Stumbled upon this thread while researching the cause for the same exact issues OP is having. I live in Midwest US, and play FIFA and CoD primarily, and some Halo. Since I moved to my address about 5 years ago, I have been having issues in all the games I play. Ping is good, don't have issues with packet loss, and have low jitter. I have used two ISPs in this time - Xfinity/Comcast and a more local ISP called RCN.
FIFA is the most noticeable in terms of the "input lag" because it is a sports title and so is more sensitive to inputs. I have gone thru various gaming monitors, routers, modems, peripherals, etc. Issue still remains. I am a complete noob at networking beyond the basics, so admittedly this thread has gone a bit over my head. I do have an ASUS AX-86U router that I use with Merlin, with Cake QoS turned on. Like op, it hasn't helped.
Like op, I have played these games on different consoles and PC. Has made no difference. I have also played FIFA at several different residences with varying results. I visited a friend in Seattle, and used my Xbox over there. The game was snappy and responsive. I sometimes play at a friend's apartment in my city, about 2-3 miles from me. His experience is also better, though he does experience some of this "input lag". He has the same ISP as me currently - Xfinity. I have also played at another friend's apartment, he lives in a hi-rise, and his gameplay also feels very heavy. Same ISP.
If requested I can give info in this thread but I will need a guiding hand.
Cake/sqm really only can solve issues that are happening directly at your internet access link, if there is a congested route from your network segment to the game servers beyond the first link it really can do only little to help (besides not making things worse by adding even more queueing delay and jitter).
ISPs typically have aggregation structures that put sets of users into the same segment, and both local congestion, RF-ingress noise, and even routing can differ significantly between segments, so seeing issues only in some but not all segments of a given ISP is at least an indication that the ISP might be partially responsible (but no proof, things can go pear shaped later as well with your ISP doing everything above and beyond approach).
