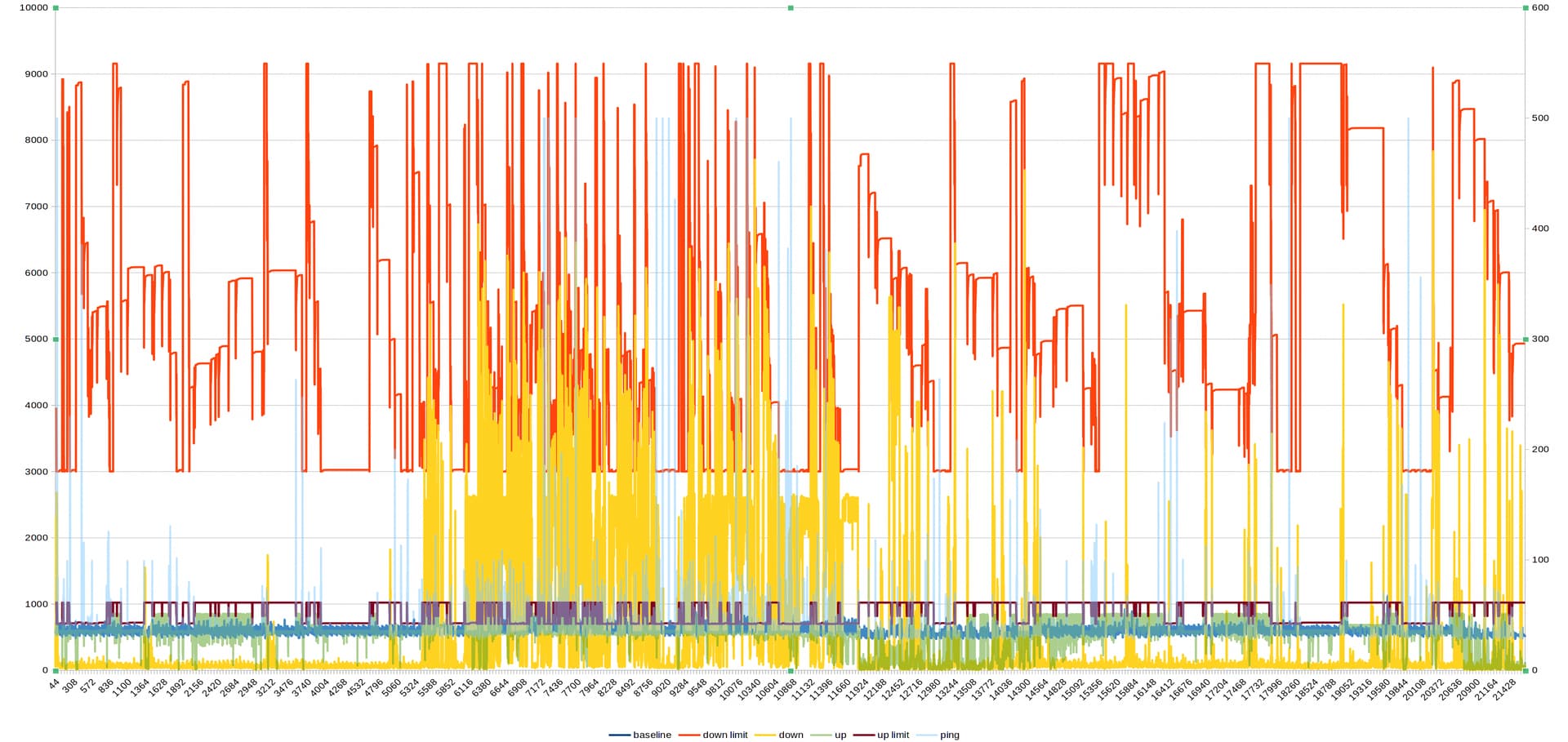
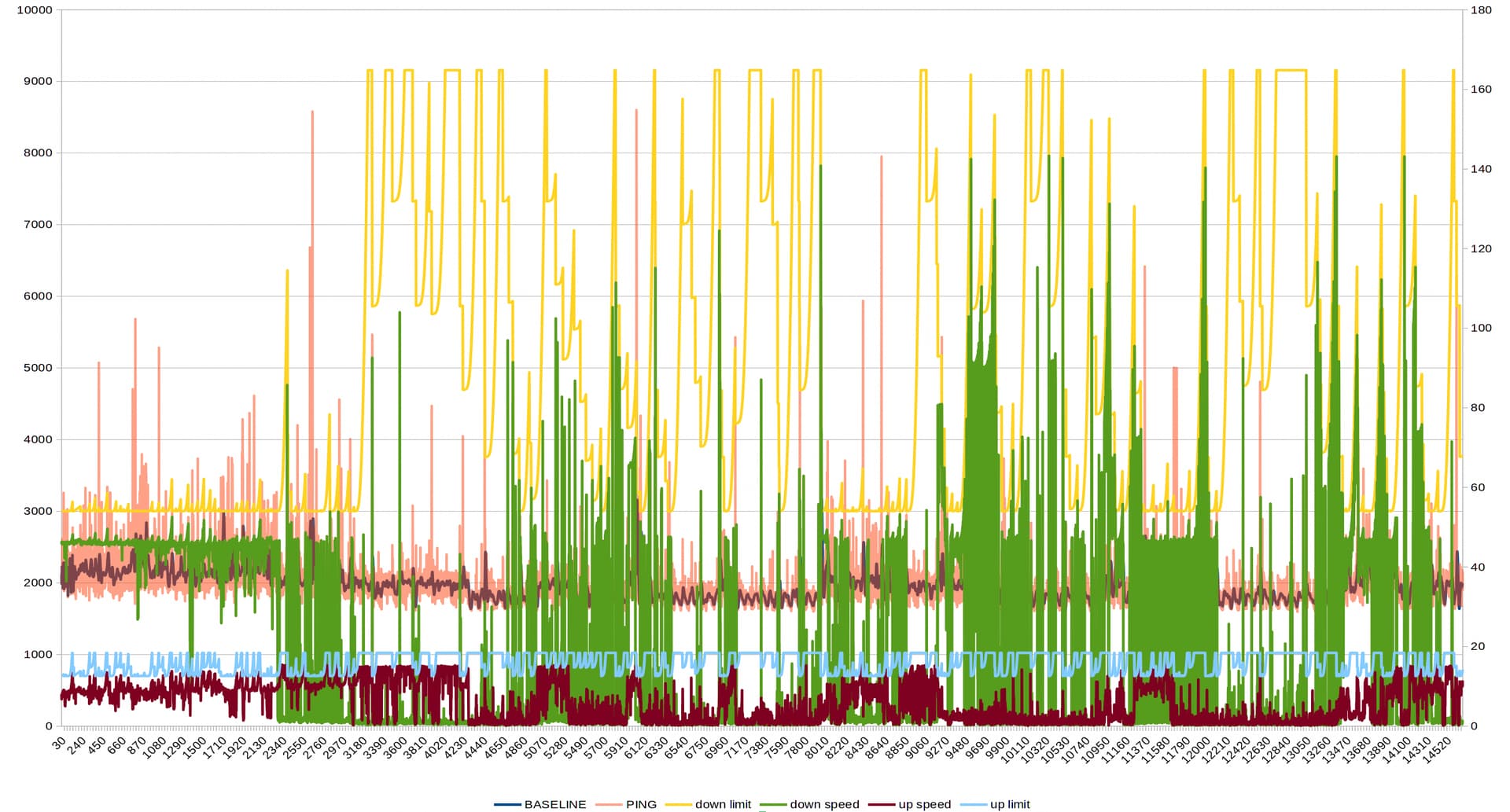
That is very valuable thank you. It is great to see the first graph of a really long time duration on this thread! How do you feel your implementation is working?
Any chance that you could provide a link to raw data?
An approach that is more predictive and less reactive seems highly desirable. Would be nice to ascertain theory for the latter that lends itself to a straightforward receiver-side implementation.
I think we will always have the problem that we don't know the possible bandwidth ceiling until we go over it. They key for a less reactive system is to actively probe above the current level temporarily and see if it results in delay. The key being that the probe itself is an active part of the feedback loop. it would be good to have a UDP reflector that you could spit a block of UDP at with time it was sent, and receive a packet back that replies to that packet with the time it was reflected. Do this in little chunks and then when the probe indicates safety, increase the bandwidth.
How about using what is described in sections 3.1 to 3.3 of:
So you have extremely small tick duration (20ms) and update background model based on observed number of bytes within that tick duration. And use that to predict future bytes.
