Description:
This post details the results of a series of ROUGH benchmarks conducted on a Raspberry Pi 4B running OpenWrt 23.05.5 to optimize CAKE parameters for low latency and fair traffic distribution among devices.
Test Setup:
Hardware: Raspberry Pi 4B
Firmware: OpenWrt 23.05.5
PPPoE WAN Connection: 20 Mbps download, 20 Mbps upload. Offload: Disabled.
SQM file:
config queue
option enabled '1'
option interface 'pppoe-wan'
option download '19500'
option upload '19500'
option debug_logging '0'
option verbosity '5'
option qdisc 'cake'
option script 'layer_cake.qos'
option qdisc_advanced '1'
option squash_dscp '1'
option squash_ingress '1'
option ingress_ecn 'ECN'
option egress_ecn 'NOECN'
option qdisc_really_really_advanced '1'
option iqdisc_opts 'nat ingress diffserv8 dual-dsthost'
option eqdisc_opts 'nat ack-filter diffserv8 dual-srchost'
option linklayer 'none'
By squashing and ignoring incoming DSCP values, all traffic is treated equally, allowing CAKE to prioritize traffic based on packet size and type, rather than relying on pre-assigned DSCP markings.
Qdisc Options (ingress): nat ingress diffserv8 dual-dsthost
Qdisc Options (egress): nat ack-filter diffserv8 dual-srchost
CAKE leverages the kernel's NAT subsystem to extract the internal host address associated with each packet. This enables accurate traffic classification & prioritization.
Ingress mode improves responsiveness during high download activity, it allows the rate to be set closer to the actual bottleneck bandwidth, thus eliminating waste. It also helps in latency-sensitive traffic like games and VoIP by avoiding back spilling keeping ping stable the whole time without fluctuation.
Testing Methodology:
To assess performance, I simulated heavy network load using Internet Download Manager with 16 maximum connections. Simultaneously, we measured the loading times of various websites on different devices connected to the network, both wired and wireless.
CAKE Parameter Evaluation:
Layer-Cake vs. Piece-of-Cake: Layer-Cake with DiffServ8 consistently outperformed Piece-of-Cake by approximately 40-50%, even without explicit DSCP marking. DiffServ4 provided less significant improvements compared to Piece-of-Cake.
Triple-Isolate vs. Dual Mode: While both modes yielded similar overall performance, Dual mode exhibited slightly better results (~14%) on individual devices.
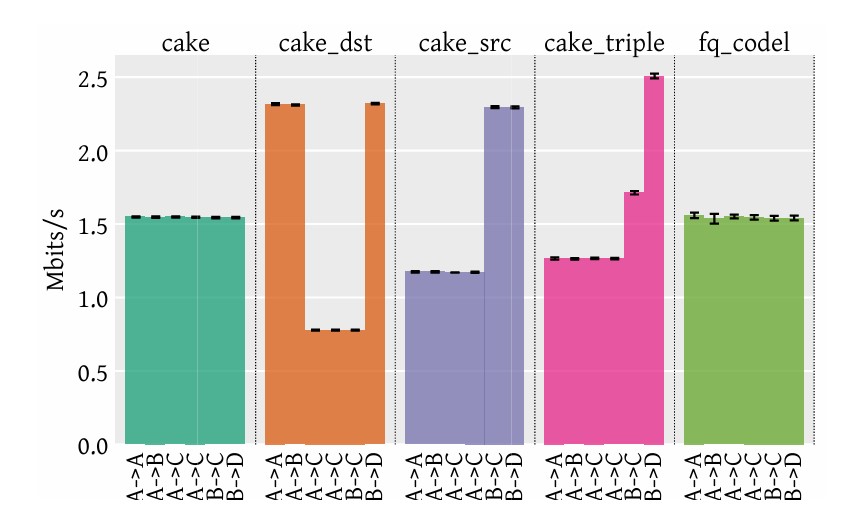
The above graph is derived from the research paper. For a more in-depth analysis, please refer to the Piece of CAKE: A Comprehensive Queue Management Solution for Home Gateways
Ack-Filter vs. Ack-Filter-Aggressive: Minimal differences were observed between the two at upload. Given the potential risks of aggressive packet dropping in future TCP extensions, the standard ack-filter was preferred.
Recommendations:
- Layer-Cake with DiffServ8: This configuration is highly recommended for optimal performance.
- Dual Mode: This mode provides a good balance between isolation and performance.
- Link Layer Adaptation: While the automatic Link Layer Adaptation provided me satisfactory results, it's essential to note that manual configuration may further optimize performance. Additionally, the paper highlights the potential inaccuracy of kernel-reported overhead values. Therefore, it is strongly recommended to conduct thorough benchmarking and manually adjust the overhead parameter for optimal results.
Final thoughts. While these observations offer valuable insights into optimizing CAKE parameters, it's important to note that network conditions can vary widely. To achieve optimal performance, I encourage you to conduct thorough benchmarking tailored to your specific setup. I've also developed a user-friendly tool (Qdisc Benchmarking Tool) to facilitate the benchmarking process that you're welcome to try.

============================================================
For readers seeking a straightforward CAKE configuration, employing a layer-cake diffserv8 could potentially provide half the latency compared to piece-of-pie without the need for more complex configurations
For advanced/gamers stick to QoSmate or qosify
Based on my benchmarks, the QoSmate configuration utilizing CAKE+diffserv4 has yielded the most optimal results without the need for additional rules.