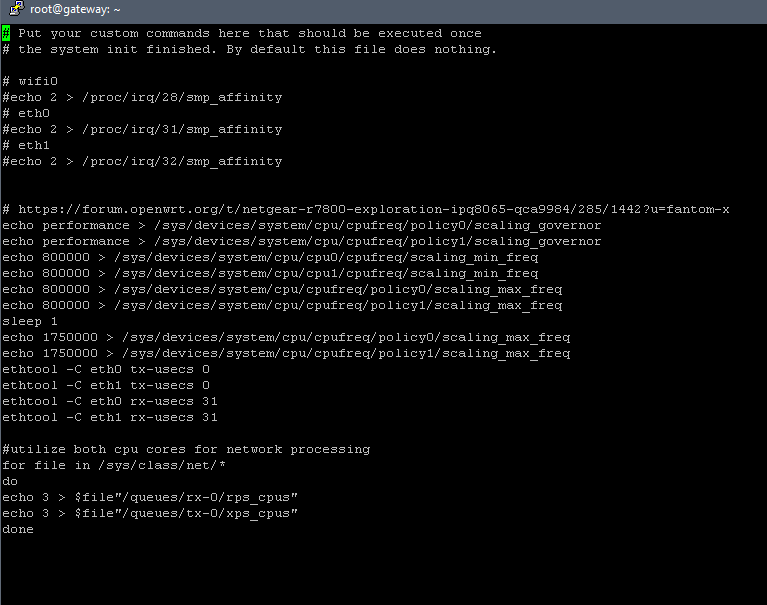
I've been playing around with testing the frequency scaling on my R7800...seeing as we seem to think there's an issue with the l2-cache scaling, i used a simple memory bandwidth benchmark to try out various transitions through the speed bins: https://github.com/facboy/openwrt-r7800-freq-test
i'd be interested in other people's results. this is from my build which is largely hnyman's build with a patched https://github.com/openwrt/openwrt/pull/2280, i haven't tried with eg a vanilla hnyman build yet.
root@worstwrt:~/bin/freq-test# ./test_mbw.sh
*** My defaults (ondemand)
AVG Method: MEMCPY Elapsed: 0.00154 MiB: 1.00000 Copy: 648.803 MiB/s
AVG Method: DUMB Elapsed: 0.00576 MiB: 1.00000 Copy: 173.656 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00153 MiB: 1.00000 Copy: 652.443 MiB/s
*** Setting performance governor
Setting scaling_max_freq to 384000
AVG Method: MEMCPY Elapsed: 0.00290 MiB: 1.00000 Copy: 345.304 MiB/s
AVG Method: DUMB Elapsed: 0.02870 MiB: 1.00000 Copy: 34.843 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00282 MiB: 1.00000 Copy: 355.051 MiB/s
Setting scaling_max_freq to 600000
AVG Method: MEMCPY Elapsed: 0.00254 MiB: 1.00000 Copy: 393.391 MiB/s
AVG Method: DUMB Elapsed: 0.01808 MiB: 1.00000 Copy: 55.304 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00255 MiB: 1.00000 Copy: 391.803 MiB/s
Setting scaling_max_freq to 800000
AVG Method: MEMCPY Elapsed: 0.00185 MiB: 1.00000 Copy: 540.044 MiB/s
AVG Method: DUMB Elapsed: 0.01165 MiB: 1.00000 Copy: 85.823 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00185 MiB: 1.00000 Copy: 540.511 MiB/s
Setting scaling_max_freq to 1000000
AVG Method: MEMCPY Elapsed: 0.00177 MiB: 1.00000 Copy: 564.557 MiB/s
AVG Method: DUMB Elapsed: 0.00947 MiB: 1.00000 Copy: 105.619 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00182 MiB: 1.00000 Copy: 548.908 MiB/s
Setting scaling_max_freq to 1400000
AVG Method: MEMCPY Elapsed: 0.00163 MiB: 1.00000 Copy: 615.006 MiB/s
AVG Method: DUMB Elapsed: 0.00677 MiB: 1.00000 Copy: 147.721 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00161 MiB: 1.00000 Copy: 619.387 MiB/s
Setting scaling_max_freq to 1725000
AVG Method: MEMCPY Elapsed: 0.00251 MiB: 1.00000 Copy: 398.279 MiB/s
AVG Method: DUMB Elapsed: 0.00587 MiB: 1.00000 Copy: 170.216 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00229 MiB: 1.00000 Copy: 436.758 MiB/s
*** Now seems to be busted
Setting scaling_max_freq to 800000
AVG Method: MEMCPY Elapsed: 0.00241 MiB: 1.00000 Copy: 415.628 MiB/s
AVG Method: DUMB Elapsed: 0.01181 MiB: 1.00000 Copy: 84.680 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00241 MiB: 1.00000 Copy: 414.542 MiB/s
Setting scaling_max_freq to 1000000
AVG Method: MEMCPY Elapsed: 0.00237 MiB: 1.00000 Copy: 421.745 MiB/s
AVG Method: DUMB Elapsed: 0.00955 MiB: 1.00000 Copy: 104.723 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00241 MiB: 1.00000 Copy: 415.800 MiB/s
Setting scaling_max_freq to 1400000
