Hi!
Although not an Opewrt directly related question, it has to do with bufferbloat, where Openwrt shines, so...
I would like feedback from you guys to see if I'm going in the right direction.
What I want?
To plot periodic and continuous bufferbloat measurements (in my case, I'll do it in Cacti).
How?
The core functionality lies in a script that will run periodically in cron.
Here it is:
#!/bin/sh
wget -q https://releases.ubuntu.com/20.04.4/ubuntu-20.04.4-desktop-amd64.iso & echo $! > pid.txt &
ping -qc 20 1.1.1.1 > bufferbloat.txt; kill $(cat pid.txt); rm ubuntu-20.04*
The idea is to start a download (in this case, Ubuntu ISO) and, in parallel, to ping twenty times some IP address (in this case, 1.1.1.1) and redirect the ping output to a file named bufferbloat.txt. As a side note, the script also manages to interrupt the wget command after ping ends, and also deletes the data that has already been downloaded.
The content of bufferbloat.txt will look like this:
gustavo@srv2:~/bin$ cat bufferbloat.txt
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
--- 1.1.1.1 ping statistics ---
20 packets transmitted, 19 received, 5% packet loss, time 19030ms
rtt min/avg/max/mdev = 11.237/56.486/143.167/36.687 ms
If I got it right, the average rtt (avg) could be thought as a bufferbloat "measurement", and then it's just a matter of classifying it according to this standard:
Less than 5ms (average of down bloat and up bloat) - A+
Less than 30ms - A
Less than 60ms - B
Less than 200ms - C
Less than 400ms - D
400ms+ - F
(https://www.dslreports.com/faq/17930)
Am I going in the right direction?
(Something I noticed now while writing this post is that the bufferbloat classification is the the download AND UPLOAD timings, so I guess I have to add to the script the upload part then get the average of the download avg and upload avg ...)
NOTE: Plotting is TBD, after getting the script right
Any advise will be welcome!
UPDATE: Since this thread was listed in this other, very useful thread, I'm obliged to update you.
I'm no longer running this script, because I concluded that doing a speed test every minute would either raise suspicions on my IP as well as drain bandwidth from my ISP plan.
But I still pursue ways of measuring and monitoring bufferbloat.
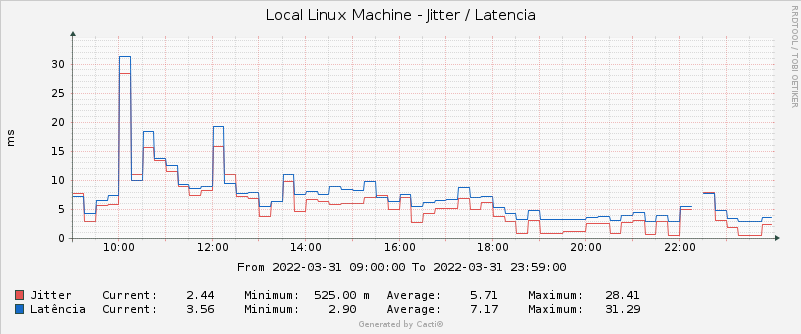
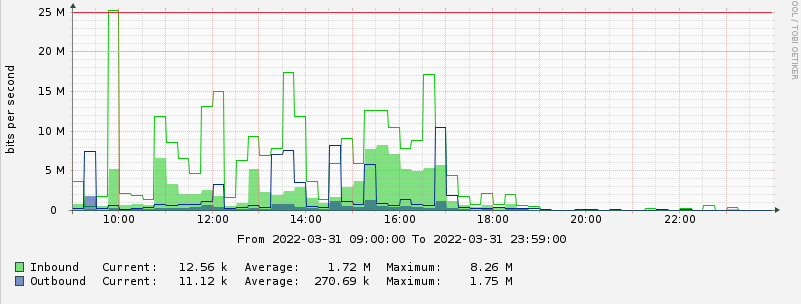
Today, I plot ping results every minute and focus on max latency values. I even account for percentiles distribution so that I can get a hint on bufferbloat events.
