Hi moeller for my part I changed the length of the packets I should use,
I went from my game is simply excellent,
before,

After
Hi moeller for my part I changed the length of the packets I should use,
I went from my game is simply excellent,
before,
After
This is a great illustration how all of the rules we are discussing here mostly are heuristics that occasionally need to be tested on whether they still apply.
Can i see how these rules are setup in the files?
i dont use dscpclassify but script of élan has make for me,
for me is a best script and élan and me has work together élan is a good person is my Learn many things about OpenWrt ![]()
qdisc cake 8006: dev wan root refcnt 2 bandwidth 16Mbit diffserv4 dual-srchost nat wash no-ack-filter split-gso rtt 100ms noatm overhead 44
Sent 165169545 bytes 727905 pkt (dropped 3, overlimits 116531 requeues 0)
backlog 0b 0p requeues 0
memory used: 91501b of 4Mb
capacity estimate: 16Mbit
min/max network layer size: 28 / 1500
min/max overhead-adjusted size: 72 / 1544
average network hdr offset: 14
Bulk Best Effort Video Voice
thresh 1Mbit 16Mbit 8Mbit 4Mbit
target 18.2ms 5ms 5ms 5ms
interval 113ms 100ms 100ms 100ms
pk_delay 2.07ms 1.86ms 3.41ms 183us
av_delay 399us 149us 393us 9us
sp_delay 20us 8us 85us 3us
backlog 0b 0b 0b 0b
pkts 424 430053 169803 127628
bytes 492282 119383401 21707916 23590005
way_inds 0 1952 1 0
way_miss 3 1781 1261 60
way_cols 0 0 0 0
drops 0 1 2 0
marks 0 0 0 0
ack_drop 0 0 0 0
sp_flows 0 1 6 0
bk_flows 0 0 0 0
un_flows 0 0 0 0
max_len 6056 27252 1341 1344
quantum 300 488 300 300
qdisc noqueue 0: dev br-lan root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc cake 8005: dev veth0 root refcnt 2 bandwidth 32Mbit diffserv4 dual-dsthost nonat nowash ingress no-ack-filter split-gso rtt 100ms noatm overhead 44
Sent 1340724137 bytes 1206200 pkt (dropped 44, overlimits 1370875 requeues 0)
backlog 0b 0p requeues 0
memory used: 476649b of 4Mb
capacity estimate: 32Mbit
min/max network layer size: 28 / 1500
min/max overhead-adjusted size: 72 / 1544
average network hdr offset: 14
Bulk Best Effort Video Voice
thresh 2Mbit 32Mbit 16Mbit 8Mbit
target 9.08ms 5ms 5ms 5ms
interval 104ms 100ms 100ms 100ms
pk_delay 3.22ms 11.5ms 217us 938us
av_delay 479us 7.04ms 9us 90us
sp_delay 6us 13us 2us 2us
backlog 0b 0b 0b 0b
pkts 1120758 3542 66 81878
bytes 1265869517 3718738 4588 71192883
way_inds 2407 0 0 0
way_miss 1804 172 25 66
way_cols 0 0 0 0
drops 41 3 0 0
marks 0 0 0 0
ack_drop 0 0 0 0
sp_flows 1 6 11 0
bk_flows 1 0 0 0
un_flows 0 0 0 0
max_len 18168 18168 71 1344
quantum 300 976 488 300
qdisc noqueue 0: dev veth1 root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
root@OpenWrt:~#
dscpclassify is a good script also for having tested it but less efficient in sum
here is my tc -s qdisc if moeller0 wants to add a detail about the graphics ![]()
hi dopam-it_1987
can you plz share how you changed the packet lenght?
I wonder if we could adopt most of these rules to the base install rules file? Seems to cover alot of use cases..
Some one should first test each proposed rue individually to figure out whether they actually still apply (all heuristics need to be re-confirmed every now and then), and then test whether these rules interfere with each other.
Respectfully, the "trick" behind prioritization is to prioritize as little as possible, so having too many ready-made rules can tempt users to activate all/too many resulting in "a mess"...
It does its job perfectly on Torrents. But is not working on Battle.net (by default?). Downloading a game eats the whole bandwidth and uses Best Effort instead of Bulk.
That is how prioritization works in cake, no left-over capacity if there is still demand, the test really is how responsive is your link for other uses during a battle.net download for other use cases.
For example it's impossible for me to watch 480p+ Twitch stream/YouTube video during Battle.net P2P(?) downloads. The download slows down from 2.0MB/s to around 1.7-1.8MB/s when I attempt to watch something higher quality but obviously it's not enough.
I take it you do battle.net downloads and youtube watching on the same computer?