AVG Method: MEMCPY Elapsed: 0.00229 MiB: 1.00000 Copy: 435.787 MiB/s
AVG Method: DUMB Elapsed: 0.00705 MiB: 1.00000 Copy: 141.832 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00229 MiB: 1.00000 Copy: 436.186 MiB/s
Setting scaling_max_freq to 1725000
AVG Method: MEMCPY Elapsed: 0.00227 MiB: 1.00000 Copy: 440.199 MiB/s
AVG Method: DUMB Elapsed: 0.00596 MiB: 1.00000 Copy: 167.706 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00229 MiB: 1.00000 Copy: 436.987 MiB/s
*** Restored by setting to 600 first
Setting initial scaling_max_freq to 600000
Setting scaling_max_freq to 1000000
AVG Method: MEMCPY Elapsed: 0.00183 MiB: 1.00000 Copy: 546.001 MiB/s
AVG Method: DUMB Elapsed: 0.00949 MiB: 1.00000 Copy: 105.374 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00186 MiB: 1.00000 Copy: 537.057 MiB/s
Setting initial scaling_max_freq to 600000
Setting scaling_max_freq to 1400000
AVG Method: MEMCPY Elapsed: 0.00158 MiB: 1.00000 Copy: 634.357 MiB/s
AVG Method: DUMB Elapsed: 0.00688 MiB: 1.00000 Copy: 145.319 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00161 MiB: 1.00000 Copy: 619.655 MiB/s
Setting initial scaling_max_freq to 600000
Setting scaling_max_freq to 1725000
AVG Method: MEMCPY Elapsed: 0.00156 MiB: 1.00000 Copy: 641.519 MiB/s
AVG Method: DUMB Elapsed: 0.00572 MiB: 1.00000 Copy: 174.706 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00156 MiB: 1.00000 Copy: 639.550 MiB/s
Setting initial scaling_max_freq to 600000
Setting scaling_max_freq to 1400000
AVG Method: MEMCPY Elapsed: 0.00185 MiB: 1.00000 Copy: 541.389 MiB/s
AVG Method: DUMB Elapsed: 0.00689 MiB: 1.00000 Copy: 145.140 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00162 MiB: 1.00000 Copy: 617.627 MiB/s
*** Breaks when jumping from 1000
Setting initial scaling_max_freq to 1000000
Setting scaling_max_freq to 1000000
AVG Method: MEMCPY Elapsed: 0.00178 MiB: 1.00000 Copy: 560.852 MiB/s
AVG Method: DUMB Elapsed: 0.00957 MiB: 1.00000 Copy: 104.471 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00181 MiB: 1.00000 Copy: 551.359 MiB/s
Setting initial scaling_max_freq to 1000000
Setting scaling_max_freq to 1400000
AVG Method: MEMCPY Elapsed: 0.00160 MiB: 1.00000 Copy: 626.881 MiB/s
AVG Method: DUMB Elapsed: 0.00682 MiB: 1.00000 Copy: 146.660 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00160 MiB: 1.00000 Copy: 625.078 MiB/s
Setting initial scaling_max_freq to 1000000
Setting scaling_max_freq to 1725000
AVG Method: MEMCPY Elapsed: 0.00229 MiB: 1.00000 Copy: 435.939 MiB/s
AVG Method: DUMB Elapsed: 0.00619 MiB: 1.00000 Copy: 161.540 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00227 MiB: 1.00000 Copy: 440.529 MiB/s
Setting back to my defaults (ondemand)
Setting scaling_max_freq to 1725000
AVG Method: MEMCPY Elapsed: 0.00231 MiB: 1.00000 Copy: 432.769 MiB/s
AVG Method: DUMB Elapsed: 0.00598 MiB: 1.00000 Copy: 167.090 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00226 MiB: 1.00000 Copy: 442.693 MiB/s