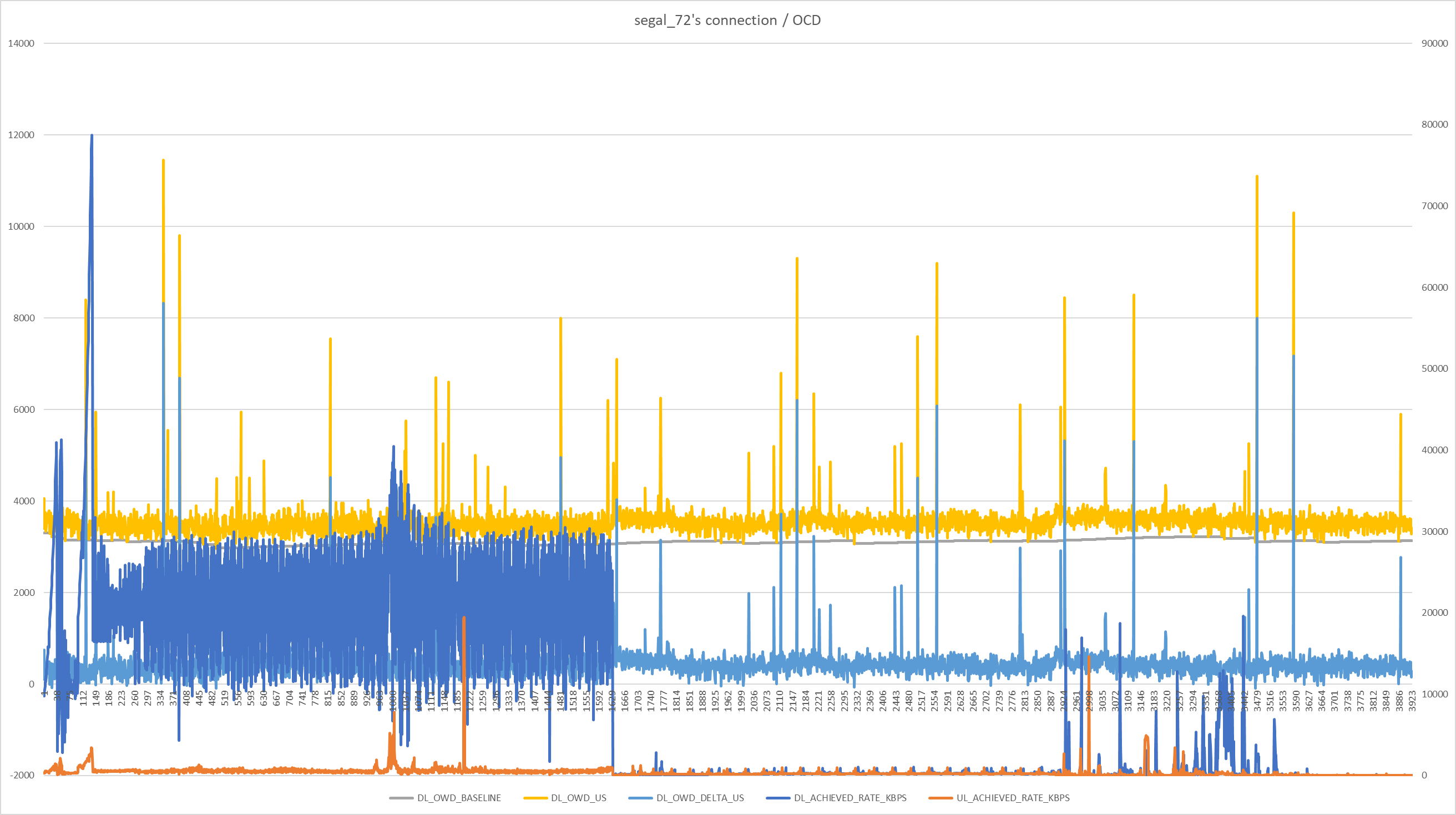
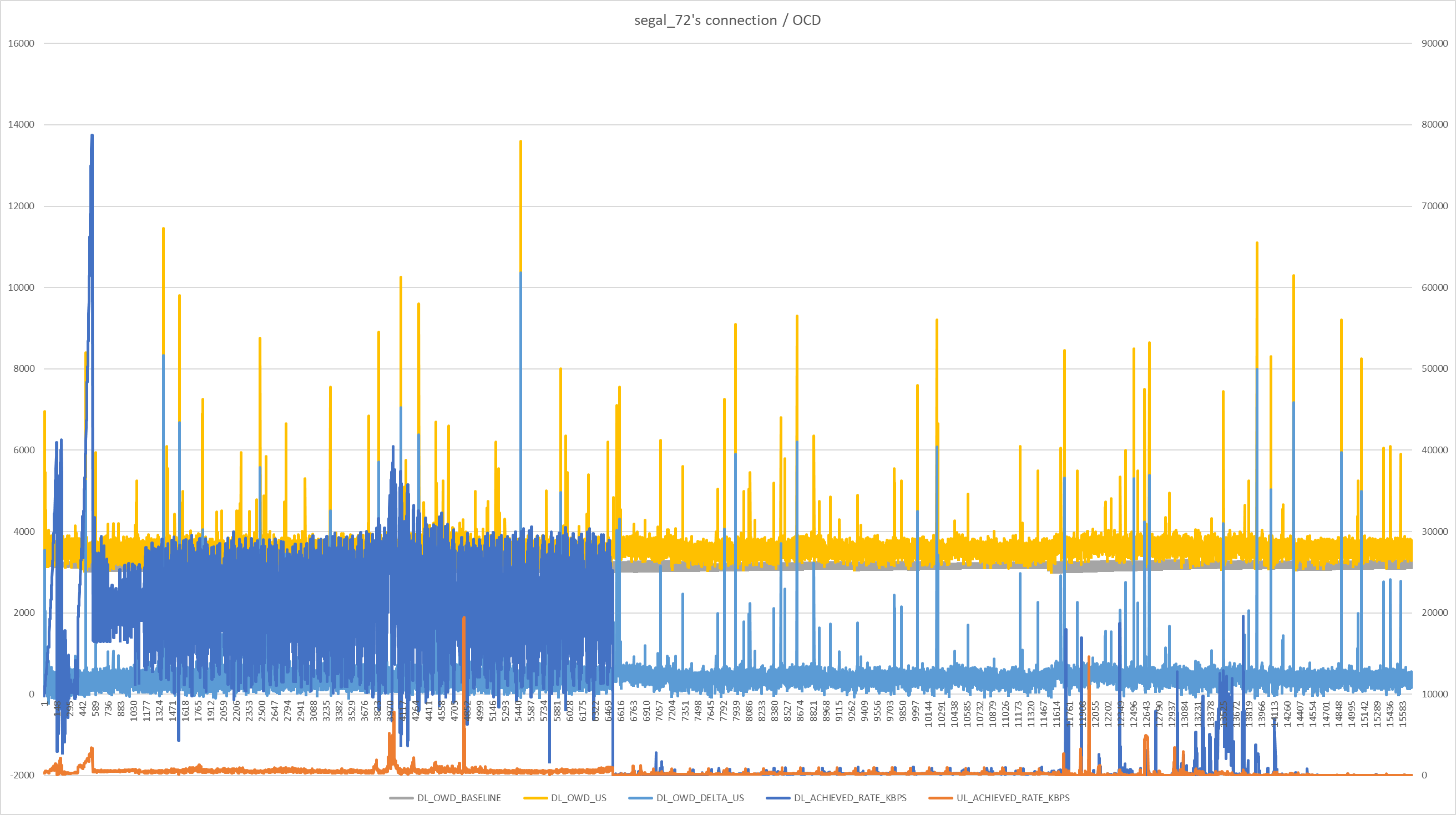
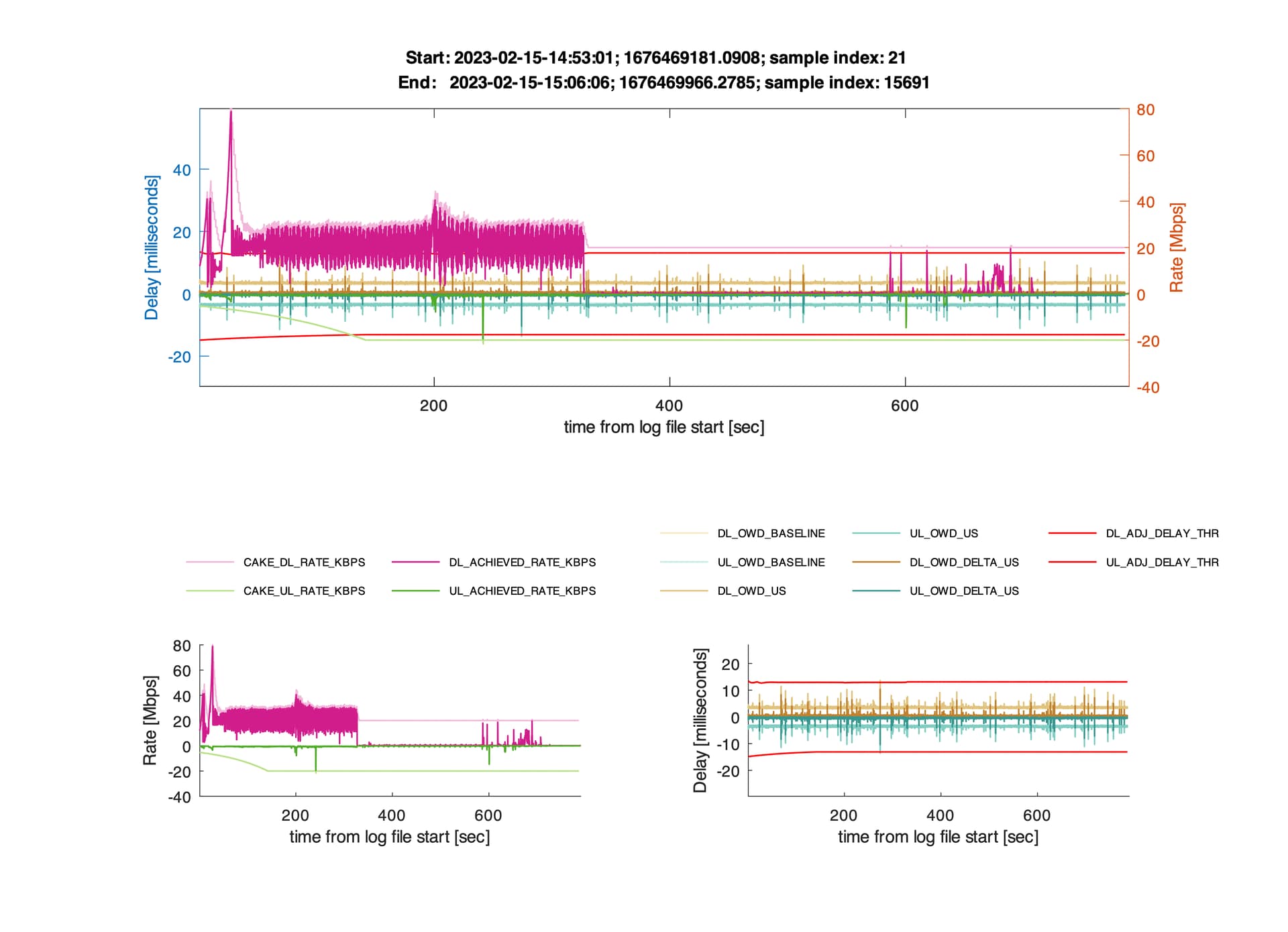
No red flags. OWD latency seems to have a 5ms base with spikes to e.g. 15ms (i.e. RTT 10ms base with spikes to 30ms). Don't know if that's normal or not for your connection type, but I presume not any indication of network related issues that might manifest in your gameplay lag. And I'm not sure how to interpret the initial traffic pattern.
Did you experience lag during this log? And do you know what the initial traffic pattern relates to?
I'm hoping @moeller0 can comment, and especially on the traffic pattern.