When you say twitch stream, do you mean watching other player's twitch streams or do you mean streaming your own into the internet (assume the former).
IIRC your download sync is ~20Mbps resulting in a theoretical maximal goodput of around:
20000 * (64/65) * ((1500-20-20)/(1500+34)) = 18742.35 Kbps or
20000 * 1000 * (64/65) * ((1500-20-20)/(1500+34)) / (8 * 1024^2) = 2.23 MBps
So battle.net downloads seem to already be close to your link's maximum (which is fine as long as not other traffic is active), but 480p youtube only needs 1.1 Mbps, so hard to see how there is not enough room for that after battle.net freed up 0.2-0.3 MBps or (0.2 * 1024^2 * 8)/1000^2 = 1.7 to (0.3 * 1024^2 * 8)/1000^2 = 2.51 Mbps... 720p Youtube already needs 2.5 Mbps leaving no slack, but 480 should work. However youtube video delivery is bursty and not smooth, and youtube becomes unhappy if the bursts take too long for its taste, so youtube might self-throttle here before battle.net gives way...
I guess it is time to make a packet capture and see how battle.net and youtube traffic is marked respectively and which priority tin in cake it uses.
To test the second question please do and post the output of:
tc -s qdisctc -s qdisctc -s qdisctc -s qdiscThe goal is to see in which of cake's priority tins do the counters actually go up for the different traffic types... You either need to move battle.net below the video streams (so either to bulk) or move the video streams above battle.net traffic.
I have done that. I'm using default DSCP Classify config, and both YouTube and Twitch packets go into Best Effort. So there is nothing done intelligently like it does on Torrents and other stuff. I'm able to watch both up to 480p, nothing more than that.
Fresh:
qdisc cake 802e: dev ifb4pppoe-wan root refcnt 2 bandwidth 18Mbit diffserv4 dual-dsthost nat nowash ingress no-ack-filter split-gso rtt 100ms noatm overhead 34 mpu 68
Sent 1963 bytes 19 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
memory used: 2176b of 4Mb
capacity estimate: 18Mbit
min/max network layer size: 40 / 382
min/max overhead-adjusted size: 74 / 416
average network hdr offset: 0
Bulk Best Effort Video Voice
thresh 1125Kbit 18Mbit 9Mbit 4500Kbit
target 16.1ms 5ms 5ms 5ms
interval 111ms 100ms 100ms 100ms
pk_delay 0us 39us 0us 32us
av_delay 0us 2us 0us 0us
sp_delay 0us 2us 0us 0us
backlog 0b 0b 0b 0b
pkts 0 16 0 3
bytes 0 1749 0 214
way_inds 0 0 0 0
way_miss 0 13 0 1
way_cols 0 0 0 0
drops 0 0 0 0
marks 0 0 0 0
ack_drop 0 0 0 0
sp_flows 0 3 0 0
bk_flows 0 0 0 0
un_flows 0 0 0 0
max_len 0 382 0 72
quantum 300 549 300 300
After Battle.net download:
qdisc cake 802e: dev ifb4pppoe-wan root refcnt 2 bandwidth 18Mbit diffserv4 dual-dsthost nat nowash ingress no-ack-filter split-gso rtt 100ms noatm overhead 34 mpu 68
Sent 83656871 bytes 61475 pkt (dropped 14864, overlimits 136747 requeues 0)
backlog 0b 0p requeues 0
memory used: 563584b of 4Mb
capacity estimate: 18Mbit
min/max network layer size: 36 / 1440
min/max overhead-adjusted size: 70 / 1474
average network hdr offset: 0
Bulk Best Effort Video Voice
thresh 1125Kbit 18Mbit 9Mbit 4500Kbit
target 16.1ms 5ms 5ms 5ms
interval 111ms 100ms 100ms 100ms
pk_delay 0us 48ms 281us 32us
