Well, your ISP is the party responsible for getting your packets to/from the internet. If they route all your traffic that should be inside their own network though italy and germany, they should also be able to fix that? I guess I am still not understanding the point, maybe you explain this verbosely in French and I run this through a translator?
+1 for that.
If ISP handles their trunk routing badly and does not fix it, there is not much you can do, except change the ISP...
@moeller0
Voici le traceroute en question :
guest@dnstools.ch:~ traceroute 85.6.216.23
1 100.88.96.129 (100.88.96.129) 0.324 ms
2 core24.fsn1.hetzner.com (213.239.229.53) 0.341 ms
3 juniper5.nbg1.hetzner.com (213.239.252.245) 2.631 ms
4 ael2-499.nbg40.core-backbone.com (81.95.15.5) 2.839 m
5 ael-2001.fra10.core-backbone.com (81.95.15.162) 5.919 ms
6 *
7 ae2.11 edge1.MilanI.level3.net (4.69.162.225) 30.606 ms
8 Swisscom-level3-Milan1.Level3.net (4.68.73.202) 14.890 ms
9 i691ss-015-ae21.bb.ip-plus.net (138.187.130.241) 17.407 ms
10 i68gem-015-ae1.bb.ip-plus.net (138.187.130.162) 18.240 m
11 *
12
Quick note dnstools.ch does not seem to be part of your ISPs network, and in that case weird routing is not totally unexpected (routing mostly follows the path of least costs, and swisscom, like Deutsche Telekom are known to be cost-neutral peering adverse). That ISP technician should run the traceroute from within the swisscom network...
1 Like
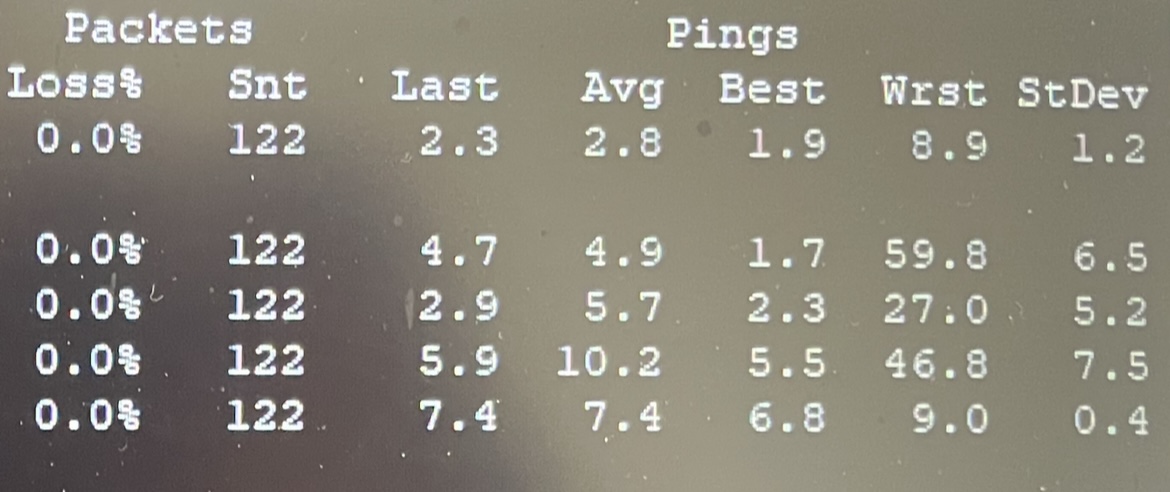
Mtr on a game server, what's your opinion on these 6 hops... the ms in the wrst column is permanent and gets worse over time!
If we take an average of 250 packets per second, each small packet of 80 to 120 bytes will take (X) ms, is that enough to be logically late?
Without the actual addresses/hop numbers and information where these are located along the path from the server to your client, I can make not even an educated guess. All I can offer is wild speculation...
The way I look at this is mostly: if the delay numbers (including Wrst) between the machine running mtr and the remote end-point, which here would be your router/gaming machine?, stay low enough, here 9.0 ms compared to 6.8ms best then all is well, intermedoiarey hops can do what ever crazy thing they like (so mostly dropping or delaying mtr probes terminating at that hop), unless the packet loss or increased delay numbers carry trhough to the end point.
Not really, this test shows a maximum delay range from 6.8 to 9.0 ms for a total spread of 2.2ms. If these 2.2 ms have a noticeable impact on the network performance of the game, I would certainly stop playing that game over the internet..
That said, the way I think these games work is that each client will send control packets when ever something changes (or maybe even on a fixed tic even without changes sort of as a keep alive). The server will include these into its game world state updates if they arrive early enough (with what early enough means depending on the server implementation) and hence any action they encode will influence the world state and will be incorporated into the packets the server then sends to the clients to update their world state.
