That is IMHO even better to answer the question how high can sqm-scripts traffic shapers be pushed on decent hardware... I simply lack the hardware to test anything above 1 Gbps myself.
actually, I can't do 10, I just have a dual port 10GbE server card, only got it because my ISP's offering 10/10gbit internet access.
you'll have to settle for 2.5, sorry.
3 Likes
That looks like a pretty pricy set-up you have there ![]()
You are operating as your own ISP? If yes, maybe also have a look at libreqos as they seem to target similar hardware as yours.
No idea about PPPoE, but honestly, if you operate as ISP maybe consider getting rid of that "tunnel" for your customers? At higher rates PPPoE de/en-capsulation becomes a noticeable part of the network load on typical home routers....
Well, traffic shaping is CPU intensive, so if you do this for enough users it will cost you some CPU... and the way traffic shaper work is they need to signal congestion somehow, one method is to drop packets, so dropping packets on congestion is just fine and acceptable. In a recent discussion someone remarked that on a busy link one might expect up to 1% packet loss which is almost not noticeable (however this is load dependent loss, random loss at 1% is quite terrible...)
1 Like
Or perhaps serviced offices for businesses?
I am not an ISP, just a network agent! Currently, I have no speed limit for all PPPoE clients! It is because there is no speed limit, so I often complain about the network card, the network speed is not enough, the game is stuck, and the sending of videos and pictures is slow Wait for the FAQ!
I tried the latest version of SQM with a small MediaTek MT7621 wireless router, and the speed-limited PPP interface is fine for now!
For the LibreQoS you mentioned, I will learn more! In addition, I found that daloradius can also limit the speed of PPPoE guest rooms!
I will test SQM to limit the speed of all PPPoE online clients in two days, and see how it works!
I mean, I was doing shaping on J1900 at gigabit, so I'm sure this is way more power than needed for Gigabit if tuned correctly.
fifo would just be first in first out, all flows in the same queue. This is kind of the stuff you might expect inside a switch or other dumbish hardware for example
Yes, my assumption was just that you take some Linux kernel defaults, which is normally pfifo_fast and 1000 packets. I don't know if the kernel scales that up when you use 2.5 or 10Gbps ports. But I suspect not.
Buffers were easily made way too big for ~10Mbps ADSL but my impression is that for 10Gbps most hardware is still using by default about the same size buffers and therefore would experience 1000x less delay.
I really don't know what people are doing at the 100Gbps and up range. I suspect it's a lot of custom hardware and so depends entirely on your vendor.
1 Like
Better ethernet drivers use BQL to size the driver buffer dynamically (based on service time instead of a packet count).
We still need to deal with the fact that in the download direction the ISP will likely keep buffers allowing for up to 100ms buffering/delay. The issue is if the ISP uses shallower buffers for many applications achievable single thread throughput will crater... so an ISP is more likely to overbuffer than underbuffer.... Given how some parties try to push latency awareness this might cahange but IMHO the status quo is still that ISPs generally opt for more throughput than lower latency.
On backbones the trick often is simply to keep utilization below 100%, on switch fabrics in data centers people use quite elaborate congestion signaling and counter-action methods....
LibreQoS does not support OpenWrt for now
without flow control, which is almost never encouraged on ethernet, is there a scenario where BQL makes any difference for Ethernet into a switch? My impression is if you put N bytes in the hardware queue then you'll always take 8N/BW seconds to drain it. The switch might drop some of them, but basically there's nothing to keep you from slamming packets onto the wire. I could see it being a notable boost for WiFi or whatever where the medium is in contention and the transmit speeds vary.
Soif the router has a 1N wan link but lan an wlan generate >1N traffic BQL will engage...
1 Like
True, however do you need necessary to run your shaper beast under OpenWrt?
I plan to test fq_codel + simplest_tbf.qos scheme
Only one simple reason to prefer SFF over USFF for this purpose, the ease of adding slim-line PCIe cards as needed. 2.5GBASE-T for ~15 bucks, or slightly higher on the price scale 4*1000BASE-T (>= 60 bucks) or 10GBASE-T (>=90 bucks). Same story if you need to add SFP/ SFP+ cards.
USFF wins on the idle power side, but SFF tends to be cheaper to purchase and allows you modest expansion potential (3-4 slim-line PCIe slots). While USB is always an option, mounting the cards inside might be beneficial for an always-on infrastructure device (more robust, harder to mess up, easier to label the ports),
1 Like
I wish that my isp could keep up with my local network speed - i have two 40 gig port for him ready.