Then instead of sending prediction to sender, we use the prediction to update CAKE bandwidth?
Worst case retire a log file after X minutes and compress it on disk... and continue logging to a new file. That is still going to produce a lot of log data 3600 rows per hours at 1second ticks....
Well, as competent WiFi buffer management in OpenWrt demonstrates the best place to solve this is in the end points of the variable rate link not the endpoints of a connection. I am not sure we can do considerably better than we do right now, unless we get a better model about the variable link rate transitions. Because to predict something one needs to have a decent model of that thing. IMHO probably the easiest approach is to try to come up with a heuristic when to "stay the course" instead of ramping up/down.
I think we should look at what your script already achieves versus either statically sticking to either the maximum or the minimum, and then try to imagine what a perfect solution would give, and then always weigh any additional complexity in the control loop against the improvement (in absolute terms) it brings/might bring. My hunch is that according to the 80/20 rule we are already in the 80+ range.
Maybe, or maybe that we need an additional information path in which such links can convey information about the expected throughput in the immediate future...
+1; in addition we do not have a robust model how the available rate is going to change.
That is for example what BBR does, but this requires that we can actually generate a saturating load (basically do a speedtest with concurrent latency testing). Personally I love how @Lynx's approach does away with that taking the "organic" load of the link as yardstick. Getting reliable latency reflectors is already a challenge, doing the same for rate measurements seems even harder.
We can stop right there, that is pretty much made of unobtainium from our vintage point... I think it interesting that their "prediction" only last 160ms, which is also on the impossible side for a shell script.
As said above, my question is how much improvement will such considerable increase in complexity buy us?
Mmmh, from that paper:
"Sprout uses the receiver’s observed packet arrival times as the primary signal to determine how the network path is doing, rather than the packet loss, round- trip time, or one-way delay."
I am quite sure that that is problematic in itself, as e.g. WiFi/DSL/DOCSIS links will additionally change the inter-packet spacing, plus sprout requires the receiver to return information about the received packet spacing back to the sender, not sure we could "model" that for our purposes (that said, just because I do not see a how, does clearly not indicate that this is impossible, but really just that my imagination is rather limited).
Side note, I like section 5.4 in that paper a lot:
" 5.4 Comparison with in-network changes
We compared Sprout’s end-to-end inference approach against an in-network deployment of active queue man- agement. We added the CoDel AQM algorithm [17] to Cellsim’s uplink and downlink queue, to simulate what would happen if a cellular carrier installed this algorithm inside its base stations and in the baseband modems or radio-interface drivers on a cellular phone.
The average results are shown in Figure 8. Aver- aged across the eight cellular links, CoDel dramatically reduces the delay incurred by Cubic, at little cost to throughput.
Although it is purely end-to-end, Sprout’s delays are even lower than Cubic-over-CoDel. However, this comes at a cost to throughput. (Figures are given in the table in the introduction.) Sprout-EWMA achieves within 6% of the same delay as Cubic-over-CoDel, with 30% more throughput.
Rather than embed a single throughput-delay trade- off into the network (e.g. by installing CoDel on carrier infrastructure), we believe it makes architectural sense to provide endpoints and applications with such control when possible. Users should be able to decide which throughput-delay compromise they prefer. In this setting, it appears achievable to match or even exceed CoDel’s performance without modifying gateways."
Especially considering that they appaently only used a single queue CoDel instance and not fq_codel... IMHO that is the way to solve such issues, maybe combined with high-frequency congestion signaling (which can help IFF the link's rate fluctuations are somewhat slower than the RTT so that flows can adapt their rates accordingly, once fluctuation rate gets >> that possible adaptation rate, the problem might flare up again).
I don't think so. We just need to be able to probe above the ambient usage. So suppose we have a flow doing 10Mbps and this is currently the shaper rate. If we have a side channel where we can send an additional 500kbps and we do that then we can bump the shaper rate up if we don't get delays. Lather rinse repeat. We only need to generate and reflect relatively small quantities.
The sprout paper talks about keeping a heartbeat signal in the background to deal with no load condition.
@moeller0 I know that sprout is supposed to be implemented on both sides but the portions mentioned (3.1 to 3.3) are provided at receiver side and used to estimate the link rate. Why wouldn't that work for us?