Yes this log is a game only, I activated before playing and stopped after finishing the game. The Ping from the game to the live server was 18ms. This game was a punishment in terms of latency, borderline rage, so unplayable. Unimaginable heaviness.
There is no fairness with the opponent. The opponent is very reactive and very fast compared to me.
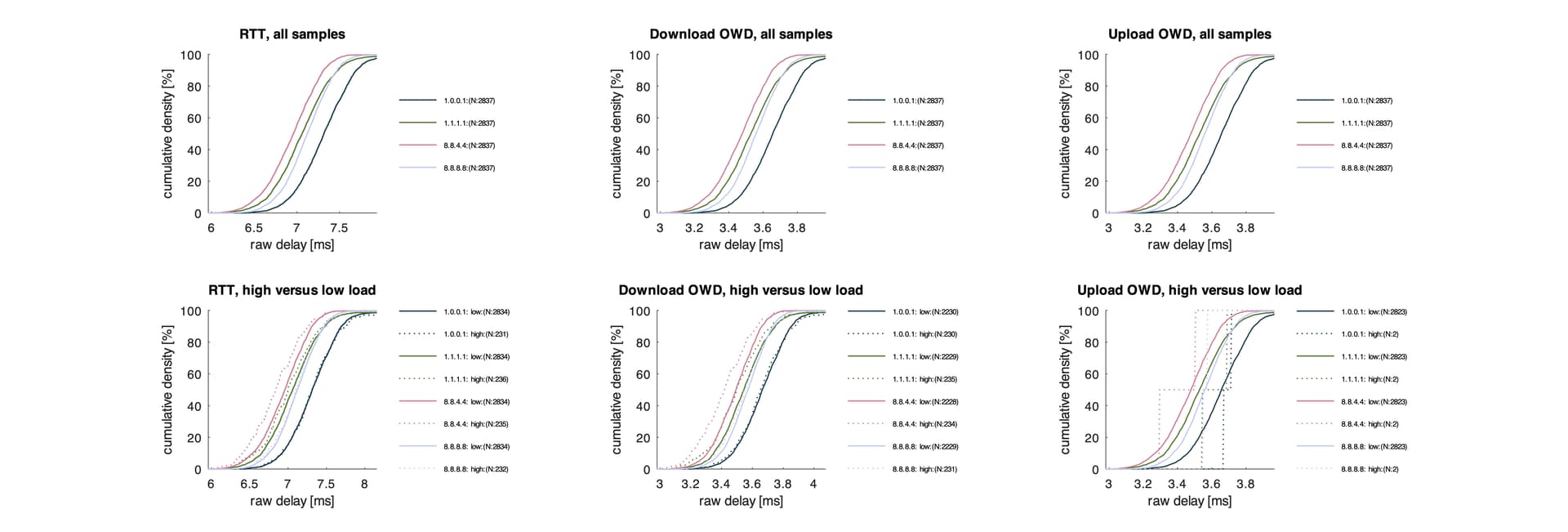
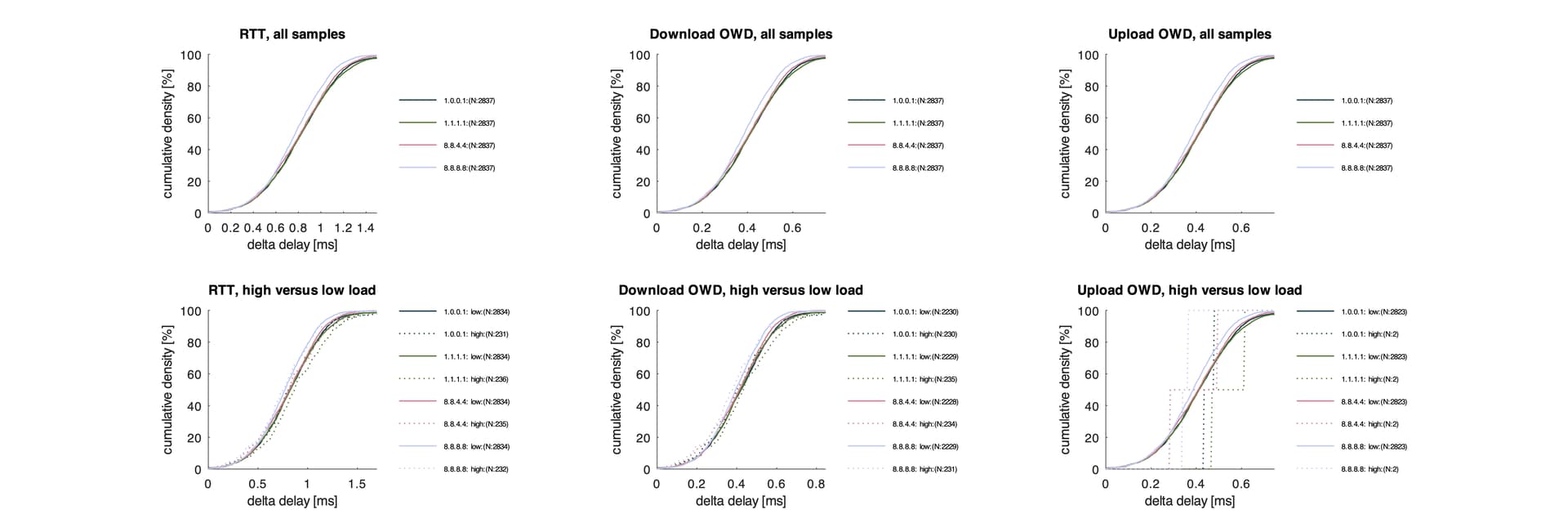
So the cumulative density plots look just excellent, at least cloudflare and google are really reachable during your game play and show no sign of congestion.
This might explain why SQM is not helping, as your access link does not seem to the problem (at least in this sample).