This is the graph where I get it
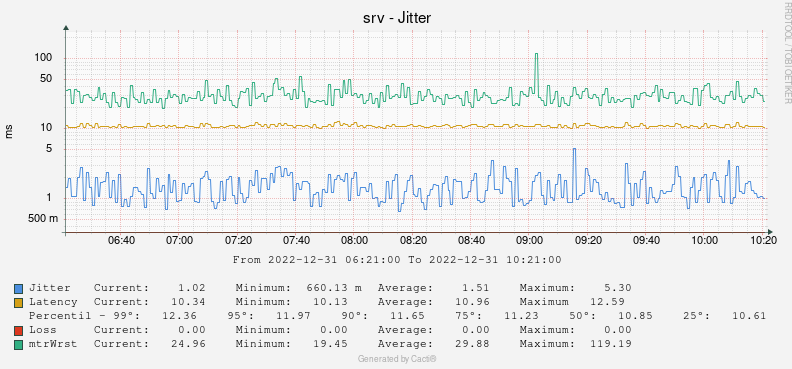
(Forget about the title...).
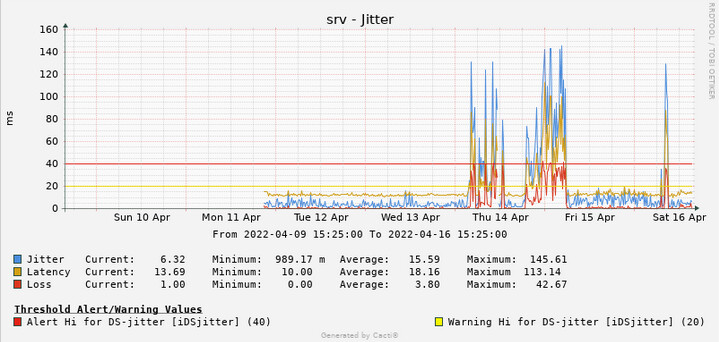
However, since Ookla's speed test now shows latency under load, I also automated speed tests, this time every three hours, and plot the idle, download and upload higher latencies.
The cron script parses these values:
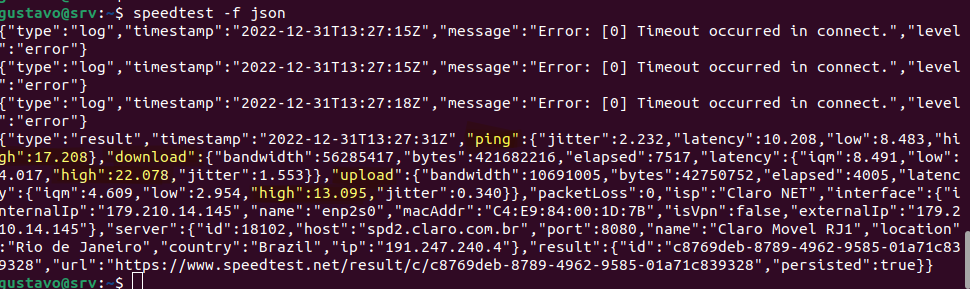
The resulting plots serve as complementary data to the ping graphs, all of that to help me infer if I'm a victim of bufferbloat at any given moment in time.