av_delay 0us 15.6ms 8us 0us
sp_delay 0us 36us 8us 0us
backlog 0b 0b 0b 0b
pkts 0 76329 7 3
bytes 0 105000990 260 214
way_inds 0 12 0 0
way_miss 0 119 7 1
way_cols 0 0 0 0
drops 0 14864 0 0
marks 0 0 0 0
ack_drop 0 0 0 0
sp_flows 0 9 2 0
bk_flows 0 3 0 0
un_flows 0 0 0 0
max_len 0 1440 44 72
quantum 300 549 300 300
After YouTube:
qdisc cake 802e: dev ifb4pppoe-wan root refcnt 2 bandwidth 18Mbit diffserv4 dual-dsthost nat nowash ingress no-ack-filter split-gso rtt 100ms noatm overhead 34 mpu 68
Sent 209638830 bytes 161128 pkt (dropped 14951, overlimits 333588 requeues 0)
backlog 0b 0p requeues 0
memory used: 563584b of 4Mb
capacity estimate: 18Mbit
min/max network layer size: 36 / 1440
min/max overhead-adjusted size: 70 / 1474
average network hdr offset: 0
Bulk Best Effort Video Voice
thresh 1125Kbit 18Mbit 9Mbit 4500Kbit
target 16.1ms 5ms 5ms 5ms
interval 111ms 100ms 100ms 100ms
pk_delay 0us 4.86ms 494us 229us
av_delay 0us 4.05ms 22us 4us
sp_delay 0us 50us 22us 4us
backlog 0b 0b 0b 0b
pkts 0 176052 21 6
bytes 0 231093525 784 462
way_inds 0 24 0 0
way_miss 0 194 19 4
way_cols 0 0 0 0
drops 0 14951 0 0
marks 0 0 0 0
ack_drop 0 0 0 0
sp_flows 0 1 1 1
bk_flows 0 1 0 0
un_flows 0 0 0 0
max_len 0 1440 52 96
quantum 300 549 300 300
After Twitch:
qdisc cake 802e: dev ifb4pppoe-wan root refcnt 2 bandwidth 18Mbit diffserv4 dual-dsthost nat nowash ingress no-ack-filter split-gso rtt 100ms noatm overhead 34 mpu 68
Sent 269310691 bytes 205614 pkt (dropped 14963, overlimits 410512 requeues 0)
backlog 0b 0p requeues 0
memory used: 563584b of 4Mb
capacity estimate: 18Mbit
min/max network layer size: 36 / 1440
min/max overhead-adjusted size: 70 / 1474
average network hdr offset: 0
Bulk Best Effort Video Voice
thresh 1125Kbit 18Mbit 9Mbit 4500Kbit
target 16.1ms 5ms 5ms 5ms
interval 111ms 100ms 100ms 100ms
pk_delay 0us 4.09ms 507us 232us
av_delay 0us 1.73ms 25us 5us
sp_delay 0us 27us 25us 5us
backlog 0b 0b 0b 0b
pkts 0 220537 32 8
bytes 0 290782090 1188 634
way_inds 0 43 0 0
way_miss 0 271 25 6
way_cols 0 0 0 0
drops 0 14963 0 0
marks 0 0 0 0
ack_drop 0 0 0 0
sp_flows 0 5 2 1
bk_flows 0 1 0 0
un_flows 0 0 0 0
max_len 0 1440 52 96
quantum 300 549 300 300
Thanks so yes, these all seem to duke it out inside the BestEffort tin, and then applications on the same computer will see per-flow-fairness. My guess is that the streaming applications use likely just a single flow while battle.net uses multiple flows and hence gets a larger share of the bandwidth.
Possible work-arounds are:
a) configure cake for per-internal-P fairness and use a different device for video streaming than for battle.net
b) change the classify rules to have youtube/twitch be put into the Video priority tin
c) change the classify rules to have battle.net downloads be put into the Bulk priority tin.
Since I have never used DSCP classify myself (still on OpenWrt21 based turrisOS 6) I can not really help/assists with b) or c).
The question is: howto down priorize battle.net downloads the correct way?
You need to find out a unique unambiguous identifier either specific remote IP addresses+port combinations. And then create a matching rule. I am in no position to help as I neither use DSCP classify nor battle.net.