Can a C implementation not then work with the 20ms tick duration and use its approach to predict the future bandwidth. Whereas sprout sends that to the sender, instead we set CAKE bandwidth based on the prediction. All at the receiver.
Which is a saturation load.... really if our shaper sits at X Mbps, but the true link can only sustain Y (with Y < X) you need a load > Y to see an significant increase in latency... so IMHO not just "above the ambient usage" but above the true bottleneck rate. OK, technically that is not a saturating load for our shaper but I fail to see (especially for a bursty MAC) how we can make any robust estimate without a noticeable load.
The "we have a flow doing 10Mbps and this is currently the shaper rate" part is what I would call a saturating load, the side channel is not really that much different from opening the shaper a bit, no?
That is the rationale for having small rate increase steps
Yes, but they put stock in the interpacket intervals, which are not terribly robust or reliable (then again, they report data from real links IIUC, so it seems to work reasonably well). But sprout is a full end 2 end protocol and I do not see how we can emulate that with essentially a single intermediate node.
I would start with, data transfer is not a poisson process (it is often modeled as poisson, because that allows for some closed-form solutions, but that does not change the fact that poisson is not a perfect description of the actual data patterns). But mostly I do not think that the added complexity will buy us much (and I severely doubt that we can make robut predictions of the available rate in 1 second intervals (I see no chance of reducing the tick rate much below 1Hz, let alone reaching their 50Hz rate))
It might, but we still have the problem, that when ever we change the shaper rate this will lead to a lagging signaling to the flows that actually constitute our load, unlike in sprout where the actual data transferring flows get a better rate estimate, we still have the added indirection, that we only adjust a shaper rate, which only indirectly affect the individual flows.
I am not saying that a "sprout" approach might not be made to work, but I really not seeing this gaining much over your existing, considerably simpler approach ("When you are a Bear of Very Little Brain" it really helps to keep things simple, and I am such a bear).
Again, it would at best allow us to change the shaper rate every 20ms, but I am pretty sure our flows will need a bit longer to actually react to the changed shaper setting (think an 100ms RTT flow, which will take at least 100ms to react). Also I note, that sprout is almost a decade old but I have not actually seen it in use, which might indicate that either deployment of new protocols is simply hard, or that there are some downsides to that approach that showed up in later tests.
The problem with opening the shaper a bit is that the time to react would be longer, as you now need to interact with TCP or QUIC bandwidth seeking algorithms. With a side channel you could slam UDP down the channel at say 500kbps for say 50ms (say 10 packets at 350 bytes) and see if you get a reflection in the same time as your baseline. Only if you do, open the channel. These kinds of probes might lead to 50ms of delay but not more substantial spikes. Controlled probes seem better than just letting the ambient traffic do whatever and try to react in a timely manner (particularly of RTT is 100-200ms for a big download for example.
Also, I guess the other important point is that with just this marginal traffic being generated, a relatively small fraction of the bandwidth is "wasted" with useless data. If you run a bandwidth seeking speed-test you fill up the pipe with worthless data, whereas if you just do a small side-probe and then open the pipe, you fill the pipe with useful data.
Same as with your approach, as you assume already a shaper saturating load, at which point alls flow will constantly be probing the upper limit and increasing that will see flows using that additional bandwidth rather soon...
Ah, I see our disconnect, you are are arguing from principle (and from that perspective I agree with your analysis) while I argue from feasibility (and seeing no reliable high-speed ow latency UDP reflectors available, I consider the UDP rate & latency probe approach as improbable to be implementable any time soon).
Yes, but the elegance of using the organic load is that this requires no additional external cooperation beyond normal internet services.
Plus currently, we pro-actively open up the shaper even if the load has not reached 100% to make room for increasing rate demands (one could look at the rate of growth of the load and make this shaper rate increase dependent on an increasing load, but that seems secondary optimizations and potentially pre-mature*.)
I still think @Lynx 's approach with using the organic load here makes most sense....
*) Mind you, this is not my project and @Lynx might have different goals, but I am fully in the "fine with good enough" camp here and do not expect perfection.
Yes, I'm just considering what's feasible algorithmically, I'm not yet considering whether such a thing is feasible in the larger sense.