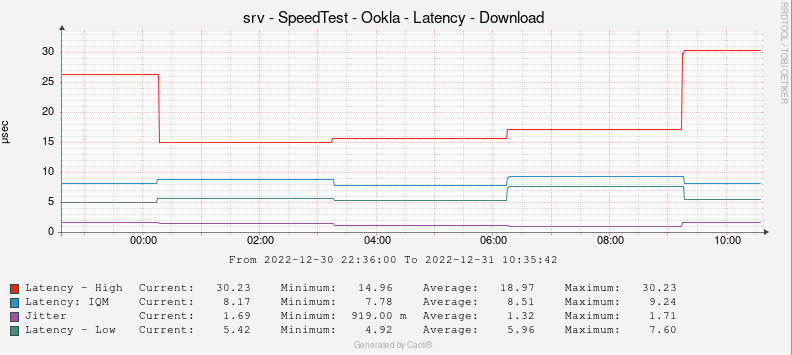
(I have similar graphs for idle and upload latency measurements from Ookla)
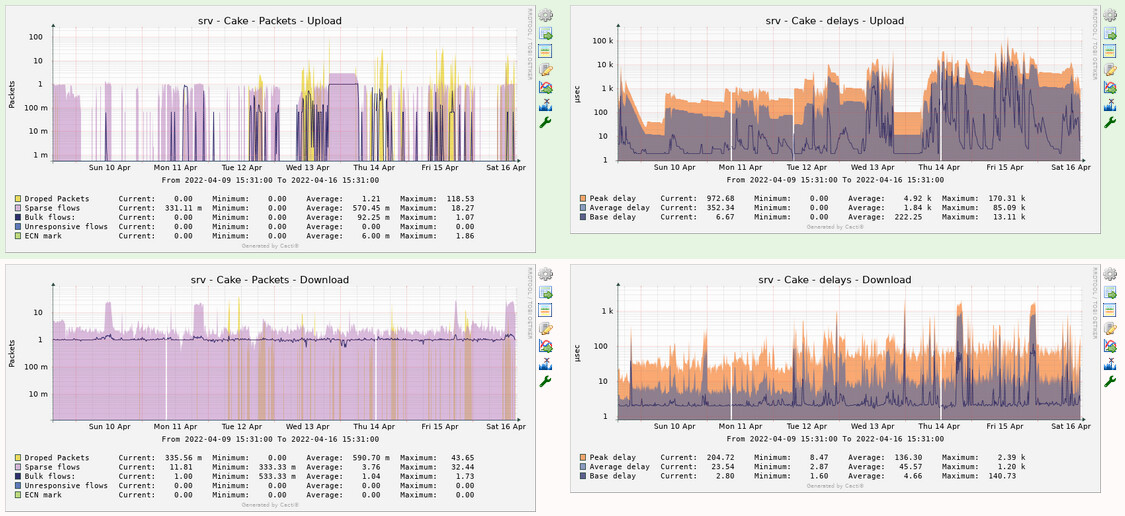
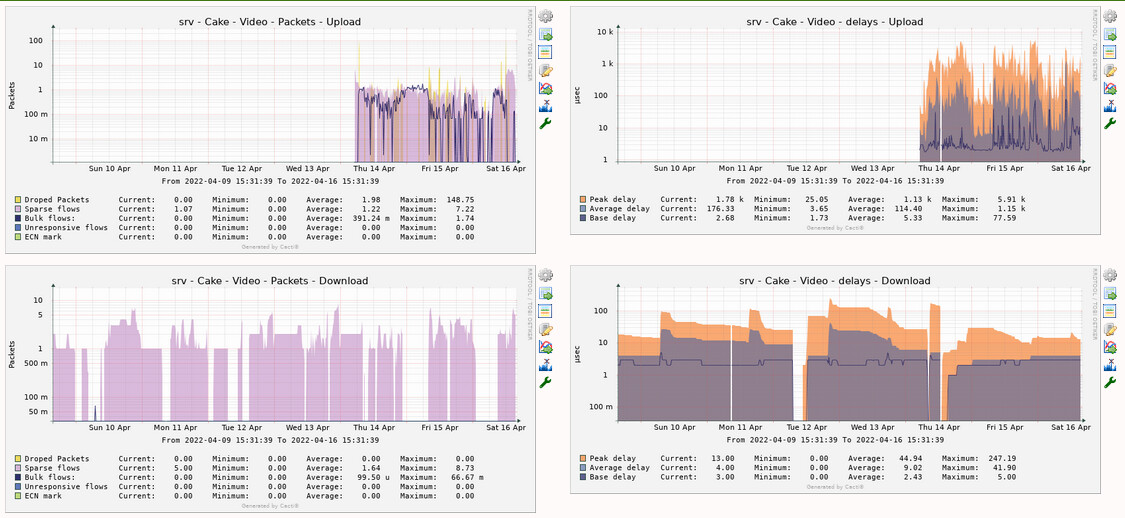
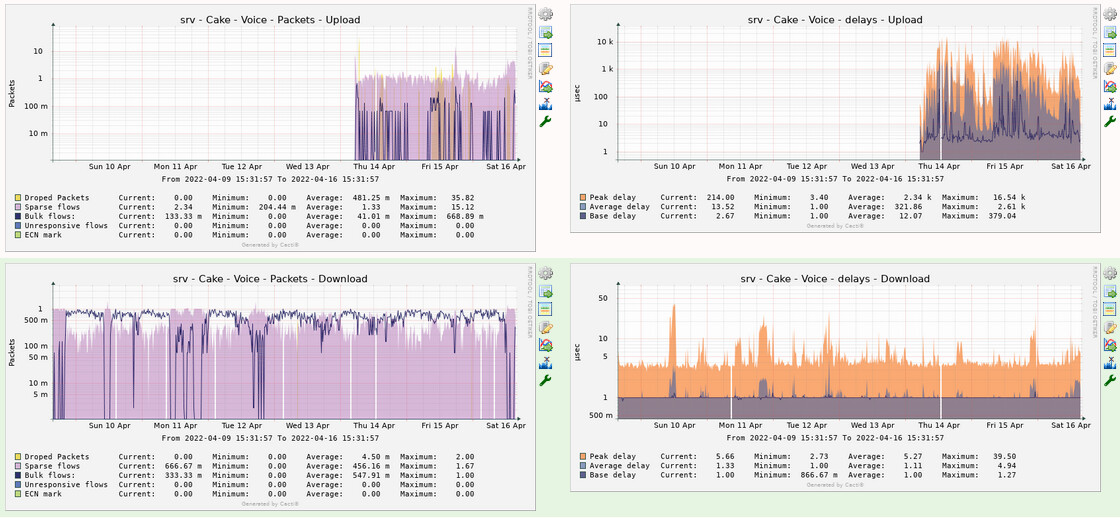
Finally, I think the best and most precise way of measuring /monitoring/plotting bufferbloat is @moeller0's Octave parser, bundled together with @Lynx's cake-autorate script.
