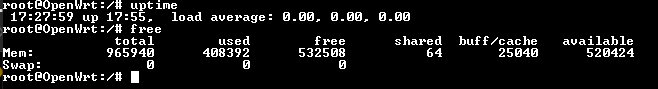I'm not sure we'd want to enable the process count restriction by default. I suspect it is only necessary when large adblock lists are being used. A setting of 1 is quite aggressive, meaning that only a single child process can be forked to handle tcp requests
A more robust solution might be to add functionality to luci's dnsmasq page to allow it to be configured, but leaving it unset by default, so not changing the init.d script...
I just needed to put something in there so it was recognized, as I know the discussion said for sure that setting it to 1 made the issue go away.
Since the default is 20, and the min would be 1, what would be the safe middle ground as a default? 3? 5? 10? Just leave it out of the dhcp config entirely? Will that leave it to the default?
Yes, just leaving it out entirely would be the way to go. That will leave it on default settings of 20.
If this is the cause of your problem, it's likely only to occur when a large adblock list is being used AND DNS lookups are being made over TCP.
Probably the kind of thing that should be documented in the wiki so that anyone experiencing oom-killer crashes of this nature can go and set the parameter.
It would probably be quicker if you were to first establish exactly how many times the process can fork before you're out of memory. In the thread where I originally posted the dnsmasq patch, I mentioned how you can use netcat to determine this. Just setup a loop in a shell script that will netcat -t 127.0.0.1 53 and see how many times it iterates before you're out of memory. Once you've determined that, then configure an appropriate max-procs value and leave it running to see if it still falls over
I need to get video capture of it, but something is very off with this.
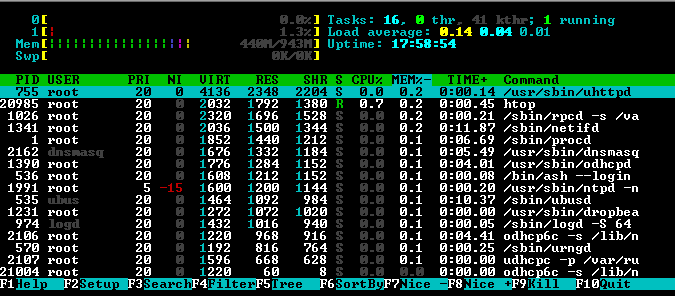
If I manually run netcat -t 127.0.0.1 53 & a few times from SSH, I can hit the max 20 process forks without issue.
The moment I run a script (see below), I can watch the memory leak happen. This happens even with only ONE instance running. The memleak stops the moment I kill the script below, but it do NOT free the RAM. Again, this does NOT happen if I manually invoke netcat -t 127.0.0.1 53 &. I know there is a memory leak, but I'm not sure it's in dnsmasq, I think it's just manifesting in dnsmasq
Hard to tell what's going on here, but maybe this is a symptom of a race condition of some form? That script you quoted was designed as a denial of service, so the key difference is that it executes much quicker than your interactive commands. What happens if you put in a sleep (2 seconds should be good) just before the netcat command?
I've enabled CONFIG_KERNEL_SLABINFO, CONFIG_DEBUG_KMEMLEAK
and the slabtop utility.
Even without loading anything other than boot, I get http://hastebin.com/vegoranozu.yaml over and over.. So, something else is going on. I'm still trying to stablize things, so I've not put the sleep stuff in yet for testing.
To be honest, I do not connect "DNS cache" with the "DNS ruleset".
I think that "DNS cache" in this contexts mainly means the cache of the fetched addresses, so that already fetched add site IP addresses get cleared along the ruleset update and the new ruleset gets immediate effect.
But I do not mentally connect it to the static adblock ruleset.
Two ideas for you:
clarify the help text. Maybe add a note about the RAM duplication
tweak abdblock to mitigate the problem with the ultra-large rulesets. For example, if the amount of blocked hosts is over 200k addresses (??), the cache gets cleared by default. Or something like that. Needing a half-gigabyte RAM footprint for adblock lists is crazy in any case, but we might try to be somewhat helpful for those who use gigantic blocklists.
I honestly don't think this is an adblock problem. With nearly 800k blocked domains, the compressed backup was only 10Mb.. even with text compression, the lists aren't going to be THAT big.
This appears to be a memleak somewhere manifesting in dnsmasq, and I've got no idea how to track it down yet.
The dnsmasq runtime config including the list of blocked hosts is stored in /tmp, i.e. on tmpfs.
The size of /tmp is smaller than RAM and I'm not sure if its compression level is good enough if any.
Apparently the config is loaded to RAM uncompressed, otherwise it wouldn't consume so much RAM.
It's the stock network setup, including DNS/DHCP, but shrug. Got suggestions on 1) Which upstream? 2) Best way to try and figure out where the leak is?
So, I put the 5.4 kernel on the device and have witness no apparently memory increase.
@adrianschmutzler: It appears to be something with the 5.10 kernel and the main branch on the Octeon target. I was mis-attributing the issues I was seeing. Suggestions would be welcome.