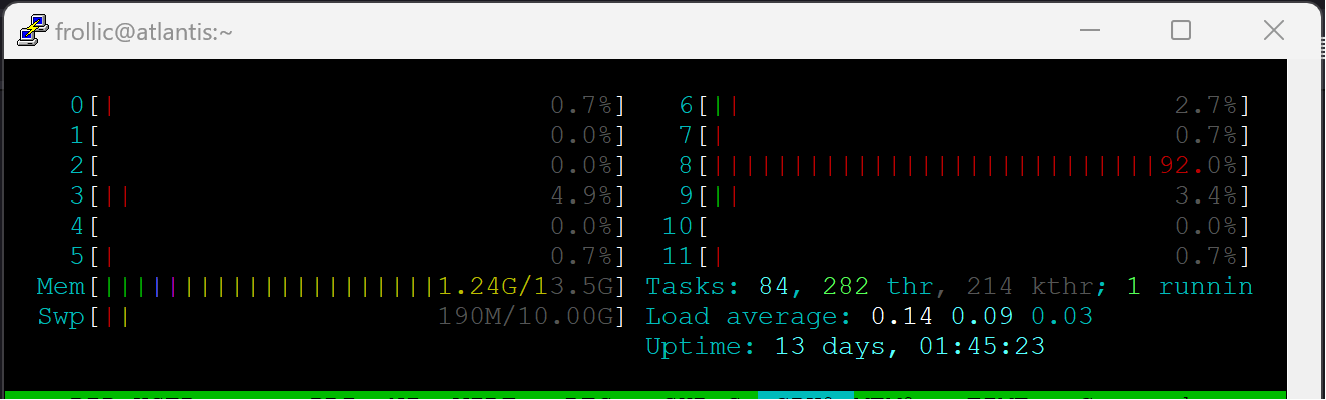
I know this post is 2 weeks old but I want to clear it up. You are misreading your graph, this is not "barely any cpu". Looks like SQM is using about 75% of one cpu core. That's great for a 1G link but it definitely will not scale to 2.5g.
An i5 1235U has 10 cores that can run 12 threads. A single threaded process pegging a single core at 100% will show as 8.3% cpu usage on a graph.
I want to clear it up. You are misreading your graph, this is not "barely any cpu". Looks like SQM is using about 75% of one cpu core.
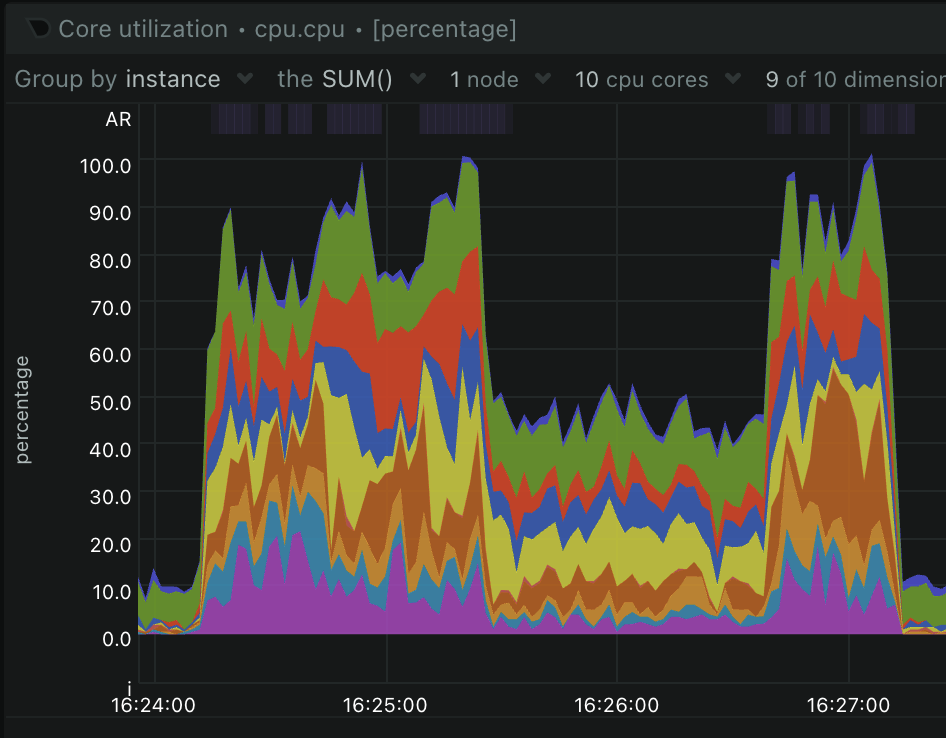
Here's the per core utilization:

No core ever goes above 20%, and several of the e-cores mostly stay in the 10-15% range.