My (probably too simplistic) solution to this challenge would be to run an NTP client with in the game to make sure each client can operate with absolute time stamps. Then use these timestamps to delay all client control packets such that all clients experience the same delay (for a given match group, it makes sense to e.g. group players with say ~10ms RTT with each other, and less sense to group players with 10ms together with others with say 100ms, but even that would work in my scheme). Then send the world update packets out with associated absolute times and have the clients wait to account for these packets until absolute time is equal or greater to world simulation time. (The first delay is needed to account for different OWDs from clients to the server, the second to deal with different OWDs from server to clients). I guess servers are hot commodities that need as little processing as possible, so both of the OWS equalization stages conceptually could be folded into the client software and only run simple small dejitter buffers on the server... Again, this is likely not actually solving the problem game developers actually face.
I find the global state of time stamps interesting, I note with interest that the ntp protocol very often changes priority state at the DSCP level, the NTP protocol shows in wireshark DSCP classes such as: 4 I don't know what this DSCP corresponds to, both cs0 and also cs6 its changes occur as much on the source as the destination ... the ICMP probe also travels between cs6 and cs0.

yes is very good idea, a lot of streamer make this
@dlakelan
@moeller0
In 3 years what has immediately brought me an improvement is not to prioritize udp the port where IP games but to classify and calm protocols tcp as http and https and quic .
ISPs do tyoically make no guarantee what happens with DSCP != 0 packets... my ISP actually demands (but does not enforce) that all packets send by me are set DSCP ==0. I expect that there might be fast path processing for DSCP 0 while other DSCPs might not... By leaving the game's DSCPs alone you might not trigger the ISP slow path for those.... (if that is true, also just setting the wash keyword on the egress cake instance should work, and in that case both setting TCP/HTTP(s)/QUIC to background priority or setting the game to Video or Voice priority should both work equally well*).
*) Could you actually try that, please?
By default my isp uses Best effort .
When diffserv 4 or diffserv8 is active the packets are all thrown into the Best effort column and some packets into the maximum priority column like Tin7 .
In my simple script I use ip dscp != 0x0 counter ip dscp set 0x0 comment "Reset incoming DSCP to 0" which resets the DSCP like IPTV (af41) if I do a Speedtest I very quickly have 50,000 packets drop.. then I classify http and https in af12 sometimes af21.. and I've seen that 160 packets drop..that's when the responsiveness of the menus and my gameplay is greatly improved.
Yes that is what is coming from your ISP, my question is what do you send from your side towards your ISP?
I send to my isp af12 for https and http that's all!
Try not doing that, use DSCPs locally to steer packets into the desired cake tins, but then use the wash keyword so no DSCPs escape toward your ISP.... I guess we need to devise an easy test that allow to see what happens when using different DSCP values... however that requires a remote end-point that is willing and able to report which DSCPs it actually received....
nft -f /dev/stdin <<EOF
table ip cake {
chain prerouting {
type filter hook prerouting priority filter; policy accept;
ip dscp != 0x0 counter ip dscp set 0x0 comment "Reset incoming DSCP to 0"
This command is correct for local DSCPs, isn't it?
nft add rule ip cake prerouting ip dscp 12 set tin 2
I have to use "wash" on the WAN interface, does this mean that the DSCPs are reset just before the packets leave my home network and head for my ISP ?
Yes, with wash cake will look at the DSCPs to steer packet into its different priority bins, but will then reset all DSCPs to 0, so you get the benefit of conveniently use DSCPs in your home network without leaking your internal DSCPs upstream. According to the IETF RFCs this should not be necessary, but it might well make a difference. I think I saw reports here that for some ISPs some specific egress DSCPs will result in higher drop/loss probability or higher delay/jitter (the second might come from the ISPs own re-marking actions which might simply take more time).
Note: DSCP were intended to be also usable end to end, so washing should not be necessary and there are ambitions of making (a few) DSCPs usable end to end, but these efforts have not yet really been tested over the internet....
here's a simple starter version, do you think it's right to start with?
nft -f /dev/stdin <<EOF
table ip cake {
chain prerouting {
type filter hook prerouting priority filter; policy accept;
# Reset DSCP for incoming traffic
ip dscp set 0
}
chain postrouting {
type filter hook postrouting priority filter; policy accept;
# Reset DSCP for outgoing traffic
ip dscp set 0
}
chain forward {
type filter hook forward priority 0; policy accept;
tcp flags syn tcp option maxseg size set rt mtu comment "MSS clamping"
}
}
EOF
tc qdisc replace dev $WAN root handle 1: cake bandwidth $UPLOAD_RATE diffserv4 nat dual-dsthost ingress ack-filter overhead 34 wash
tc qdisc replace dev $LAN root handle 1: cake bandwidth $DOWNLOAD_RATE diffserv4 nat dual-srchost ack-filter overhead 34
Don't do that, either set cake to besteffort (to ignore egress DSCPs) and/or use the wash keyword to reset DSCPs of egress packets in cake, no need to play guessing games with nftables for egress...
This might make sense, or not, but it really depends on where cake is instantiated whether it sees your re-marked DSCPs or what ever original your ISP sends your way. I think tc filters would be the way to wipe ingress DSCPs before cake sees them for that cake on ifb method.
How to set cake to besteffort (to ignore output DSCPs)
Need just delete this rule : # Reset DSCP for outgoing traffic
ip dscp set 0