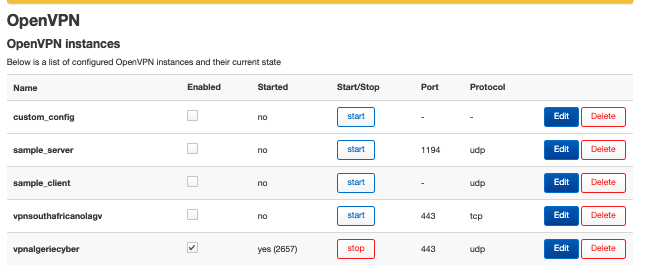
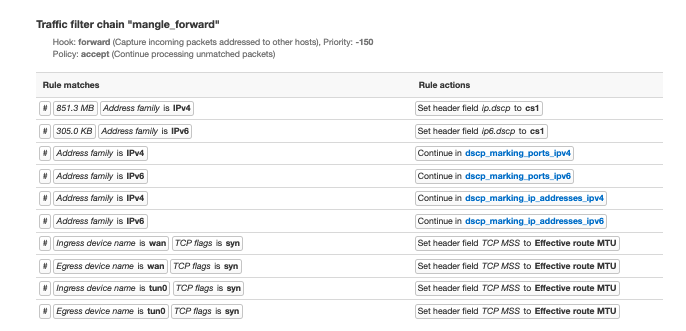
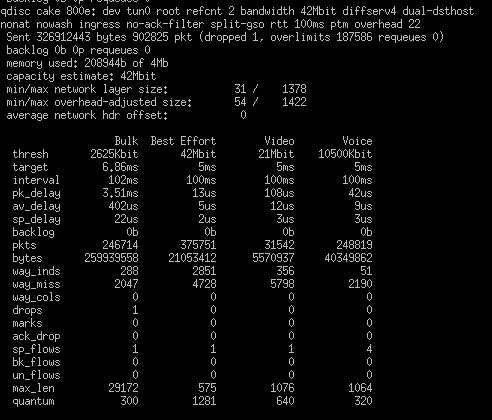
Your knowledge of all this obscure networking stuff is rather intimidating! Your suggestions seem to be helping push the needle. Here are my findings.
root@OpenWrt:~# tcpdump -i ifb-ul -vv host 1.1.1.1
tcpdump: listening on ifb-ul, link-type EN10MB (Ethernet), capture size 262144 bytes
20:47:09.022506 IP (tos 0x0, ttl 128, id 40952, offset 0, flags [none], proto ICMP (1), length 60)
XXXX.lan > one.one.one.one: ICMP echo request, id 1, seq 101, length 40
root@OpenWrt:~# tcpdump -i vpn -vv host 1.1.1.1
tcpdump: listening on vpn, link-type RAW (Raw IP), capture size 262144 bytes
20:47:58.913343 IP (tos 0x0, ttl 127, id 40956, offset 0, flags [none], proto ICMP (1), length 60)
YY.YY > one.one.one.one: ICMP echo request, id 1, seq 105, length 40
Without counters:
root@OpenWrt:~# nft list chain inet fw4 tagin
table inet fw4 {
chain tagin {
type filter hook ingress device "br-lan" priority mangle + 1; policy accept;
ip dscp set cs3
ip6 dscp set cs3
ip protocol udp udp sport 123 ip dscp set cs6
ip6 nexthdr udp udp sport 123 ip6 dscp set cs6
ip protocol icmp ip dscp set cs5
ip6 nexthdr ipv6-icmp ip6 dscp set cs5
udp dport { 7000-9000, 27000-27200 } ip dscp set cs5
udp sport { 7000-9000, 27000-27200 } ip dscp set cs5
ip6 nexthdr udp udp dport { 7000-9000, 27000-27200 } ip6 dscp set cs5
ip6 nexthdr udp udp sport { 7000-9000, 27000-27200 } ip6 dscp set cs5
meta priority set 1:40
ip dscp { ef, cs6 } meta priority set 1:10
ip dscp cs5 meta priority set 1:20
ip dscp { af41, af42, af43 } meta priority set 1:30
ip dscp cs2 meta priority set 1:50
ip dscp cs1 meta priority set 1:60
ip6 dscp { ef, cs6 } meta priority set 1:10
ip6 dscp cs5 meta priority set 1:20
ip6 dscp { af41, af42, af43 } meta priority set 1:30
ip6 dscp cs2 meta priority set 1:50
ip6 dscp cs1 meta priority set 1:60
}
}
With counter on icmp:
root@OpenWrt:/etc/nftables.d# nft list chain inet fw4 tagin
table inet fw4 {
chain tagin {
type filter hook ingress device "br-lan" priority mangle + 1; policy accept;
ip dscp set cs3
ip6 dscp set cs3
ip protocol udp udp sport 123 ip dscp set cs6
ip6 nexthdr udp udp sport 123 ip6 dscp set cs6
ip protocol icmp ip dscp set cs5 counter packets 0 bytes 0
ip6 nexthdr ipv6-icmp ip6 dscp set cs5 counter packets 2 bytes 144
udp dport { 7000-9000, 27000-27200 } ip dscp set cs5
udp sport { 7000-9000, 27000-27200 } ip dscp set cs5
ip6 nexthdr udp udp dport { 7000-9000, 27000-27200 } ip6 dscp set cs5
ip6 nexthdr udp udp sport { 7000-9000, 27000-27200 } ip6 dscp set cs5
meta priority set 1:40
ip dscp { ef, cs6 } meta priority set 1:10
ip dscp cs5 meta priority set 1:20
ip dscp { af41, af42, af43 } meta priority set 1:30
ip dscp cs2 meta priority set 1:50
ip dscp cs1 meta priority set 1:60
ip6 dscp { ef, cs6 } meta priority set 1:10
ip6 dscp cs5 meta priority set 1:20
ip6 dscp { af41, af42, af43 } meta priority set 1:30
ip6 dscp cs2 meta priority set 1:50
ip6 dscp cs1 meta priority set 1:60
}
}
So packets '0' indicates a problem I think? Any idea what's wrong? Am I missing certain required packages? This is with a very recent 22.03 snapshot on RT3200 but I may well not have certain required kmod? packages.