I am using the Shadow (gaming cloud pc) service. It is basically a virtual machine running Windows in a datacenter, which is sending me a stream of the display(s). There is only one thing bothering me: When my wife or kids start Netflix, my Shadow ping increases and the display stream becomes choppy. Without Netflix, everything is smooth.
I am on a 100Mbit down, 30Mbit up VDSL connection. I have the ISP modem in bridge mode, and running a Linksys WRT32X. I got this router secondhand a few days ago, also based on the fact I could flash to OpenWRT when necessary. The stock firmware already gave some improvement when comparing to my (11-year) old router, but did not make the issue disappear. The Shadow stream takes a steady 40Mbit when using it during games.
What method would you advice to prioritise this relatively large 40Mbit stream?
It this a bufferbloat issue because of the bursty Netflix spikes? So SQM?
Or a simple QoS rule, limiting Netflix or the Netflix device?
I really am no expert in this field, and could use some of your advice before I start messing around in settings I am not familiar with. So I am curious if you can help me! And please let me know if further info is needed. I will be happy to try some of your ideas.
Thanks for your reply. I already started experimenting with SQM, since a member of another local forum introduced me to bufferbloat. Thanks to him I got into the OpenWrt boat. I am now running cake with piece of cake.
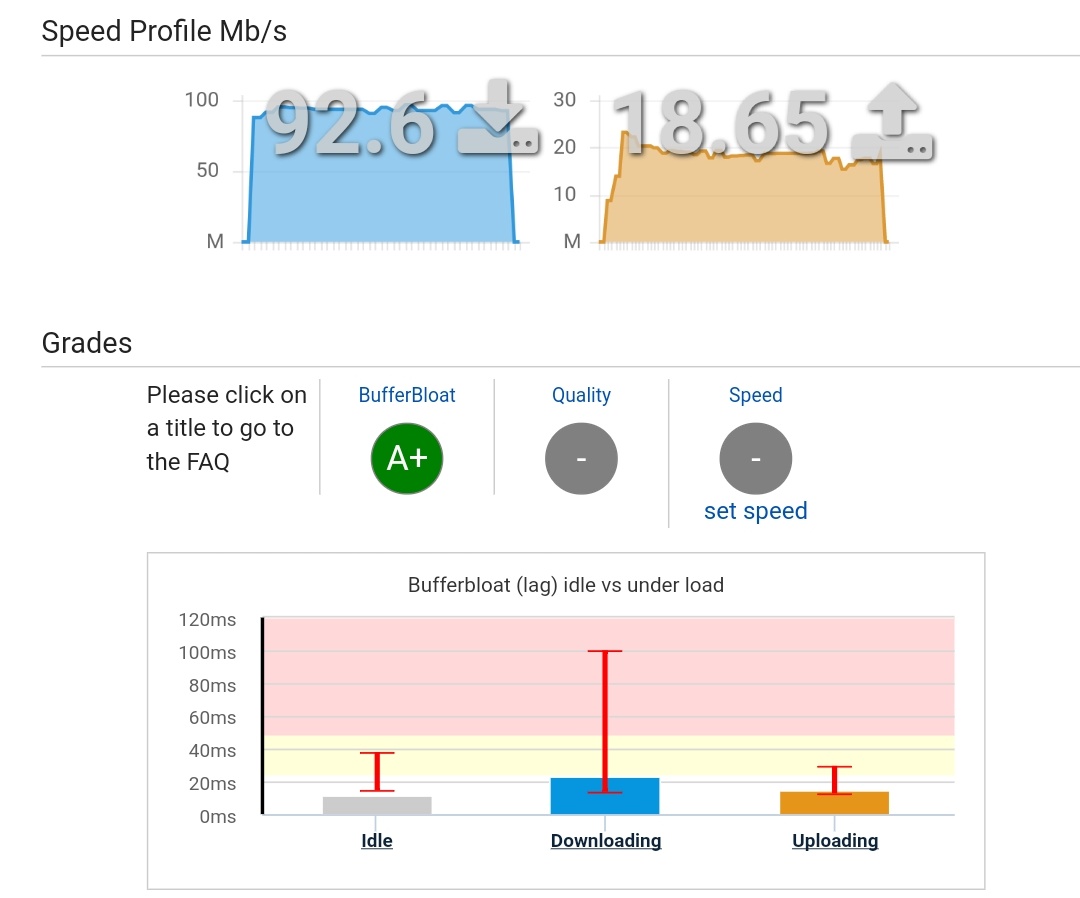
With SQM on, I have reduced bufferbloat on dslreports. If I do not use the high-res bufferbloat option I get A+. Without SQM I get A.