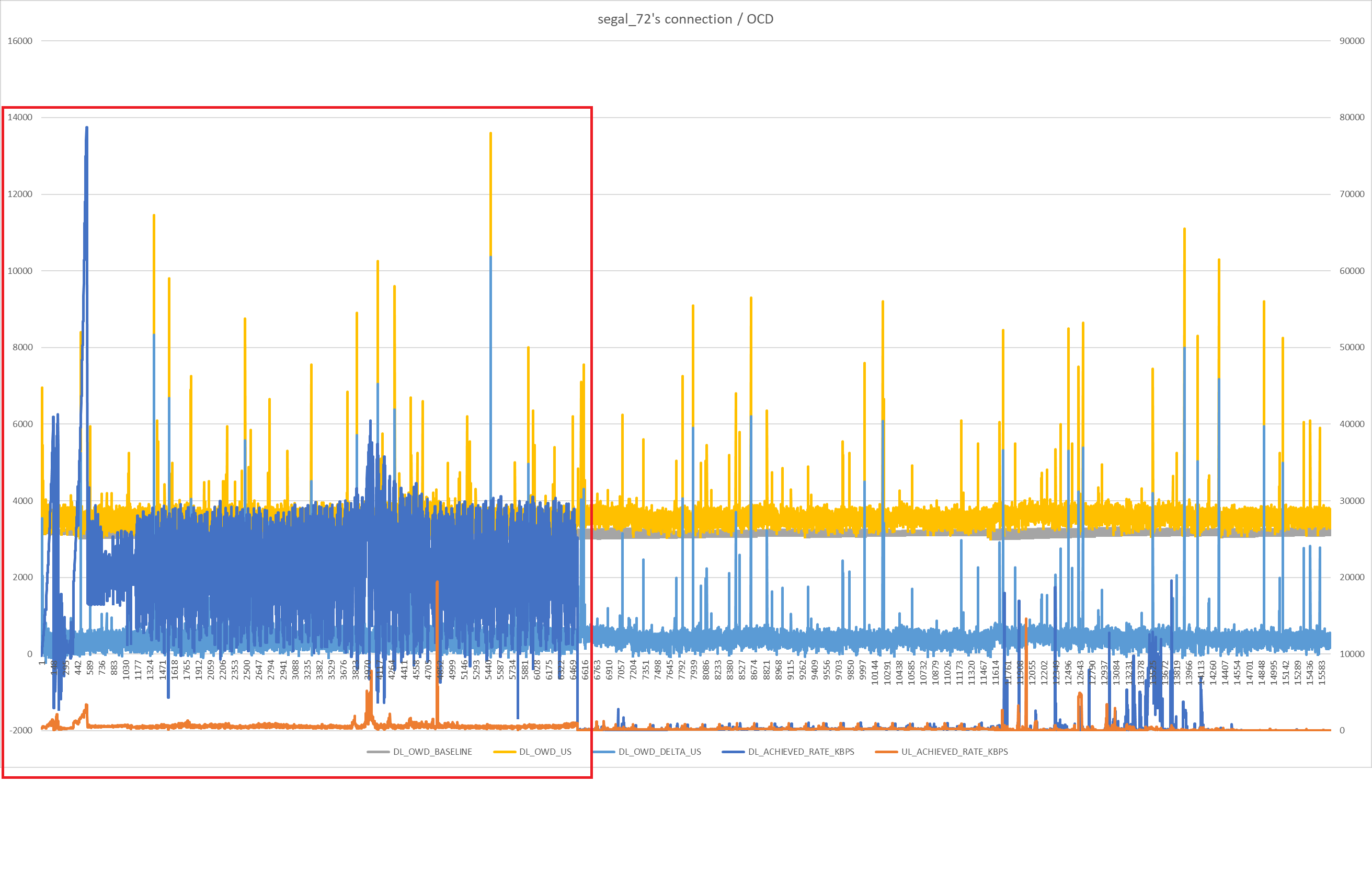
Maybe time to make a packet capture while playbg and go back into trying to dissect that.
And of course trying to find reflectors in the same data center as the game server and add these to the set of reflectors...
@moeller0 is there any sense in which those spikes we see could be smoothed by - yes, call me crazy - actually introducing delay to reduce jitter? Or is this a stupid idea? It's not that the game could be compensating for latency and/or jitter in a broken way that might be fixed by actually introducing delay?
Also do you suppose that burst in the first half is a game update or something? And presumably unrelated to the problems?
And yes, such a connection looks ace compared to my 4G connection, but would have given me significantly less motivation to mess about with cake-autorate!
