I've been using SQM (layer cake) for several months now on my WRT3200ACM with 100mbps WAN connection, which has been great - getting A ratings from DSL Reports. However I recently upgraded to 350mbps WAN package.
I cannot get SQM to work with the new connection speed. I tested with no SQM to get baseline values (which I was very pleased with at an average of 360mbps however C rating for buffer bloat). So I set my SQM inbound value to 330mbps however when I test I get a very erratic connection, the download speed fluctuautes wildly up and down between 150mbps and 250mbps, never gets anywhere near 330mbps and the buffer bloat rating was worse, Ds and Es.
THinking I might be maxxing the router processor I ran htop while running the speed tests a few times, but it never went over 45% CPU and never over 55% RAM usage.
I tried a few different SQM configs (piece of cake and simple) but they were even worse.
Is there any other hardware/software limitation that might be causing this errattic SQM behavior? I've reverted to running without SQM for now.
Do you have a dual processor router (or a single core with hyperthreading)? Because 50% would be 100% of one core, and SQM doesn't distribute over multiple cores. We've seen this a bunch in the last few months, people getting faster connections and SQM can't keep up because of CPU issues.
EDIT: I see you mentioned the WRT3200ACM, and YES it is a 2 core processor, so in fact you're hitting the CPU limit. I've been saying this for months now, that even high end consumer routers can't handle more than a few hundred mbits, people don't quite believe me yet
If you want to shape more than 300 mbit/s the best way to go is low end x86 based computer with dual LAN.
or
for example.
On the other hand, you could try doing a binary-search between 100 mbps and 300 mbps and see what speed you get acceptable performance at.
My Dir-860l is able to shape at around 650-700 mbit. I got better results with fq_codel than cake. Your router shouldn't bottleneck at only 350 I would say. It is much more powerful.
I agree with the theory that most likely the CPU running the actual shaper is out of cycles and what you see is cake failing... When you tried simple/fq_codel what was worse, just the achievable bandwidth of also the latency under load?
You could try to still run sqm on egress (by setting the shaper-speed for the downstream direction to zero, this will NOT shape down to 0 Kbps, but will instead not instantiate the downstream shaper); that should be somewhat better than no shaper...
I also wonder whether it would be possible somehow to separate ingress and egress shaping to different CPUs to gain a bit more headroom... But in the end shaping is costly and you need hardware that has cycles to burn, so +1 for @dlakelan's advice to look past the traditional home router platforms for high-bamdwidths links. You still should be able to press your 3200ACM into duty as wireless AP, which the x86 boxen typically do not do well out of the box (many lack WIFI at all).
My WRT3200 is pretty new tho, wasnt about to buy a new router any time soon...
Well... any suggestions ? I wouldnt want to go for something with an Intel CPU
Other than intel cpu the WRT3200ACM is probably one of the best. There's just no getting around the fact that considerable CPU is needed for this task. 300 Mbps is at least 25000 packets per second, if the packets are smaller then it's more than that. Gigabit is 83000 packets/sec
at 1.5Ghz and 1 Gbps there are around 18000 cycles per packet, that has to be enough for handling all the interrupts, copying the packets into buffers, queueing them, doing shaper calculations, and dequeing them into the tx buffers, etc. not to mention kernel thread scheduling and etc etc
On my x86 I use 2 bonded nics into a VLAN switch. I shape on the output of bond0.99 (WAN) and output of bond0.1 (LAN) using a custom HFSC + fq_codel scheme. There is no IFB interface. I wonder if this has the side effect of balancing loads better across CPUs. I wonder if something similar could be done here?
In all honesty why not just disable shaping so you get the full bandwidth? I have no bufferbloat problems whatsoever and I have all that crap disabled to max my internet connection.
@phinn clearly you either don't do VOIP or play games, or... you have an upstream ISP equipment that's already handling shaping and latency control for you.
On links at say my local YMCA I've seen delays under load exceed 5 SECONDS. So imagine you load a web page and just to look up the DNS entry for the site takes 5 SECONDS before anything happens. Yes, that kind of bufferbloat is easily achieved.
EDIT: it's really even worse than this. here's a typical situation:
make connection to example.com request front page, 5 seconds
look up 4 or 5 additional DNSes to load scripts from CDNs etc 5 seconds
load scripts: 5 seconds + download time
Display page: something like 30 seconds after you originally click "go"
EDIT: all it takes to cause this is for say one person on the public Wifi to take a 1 minute video of their kids and have it auto-sync to Google Photos or the like, for the next minute or two the connection exhibits 5000 ms of bufferbloat.
I do play online games, mostly PUBG and use Discord with the crew. No latency or bandwidth issues whatsoever with all of that disabled on my 250/50 Mbit cable. DSLreports speedtest reports an "A" for bufferbloat too.
It's conceivable that for some hardware, the 3.1 standard is achievable just with a firmware upgrade, so it might have been rolled out to you without your knowing it
In any case, if you can play a games + do VOIP over your link, and uploading or downloading a large file doesn't completely knock that offline, then someone somewhere in your link is doing queue management, whether it's at the head-end or in your modem, it is being done. Without some kind of smart queue management, it's trivially easy to get hundreds of ms of latency (totally destroys VOIP or games) and even not that hard to get thousands of ms of latency particularly on slowish DSL links with stupid vendor firmware.
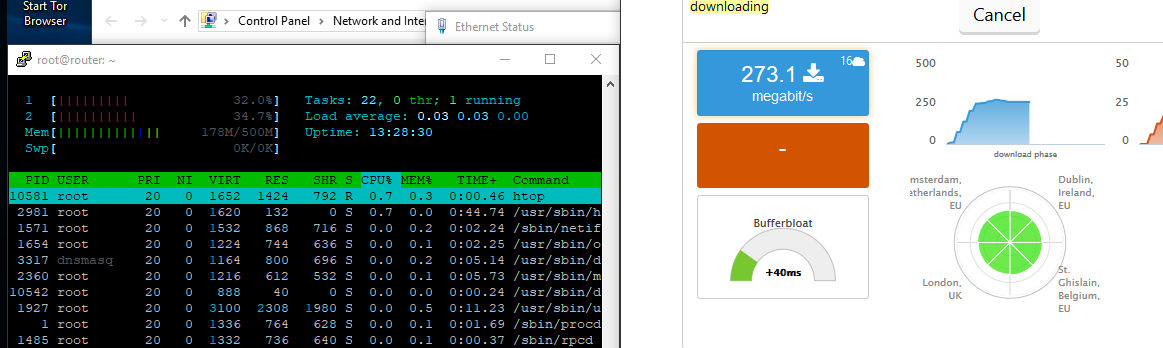
Thanks for the feedback and the theories. I actually think it is not processor related - AFAIK htop reports each core seperately - here is a screenshot during speedtest:
It seems to be spreading the load evenly between the cores. Unless there is something jazzy going on with the way htop is reporting CPUs.
Actually just because I was noticing with background downloads running regualar browsing was becomming very sluggish. I was getting 800ms plus latency.
Queuing doesn't use multiple CPUs much, but it also isn't pinned to one CPU, so it may bounce back and forth. You really need a better breakdown. Fortunately we're working on speed testing, perhaps you can be a guinea pig. First off set your speed such that cake does in fact work well, perhaps 200 Mbps or whatever. Then run our test script, and do a speed test.
Test script is here, version modified by @moeller0