But when I use Shadow, my latency still noticeably increases and stutters when Netflix loads a new episode or skips to another time.
Here is one of my dslreports results. With standard test settings I get A+ consistently. How is it possible I am still experiencing stutters when someone uses Netflix?
Hey, forgot to mention something that might be important.
I am streaming the 40Mbit Shadow stream wirelessly to the an Oculus Quest, on Wifi AC.
Netflix is both wired on Chromecast Ultra, and wireless on phone/tablet. Netflix causes stutters in the wireless 40Mbit Shadow stream both wired and wireless.
use firewall rules to add DSCP = CS6 to your game packets, this will induce them to go over the VOICE queue on WMM enabled wifi, which will give you lower latency on wifi.
Is this something that might help? I should look into how to actually do this...
I would follow the sing and dance section and see whether per-internal-IP fairness helps. My gut feeling is that it might help a bit, but not completely (it should isolate you well against 1 concurrent user, but not two, as the fair share for 3 users will be ~33Mbps). For anything else things get tricky as iptables can only run after sqm's default ingress-via-IFB. So please try the per-internal IP fairness first and then let's take it from there...
If the concern is mainly wireless contention, then marking just your one stream CS5 will put it into the VIDEO queue on the AP, which is probably the appropriate place for such a bulky stream. It will do that regardless of the fact that it isn't processed by SQM due to the IFB. it might be worth a try after the per internal IP fairness @moeller0 suggests.
This is actually a no-op, only the ingress keyword changes cake's behavior, I did not even realize we had "egress" as keyword, but sure, we do and it is the default.
This is a bit of a mixed blessing, ack-filter does help with highly asymmetric links and also with highly bursty links (but cake as used in SQM typically does not see the burstiness, so this component of ACK-filtering will not come into play). But unless your uplink gets overloaded this will have very little effect on your actual issue, so by all means keep this setting ;).
Well, the crux of the matter is, that sqm replaces the ISPs under-manages and over-sized buffers with its own advanced queue/buffer management, to reduce the latency-under-load increase (aka bufferbloat). For this to work, sqm needs to only admit at maximum as much data per time into the ISP's equipment (in xDSL systems, modem/CPE and indirectly dslam/msan) as that equipment can actually transmit over the bottleneck link, so that these ISP-buffers never fill up continuously to unhealthy levels.
To do this SQM needs to calculate for each packet it admits how much time/instantaneous bandwidth this is going to require on the bottleneck link. For packet based data transmission each packet carries a payload, as well as a bit of overhead required to actually transport the packet (this is loosely like sending a parcel, where the packaging/labeling adds weight and volume to the content and its the combination of both that needs to fit into the carrier vehicle volume and weight wise), for sqm to make an accurate prediction of the transmission time it needs to know the payload size (which is easy as the kernel typically has that information at hand) as well as the applicable overhead. And that second value is tricky to get, as the SQM-host might not be directly connected to the actual bottlenech link and hence is in no position to know the actual overhead itself. This is why we need to manually configure that per-packet-overhead, it is also immensely tricky to empirically measure that overhead robustly and reliably (we have a method that works for ATM/AAL5 based carries, but these are a dying breed, land IMHO rightly so).
Now, what happens if the overhead is under estimated? Typically people are advised to set the per-packet-overhead to the best of their knowledge (and err on rather a bit too much) and then measure the bufferbloat resulting from different shaper bandwidth settings. This is a reasonable approach, but let's see what happens when we under estimated the per-packet-overhead (for demonstration purposes I am estimating this as 0, but the principle will hold for any under estimation, just the consequences will be rarer/subtler), I will shamelessly use simple values here but assume VDSL2
"Optional encoding" differs between link technologies and equals 64/65 for VDSL2@PTM
Side-note: ATM/AAL5 is weirder and can not really be modeled with a simple encoding factor, but that is not your issue.