You are not the first to notice that you can trade-in (some) static delay for less delay variation, this technique is known e.g. as a (de-) jitter buffer. It comes with its own challenges (mainly finding an acceptable balance between jitter removal and static delay increase, given that it rarely is a priori known what amount of jitter one needs to expect) but can hep a lot in some applications, like e.g. VoIP. IIUC at least some on-line games use similar techniques...
Sure, but as most gamers, the OP would immediately switch to LTE if only his preferred game would work better
Good question, maybe some voice or video chat running parallel to the game, @segal_72 anything special going on you know of until ~second 300?
There are 3 steps in this log, first step : matchmaking we are informed the opponent and me that we are going to play on a server at 18 ms, we can refuse this matchmaking and restart a new matchmaking, but it was not my case, I accepted without waiting too much, this phase can last between 2 and 30 seconds according to the acceptance to play this server.
the 2nd step is the half-time, it lasts maximum 30 seconds and the 3rd step is the end of the game and the return to the menu, it's after that that I interrupted the log... this log should last about 18 min maybe 16... or maximum 20 min if each one abuses its 3 breaks of 30 seconds to proceed to the replacement of players.
I have many questions for the future test. Would it be necessary to replace my isp dns with those proposed in the script? 1.1.1.1, 9.9.9.9 etc?
Can I launch a game, find on which server (IP) I play and insert in the autorate config, relaunch auto rate without losing the connection with opponent. If yes, what is the manipulation to carry out?
Well, an ISP will likely point its fingers to both the home network and compter setup as well as the upstream data center, so it might be tricky to get an ISP to change its ways (then again ISPs tend to fix real issues in their networks when they find them, only mostly end users never get into contact with the network wizards that could make that happen*). But if one's gaming sucks what else can one do then trying to find root causes and remedies?
*) And for understandable reasons, end users rarely have enough insight into an ISPs network to come up with hypotheses goid enough to explore yet obscure enough not to be obvious to the wizards already, I would guess.
which is an essential resource when trying to interpret traceroutes. Based on that:
Answer 1: Read page 31 "Prioritization and Rate Limiting" the actual RTT numbers you get from arbitrary network nodes are not really telling you all that much in themselves. You need something like if over a sequence of say 10 hops, there is a big RTT increase starting from hop 5 that is not commensurate with expected RTT* and that lasts all the way to the remote end-point you might have found something real (or not see below).
Answer2: No, that generally is not correct (see page 37 "Asymmetric Paths" and again "Prioritization and Rate Limiting"), however you can expect that on average the RTT should increase along a network path if only as a function of added propagation delay, but that can easily be masked by other delay causes, again read the linked pdf to get an idea.
And for propagation delay, if each segment would be fully serialized, that is packets to hop N+1 will always traverse the path to/from hop N and the the "new" segment between N and N+1, then you expect each hop to add a small increment on top of the previous hop's RTT, so certainly not RTT(4) = RTT(1) + RTT(2) + RTT(3)**
So sorry, you can not really deduce the RTT to totally unresponsive hops like hop 7 in your example.
*) But be careful if you traceroute a host on the east coast of the US from europe you expect that the RTT increases massively for the first hop in the US and for all further US hops as well.
**) for just two hops that might look like that if
RTT(1) is super small
RTT(2) is large
but that is not generally the case.
-c N really is just the number of samples you request... getting higher worst/average RTTs for larger c's could mean:
a) the longer delay samples are occurring rarely and with longer sampling time you are simply more likely to catch it (in that case you would expect that comparing 1 -c 100 run with 10 -c 10 runs taken with say 60 seconds cool-off period between the runs) to show similar worst RTT (in >= 1 of the -c 10 runs)
b) the remote endpoint does rate-limit/de-prioritize and with the longer run you trigger its threshold while the -c 10 run might stay below that.
However as long as the final hop reports 100% loss a one-way mtr/traceroute really is not generally interpretable....
We have tested so many things without any convincing results, which does not reflect the reality of online games. I am forced to believe, without proving it unfortunately, that the way back to the server is subject to latency.