I'd be willing to try to write a UDP reflector program (in Julia, so compiled and fast, but would require a VPS to run it). Perhaps we could add some UDP sending/probing to the Lua script... as a proof of concept. The bandwidth requirements shouldn't be crazy high here as we only need to probe if we're near the peak of our shaper, and only a few thousand bytes every say 1 second. It could be just as feasible to do this as it is to set up your own VPN with a VPS.
Yes that's not been addressed yet in the shell script either (properly handling flow direction). So whilst download and upload separately increases on load, upon detection of an RTT spike both are decreased. Which is suboptimal.
@openwrticon is your code on GitHub? The RTT seems to spike quite a lot. Too much would you say? What do you think of the sprout algorithm discussed above for bandwidth estimation? Doesn't look so insane to code, no? They report great results on variable rate connection and although end to end I wonder if the receiver side could be leveraged. Tempted to try it? Sections 3.1 to 3.3 of paper and instead of reporting bandwidth to sender it is just used to set CAKE bandwidth. But as @moeller0 has explained above this may not improve things dramatically. In any case I'd be interested in your thoughts.
@moeller0 I just had a thought when reading up about the preserving of skb->hash to allow CAKE to work on upload in the context of WireGuard tunnel.
Wouldn't it be possible to have the WireGuard protocol itself offer end to end bufferbloat management such as is employed in sprout in which receiver feeds back to sender to give super low latency for high bandwidth?
Its just I imagine VPN tunnels often overlap with last mile links so wonder if that could be exploited to help facilitate feedback from receiver to other end of link close to sender.
Would it matter in that case that sender (e.g. a fast NordVPN server) is not quite at the sending end of the last mile link? I'm imagening the latency increase from NordVPN to ISP is small compared to last mile link increase.
If this is a crazy idea, which it might well be, would it still work to provide end to end congestion control by purchasing server and having traffic routed through that?
Or is that also doomed to fail?
How much does end to end help vs just received end?
Just seems such a shame that hasn't been properly implemented by ISPs for all last mile links to ensure clients are not only provided with bandwidth but also low latency. Is it just a matter of time I wonder.
I'm doing just that, running a VPN on a rented VPS and running all traffic through that. Then CAKE does its magic for download on that end, instead of running it in ingress mode on an IFB.
In my experience this works much better than shaping on ingress, as you can then actually control the queue before it reaches the last mile link, given that there's nothing else using bandwidth outside the tunnel.
It worked even better on DSL, where the sync rate rarely changed and I could get by using a script polling the sync rates from the modem every few minutes - then setting the shaper rates from that.
Now with LTE the issues I'm seeing is well covered in this thread. Beyond that one annoyance is the fact that I'm routing an extra IP address to my home router so I'm doing NAT on the VPS. Meaning the host isolation modes in CAKE doesn't work for download.
I've been toying with the idea of something that reads the conntrack table on the home router and sends that to the VPS (not literally sync the tables, just so it can be used to tag the flows to the right host in CAKE) and lets CAKE use that.
Yes theoretically that is not nice, but typically only one direction is loaded, so that moving the other un-loaded direction back to the configured minimum rate is the desired outcome anyway it is just happening a bit faster, no?
I would hypothesize this comes from CUBIC, as larger shaper increase steps will cause larger overshoots of the true bottleneck capacity, which in turn will lead to more data in flight and that in turn will cause larger/longer bufferbloat episodes. That can be an acceptable trade-off, but it certainly appears to be a consequence of faster rate "learning".
I am not sure that without a proper reflector this is going to work as they need packet spacing information at the receiver. Not impossible but that means a dedicated program at the other end.... at which point one needs an VPS an might be able to simply set up sprout as a tunnel for all traffic...
In theory that might work, in practice however I am not sure how hard this would be, given that wireguard is multi-threaded and will decrypt in parallel un multiple CPUs, I would assume piping wiregourd through a sprout tunnel might be easer to achieve.
The challenge with "auto-back-off" protocols is always that they are open to being crowded out if competing with less reactive flows.
So the problem is, end to end does not solve the issue reliably, otherwise we would not be in the mess that we are in. IMHO consistent low latency requires cooperation of end-points and network nodes.
Yes.
One would hope, but the problem here is that unless end-users are willing to pay a premium for low latency there is very little incentive for ISPs to invest in the additional hardware capabilities that enable reasonably low latency over their links to the end users. In 5G low latency has been turned into a marketing term, but looking at what they offer right now, it seems a bit optimistic....