So assuming a IPv4/TCP measurement without any extras and for a true bottleneck gross rate of 100 and a true per-packet overhead of 30 on VDSL2 we get a goodput of:
if we use this as our real achievable top-speed we can calculate which shaper gross rate we would need if the per-packet-overhead is set to 0 instead of 30:
93.96 * 65/64 * ((1500)/(1500-20-20)) = 98.04
setting the shaper to 98.04 units will control bufferbloat, BUT only if the paket size is 1500 Bytes. If we just redo our calculations for a packet size of 100 bytes we get:
100 * 64/65 * ((100-20-20) / (100 + 30)) = 45.44
and
45.44 * 65/64 * ((100)/(100-20-20)) = 76.92
but since we set the shaper to 98 we will be admitting too much into the ISP's devices and hence bufferbloat will increase again. Depending on your actual mix of packet sizes on your link this issue will be more or less prominent, but it always lurks as a danger-pit unless your per-packet-overhead is equal or larger than the real per-packet-overhead. I hope this answers your question.
Hard to say, as above, I have no simple and reliable way to actually empirically measure the applicable per-packet-overhead, but according to ITU specs, VDSL2 will only give you 22 bytes of overhead (PPPoE would add another 8, but IPoE does not use PPP tunneling), an potential VLAN tag would add another 4 bytes (and some ISPs use double VLAN tagging). I would guess that 30 should be a decent estimate with a high probability to slightly over- instead of under-estimate, so exactly what you should do.
Thanks again @moeller0 for your reply. Very informative! I just tried some other values for overhead but they do not seem to make a big difference on the bufferbloat results on dslreports. It is also hard to say because my bufferbloat results are a bit inconsistent anyway. It is always A or A+ but there seem to be random bufferbloat spikes: sometimes in Idle, sometimes in download, sometimes in upload, and sometimes in neither. The spikes are also at random moments: sometimes at the start of the test, in de middle or in the end or multiple. The spikes are short and sometimes not even detected for the scoring. Are these random spikes weird?
In short, from what I read, the keywords I have in place are OK to configure per internal IP fairness. I also tried playing VR with these settings and unfortunately the video stream still stutters when starting Netflix. Without Netflix on it is perfect. The stutter is not random like in dslreports. It is perfectly synced with someone starting a Netflix episode.
one thing to note is that the wifi drivers for the wrt32x and friends are abandoned and the mfg sold that business so it's unlikely to get much better. they are kind of ok for everyday use but definitely not without their problems.
you are washing DSCP on ingress which is good... I would try adding CS5 to your one gaming stream and see if it helps with WMM priority.
Thanks @dlakelan. Do you have a link describing how to do this? This is really new to me. How do I identify the gaming stream? Based on IP of the gaming device?