Besides being very precise and granular (miliseconds precision, not minute like my plots above), the graphs are also very pretty...
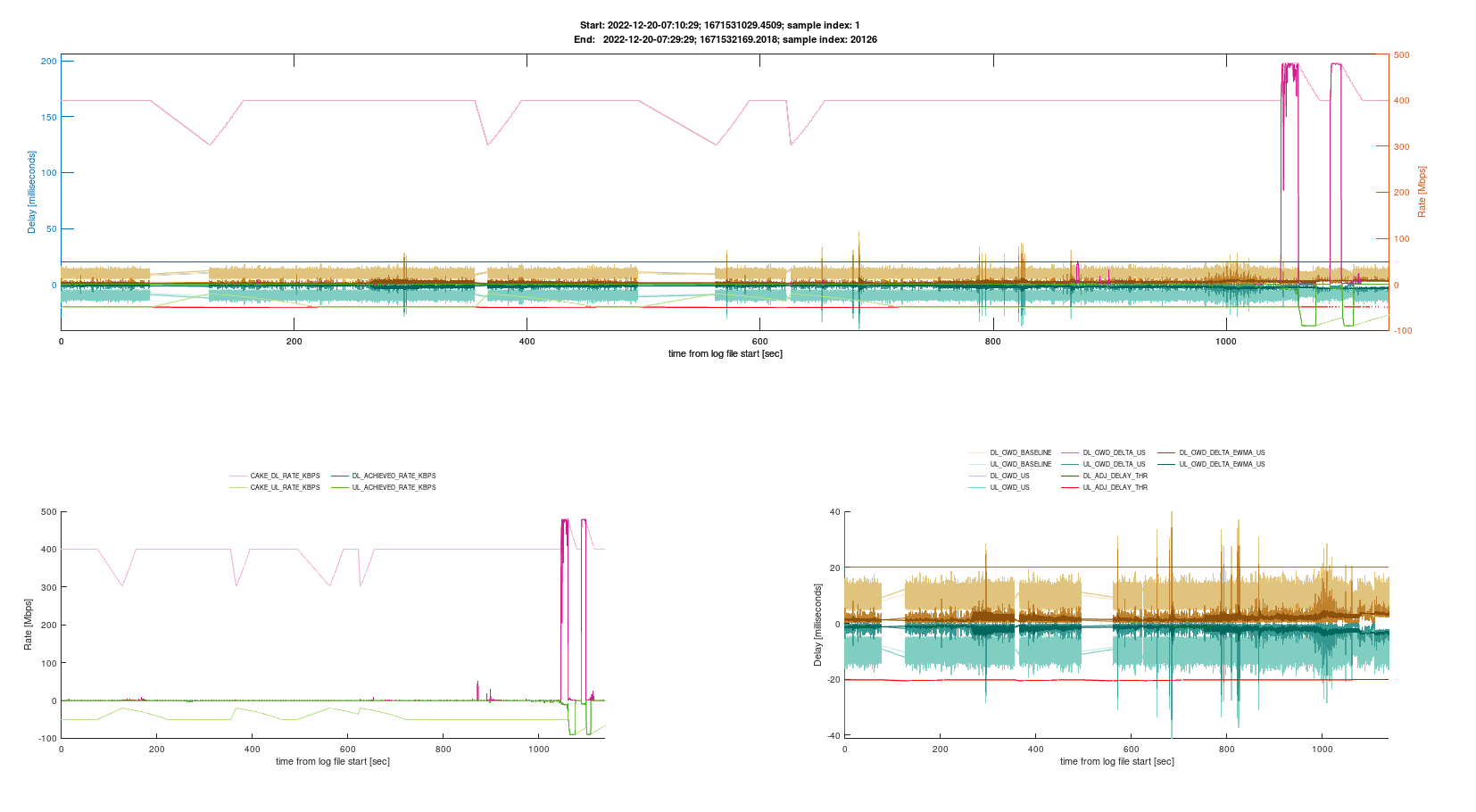
(In this plot, bufferbloat is shown as brownish spikes when they go above the red line threshold, better visualized in the bottom right graph)
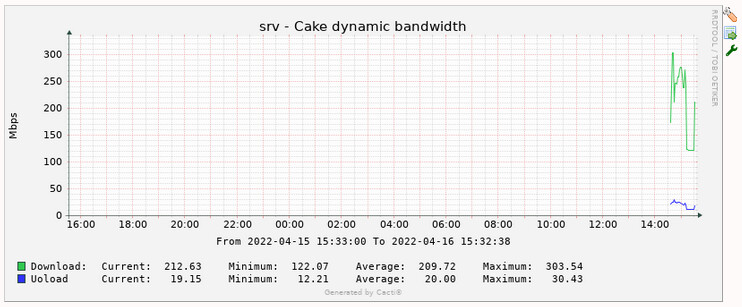
You don't have to bother about changing cake bandwidth, since cake-autorate can run in "monitor" mode (it just logs its measurements, but doesn't actually change cake bandwidth limits).
All this to say that this thread was just a starting point, that brought me to cake-autorate script and also helped me realize that my ping graphs can still be useful, although they give me only a rough, imprecise, indirect snapshot of bufferbloat.