Sure, we all agree that egress shaping is more immediate and more precise than ingress shaping, but "much better" really? (I am still impressed how well ingress shaping does work, especially with cake and its ingress keyword).
Did your ISP use SRA and did you really see big rate sync rate fluctuations on your DSL link during "showtime"?
You could try to remedy this with an additional ingress cake instance in your home which could be run simply in dsthost mode, relaying on the VPS shaper to deliver pe flow fairness. Then again, I might be overlooking something here ad that might gloriously fail.
Confirmed... your version (or my lack of tainting the other one) indeed works once a download is started...
Pardon my ignorance, but can you point me to the line(s) that govern this? And elaborate a little on where this restriction is tied to?
The thing is... without doing a download it doesn't work... once you do a big download... the script 'works' (i.e. it doens't just decay back to the no-download low afaik... and continues to dynamically scale around the correct top values in the case of my non-lte connection)
Capacity of the connection is known via max/min_dl_rate is it not? (or you are referring to
link bw counters and such?)
in otherwords...
I'd like to force this to start working imediately (without a download)
i'd also like to devise a 'bias-high' or 'invert-logic' for users without jumpy connections and such... (edit: ignore this i'm not really verbalizing what I'm thinking about correctly)
The following lines in get_next_shaper_rate implement the rate selection for all handled conditions:
if awk "BEGIN {exit !($cur_delta_RTT >= $cur_max_delta_RTT)}"; then
next_rate=$( call_awk "int(${cur_rate} - ${cur_rate_adjust_RTT_spike} * (${cur_max_rate} - ${cur_min_rate}) )" )
else
# ... otherwise take the current load into account
# high load, so we would like to increase the rate
if awk "BEGIN {exit !($cur_load >= $cur_load_thresh)}"; then
next_rate=$( call_awk "int(${cur_rate} + ${cur_rate_adjust_load_high} * (${cur_max_rate} - ${cur_min_rate}) )" )
else
# low load gently decrease the rate again
next_rate=$( call_awk "int(${cur_rate} - ${cur_rate_adjust_load_low} * (${cur_max_rate} - ${cur_min_rate}) )" )
fi
fi
This is called twice, once for download and once for upload...
Yes, but @Lynx goal is to decay back to the minimum, as on his LTE link he can only trust the minimum to be reliably available...
Yes, these set the limits for the rate adjustments, but when deciding whether to increase the shaper rate the script also looks whether the load (ration of actual traffic volume transferred during the last tick compared to the maximum that could have been transferred at the given shaper rate) exceeds a threshold (if the link is still massively underused increasing the shaper rate is not going to help much). The beauty of @Lynx's "look at the load" idea is that without load we have no chance of figuring out whether a given shaper setting is below the true bottleneck rate but we also would not profit from a higher shaper rate, so we just leave it alone in the case of low load. While bufferbloat tests require to generate saturating loads, here we simply use the existing "organic" load on the link which apparently works pretty well.
It does, it is just that the safe default is the configured minimum....
We discussed that in the past already, but without a decent use-case of such a functionality it is unlikely anybody will implement that.
That said, I think the solution would be to configure a third rate value per direction (resting_rate or default_rate) and control the decay such that without load the rate does not decay towards the minimum but towrds the default_rate, then @Lynx can set default_rate=$minimum_rate, you can set default_rate=$maximum_rate, and cautious users can set this somewhere between the extremes.... But again without a reason to implement that it might not actually happen.
I could imaging links which typically can sustain their maximum but during prime time might only be able to sustain say 50% and then setting the default to 100% and the minimum to 50% would still allow for better latency-uder-load at prime time without sacrificing throughput during the day... but I digress.
yes... this is sort of what i'd had in mind... a sort of 'decay_bias/rate_change_bias' if you will...
a good place to factor in some exponential / express scaling perhaps (which will greatly benefit LTE due to jumpy physical layer properties)...
I guess there are quite a few good ways to define / overlay bias motivations...
i.e.
calc_median_jump() {
#store and calc the median rate_jump for the last X(15?) reads
#actually medians not the right word...
#total_max_jump over last 15 reads etc. etc.
#optional> what percent of max_rate-min_rate is this delta
#SMALL MED LARGE -> scale the jump_rate further?
#if last jump was in same direction... add some more bias
#or change SMALLJUMP > MEDJUMP etc. etc.
}