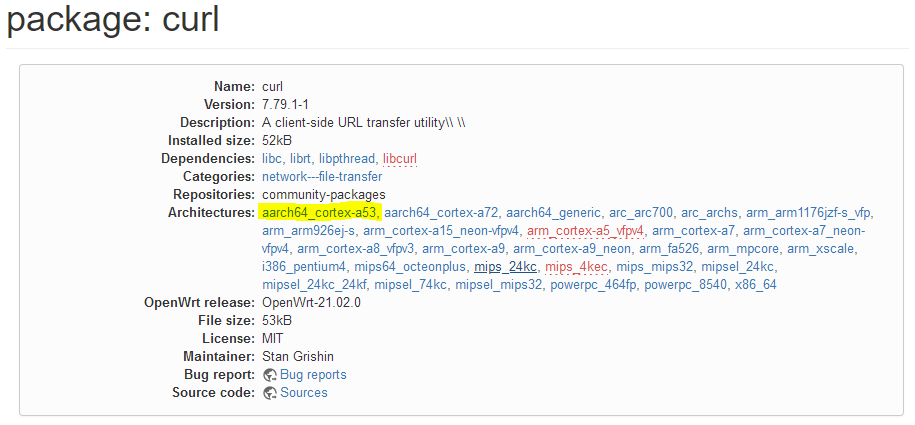
The package pages, like this one: https://openwrt.org/packages/pkgdata/curl list the OpenWrt version/package version from the current release branch (21.02 ATM), however if you follow the links to the architectures they lead to the snapshot packages.
Would it be possible to include a section called Binaries, which would be the same list as Architectures but pointing to the actual IPKs? I've been talking to curl people (their download page links for OpenWrt are hilariously outdated) about having the OpenWrt links up-to-date and they use HTML scraper so having a new section called Binaries would be the easiest way for them.
I thought if you could add Binaries section and in that section when I click on aarch64_cortex-a53 I want to download the curl ipk for this architecture.
If Architectures sections serves no purpose currently then maybe it can be renamed/changed.
In principle this should be doable, if @bobafetthotmail has the links to the packages available.
Questions which come to my mind:
Are there really that many people manually downloading packages (instead of just installing them via opkg)? Just asking, since I have no idea how often this is done.
Should we really invest time in the current package table (which is painfully slow), or rather think about a more performant solution?
it is possible, yes, it would require some modification to the script that indexes the packages.
why curl people need direct access to OpenWrt package binaries? Can they just tell people to opkg install curl on OpenWrt?
and if they are scraping HTML why not scraping the download server landing page https://downloads.openwrt.org/ to find whatever is latest version and the list of targets, then you can assemble the download link for the package (again in the download server that you can also reach by just clicking around if you are not a scraper bot limited to text)
I mean, I'm already scraping from that site and from manifest files anyway, it makes little sense to scrape to create a html that is scraped again by someone else that could just scrape the same source instead.
Also people that want to download packages manually should go there.
EDIT: My intent here is not "brushing off" anyone, it's just that the OpenWrt wiki is not meant for machine interaction, if you need interfaces for machine interaction there are better ways (that I also use to create the package lists) so if that is required just ask for that directly and we can explain how or if it's missing we can create it. For example in the past I sent a PR to the OpenWrt build system to keep a "verbose" version of the package manifest text file in the download server that is used only for my script to read/parse information. for example this https://downloads.openwrt.org/releases/21.02.1/targets/x86/64/packages/Packages.manifest
Also I think aparcar has a more modern system based on json and python or something, which is probably better suited for more modern tools. https://github.com/aparcar/openwrt-json
Because that's how their download page is designed: https://curl.se/download.html. We can have it listed outdated versions as things are now, not listed there at all or try to provide a way for them to scrape/list supported architectures/packages. I offered shell script to manipulate their DB directly, they prefer to scrape some of our pages instead.
Because my understanding is that that's not how their scraper works.
If it's too much trouble to add a Binaries section, they can scrape the package page, the problem is that it lists release OpenWrt/package version however the links lead to the snapshots packages which can be a different version.
I find it hard to believe that people making Curl of all things can't write a couple one-liner shell commands that wget/curl the page and grep/awk the raw HTML text in a shell script.
I can create a page with the information they need, even if I really think they should be able to do this themselves.
Not in https://openwrt.org/packages/pkgdata/curl but in a new article. As said also by Tmomas, that page is part of package table infrastructure and unless we want to add package download links to every single package (and we really don't want to, as it will degrade performance of the package table significantly), that page will be left as-is.
This new page will be updated automatically by a dedicated script that runs on its own (still on the wiki server) and will do this only for Curl package, at least for now.
So please tell me what you want exactly on the page or even just create a stub of it in the wiki and I'll hook it up to a script this weekend.
I don't think it's that they can't, it's just that they probably wouldn't for a single distro that they were comfortable to list very outdated links for a while for.
I see. If it's too computationally expensive to append the existing page, I think we'll have to live with the fact that sometimes the version numbers would be out of sync.
I was just pointing out that I'm fully aware that what you wrote is not the real reason
No, that's not the problem.
The existing page is part of a larger system written by a script and backed by a database used in a somewhat debatable way by a dokuwiki plugin to create and show the package table. https://openwrt.org/packages/table/start
I can create a new wiki page with all data you want on it. It is not "computationally intensive".
I'm not going to add stuff to existing pages used by another system that is slow and bloated already unless it is really necessary, and imho it's not the case for this request.
I don't like the implications of that statement, so I'm going to conclude my participation in this thread. Everything I've had to say on the subject has been stated in the OP.