edit: If this is too complicated or simply too much work to explain to someone who is basically used to GUI's, also just say so.
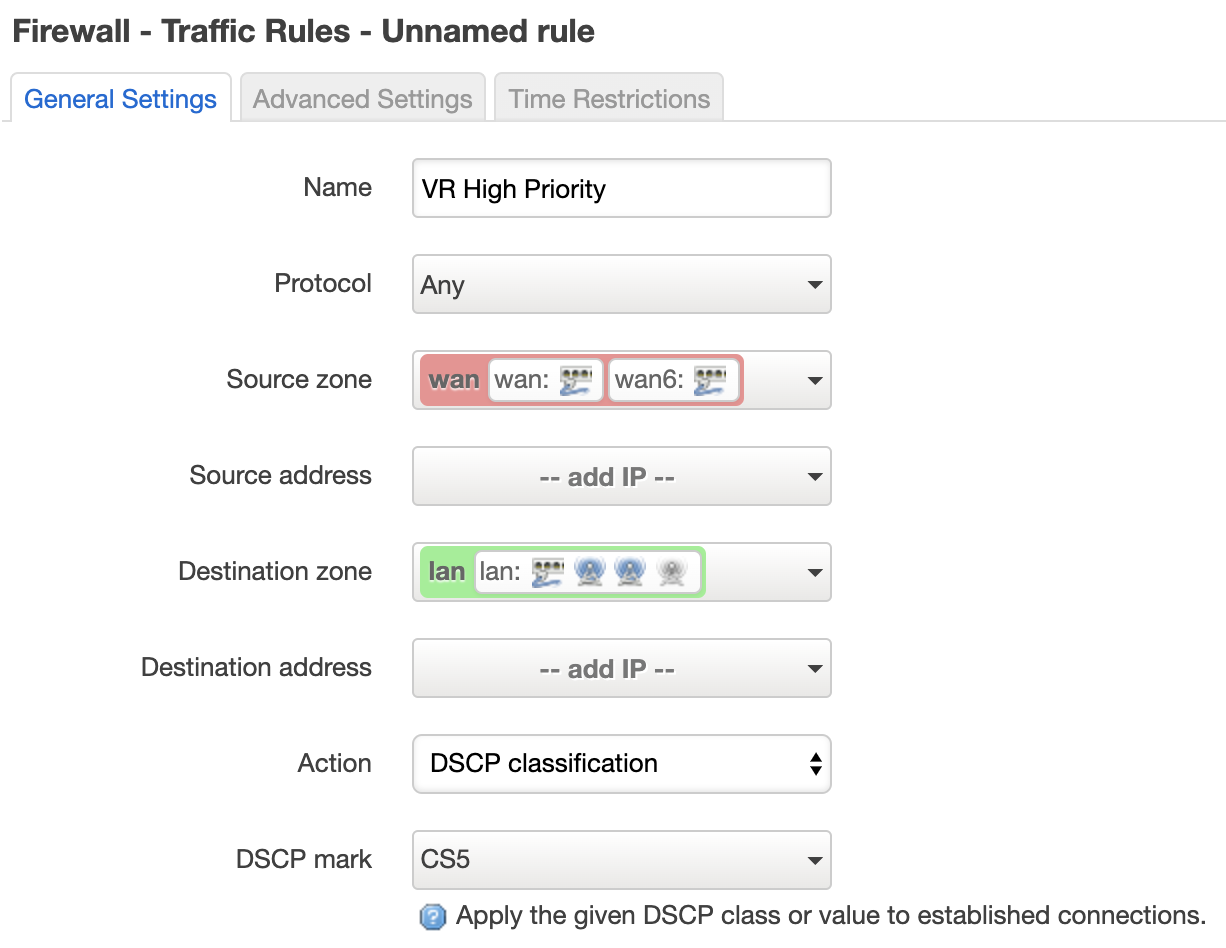
It should be possible to do this in the firewall LUCU GUI, in the action drop down list, select DSCP classification, and set the other fields accordingly...
like @moeller0 said, it can be done in the GUI. you can identify the stream as UDP (most likely) coming from the IP address of your shadow PC server. you could probably do well by tagging everything going to or from that IP honestly as you probably want to prioritize your control stream on the upstream side as well.
Source address - I did not show it in the screenshot, but I should click the only non-local IP address right? The modem it's IP, correct?
Destination address - The local IP of the Oculus Quest to which I am streaming
Correct? Should I change something else?
To me, this feels a like setting classes/priorities like I am used to in QoS, before I got to know SQM. Is this like QoS inside cake? And, did I read something about needing to change to 'layer cake' instead of 'piece of cake' to get these DSCP marks to work?
And one last question, would it be beneficial to set a low DSCP mark for Netflix, or the Chromecast Netflix is streaming to?
EDIT: Reading a bit about DSCP Markings I noticed the configuration quidelines table on wikipedia. The last column is AQM, which equals SQM right? The row for CS5 notes a 'no' for AQM. The 'AFxx' markings note 'Yes, per DSCP'. Shouldn't we be using those then?
you probably want 2 rules, one would use the destination address as the address of your server in the data center, the other one you should use this as the source address. You'll have to type those in manually not click an option in the menu.
You could use layer cake on the upstream / upload setting of your SQM which would enable you to utilize these marks when sending your packets to the server in the cloud.
I recommend CS5, the DSCP system is pretty absurdly nonstandard. CS5 will hit the WMM VIDEO queue typically. that's where you want it.
My Shadow cloud PC in the datacenter is a Windows PC. I just logged in and asked Google: 'What is my IP?'. It showed me 'Your public IP address is ...'. I guess that is the IP I need to have in the rules right?
'Down' Rule - Source: Public IP Shadow PC + Destination: Local IP Oculus Quest
'Up' Rule - Source: Local IP Oculus Quest + Destination: Public IP Shadow PC
The zones should still be wan for Shadow and lan for Oculus, right?
Why do you say so specifically layer cake on the upstream? Not for downstream? In the SQM QoS setting I can select these at the Queue Discipline tab and then Queue setup script. But I guess that sets it for up and down? Right now it is set to piece of cake.
Because on the downstream you are "wash" ing your DSCP so all the packets will go into the best effort tier anyway. And there's no way to change this, because the IPtables commands run after things queue in SQM.