Personally I likely would resort to using a different machine for interactive usage during bulk downloads and use that in combination with the per-internal-IP fairness configuration for cake, but that is because I am:
a) lazy
b) would expect ip-addresses and ports requiring regular confirmation, but see a)
![]()
Well, i know. ![]() It was more about the set of domains/ips
It was more about the set of domains/ips ![]() (or other ways, like package size etc)
(or other ways, like package size etc)
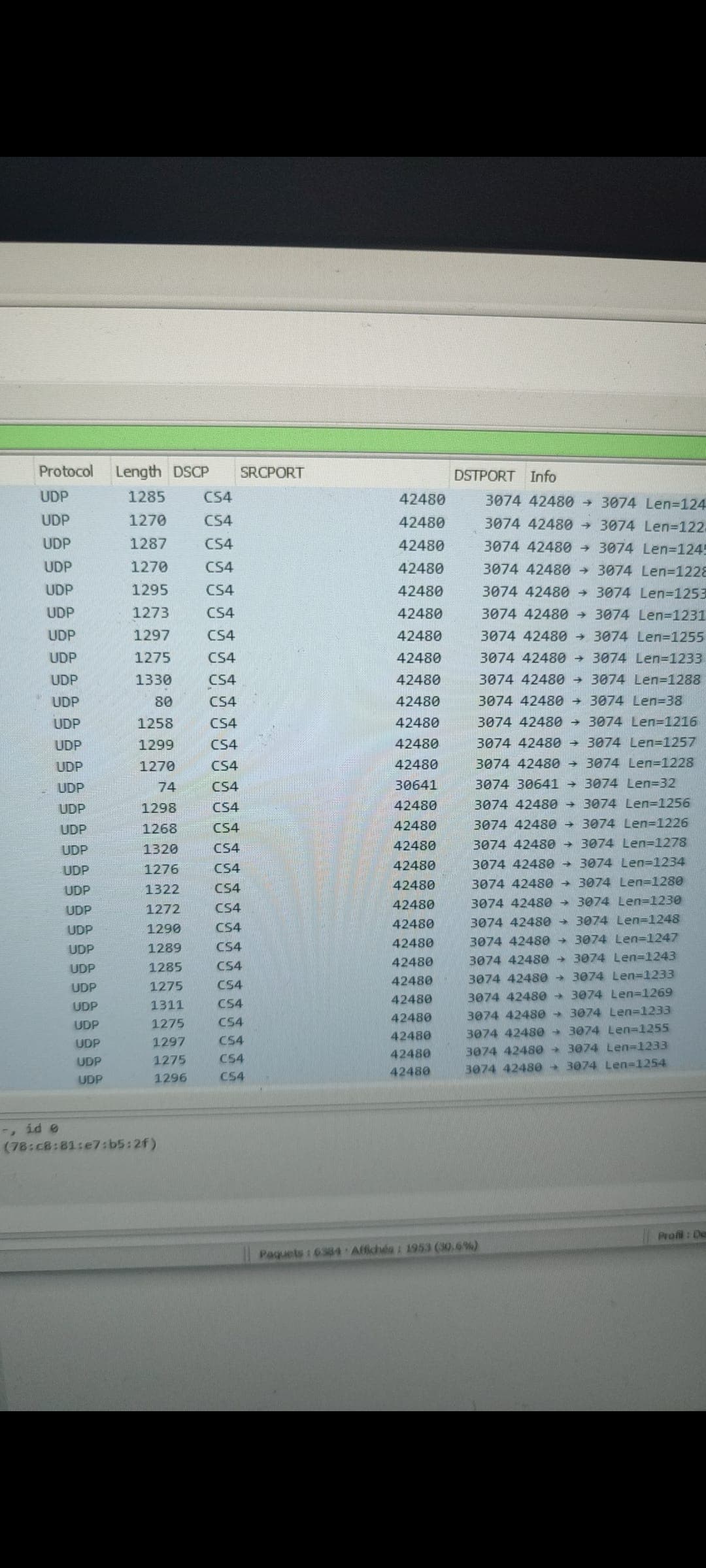
Hi @Luka , in theory the service should be able to help you here, since the pattern you've shown in that screenshot should trigger its threaded service detection.
By default it would classify these as AF13 (which in diffserv3/4 falls into Best Effort tin), you could try moving them into the bulk tin by setting the global config option 'class_high_throughput' to 'le' rather than the default 'af13'.
Note that this would also likely have the consequence of putting things like speed tests into the bulk tin, but for day to day usage that may not bother you.
Edit:
I'll look to rename the class_bulk and class_high_throughput config options to better show their relation to the threaded client/service classification logic.
A heads all, I've pushed a new commit to the main branch which fixes an issue with network devices with non-alphanumeric characters in their name (the service failed to start when encountering these previously).
Wouldn't it be better to make a generic config for usual home users which includes most of the popular services? I know there are few people doing that like this one: CAKE QoS Script (OpenWrt)
That will be impossible... some will prefer threaded services above best effort and some the other way around. The thing is for every packet treated to better/faster service other packet(s) will need to be treated to worse/slower service, if under congestion there are not enough packets to treat worse yiou will not be able to meaningfully treat others better.
The upshot is that prioritization (especially up-prioritization) should be used only sparingly and only if it results in noticeable improvements... Creating a hierarchy of rules to steer a lot of different traffic in different priority tiers is counter to that idea... especially if you keep in mind that a lot of such rules by necessity will be based on heuristics. Heuristics are fine but need to be re-confirmed every now and then to make sure they still "select" the intended traffic. If you do not do that you might end up with rules that do other things than you expect.
Personally I am lazy and will only use the absolute minimum on rules (currently exactly zero) and only if I can convince myself that such a rule results in better "service" across my network.