there somewhere for the irq "balancing"?