1 Like
That's normal, the process is not pegged to a core, it move's between cores to avoid overheating any single core.
The i5 1235U is definitely an excellent chip for a router. It's ability to boost clocks when lightly threaded gives it monster single threaded performance. The fact that it can do 1G with SQM/cake is pretty amazing.
the process is not pegged to a core, it move's between cores to avoid overheating any single core.
We've covered this here, but that user deleted all of their posts. I'm not going to respond further to you because you sound just like that user.
Well,
it took some time.
When I shut down the server, to install the new dual 2.5GbE card, the server never came back up, motherboard died ... ![]()
Anyway, I did a small test, with iperf, and never managed to get past 1.7Gbits/sec because I maxed out one of the CPU cores.
root@OpenWrt:~# iperf -c 192.168.10.254
------------------------------------------------------------
Client connecting to 192.168.10.254, TCP port 5001
TCP window size: 85.0 KByte (default)
------------------------------------------------------------
[ 1] local 192.168.30.1 port 39940 connected with 192.168.10.254 port 5001
[ ID] Interval Transfer Bandwidth
[ 1] 0.00-10.04 sec 1.98 GBytes 1.70 Gbits/sec
Sender was a Roqos RC10 with an
0bda:8156 Realtek USB 10/100/1G/2.5G LAN
Receiver was a server using an AMD 5650G APU.
24:00.0 Ethernet controller: Realtek Semiconductor Co., Ltd. RTL8125 2.5GbE Controller
This server doesn't use openwrt, but Fedora, kernel is v6.4.11.
Strange thing is, I got the same result, with a maxed out core, when I wasn't NATing, simply sending
data between two IPs on the same subnet.
Might get luckier if I use jumbo frames.
I did a test with my i5 1235U that has 2.5G ports. I have an extra interface on my router so I set it up with an IP and connected my laptop to it. My NAS box is on another port on the router, which is a member of a bridge. I ran an iperf3 test with 8 connections. Traffic is flowing from the NAS to the laptop. The router in this test is routing and firewall'ing between the two interfaces but not NAT'ing. tcp-segmentation-offload,
generic-segmentation-offload, and generic-receive-offload are all turned off.
iperf3 with no CAKE:
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 177.00-178.00 sec 30.5 MBytes 256 Mbits/sec
[ 7] 177.00-178.00 sec 35.5 MBytes 298 Mbits/sec
[ 9] 177.00-178.00 sec 31.5 MBytes 265 Mbits/sec
[ 11] 177.00-178.00 sec 28.7 MBytes 241 Mbits/sec
[ 13] 177.00-178.00 sec 38.7 MBytes 325 Mbits/sec
[ 15] 177.00-178.00 sec 41.5 MBytes 348 Mbits/sec
[ 17] 177.00-178.00 sec 39.2 MBytes 329 Mbits/sec
[ 19] 177.00-178.00 sec 34.3 MBytes 288 Mbits/sec
[SUM] 177.00-178.00 sec 280 MBytes 2.35 Gbits/sec
- - - - - - - - - - - - - - - - - - - - - - - - -
iperf3 with CAKE set to 2300mbit:
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 137.00-138.00 sec 32.8 MBytes 275 Mbits/sec
[ 7] 137.00-138.00 sec 32.8 MBytes 275 Mbits/sec
[ 9] 137.00-138.00 sec 32.8 MBytes 275 Mbits/sec
[ 11] 137.00-138.00 sec 32.8 MBytes 275 Mbits/sec
[ 13] 137.00-138.00 sec 32.8 MBytes 275 Mbits/sec
[ 15] 137.00-138.00 sec 32.8 MBytes 275 Mbits/sec
[ 17] 137.00-138.00 sec 32.8 MBytes 275 Mbits/sec
[ 19] 137.00-138.00 sec 32.8 MBytes 275 Mbits/sec
[SUM] 137.00-138.00 sec 262 MBytes 2.20 Gbits/sec
- - - - - - - - - - - - - - - - - - - - - - - - -
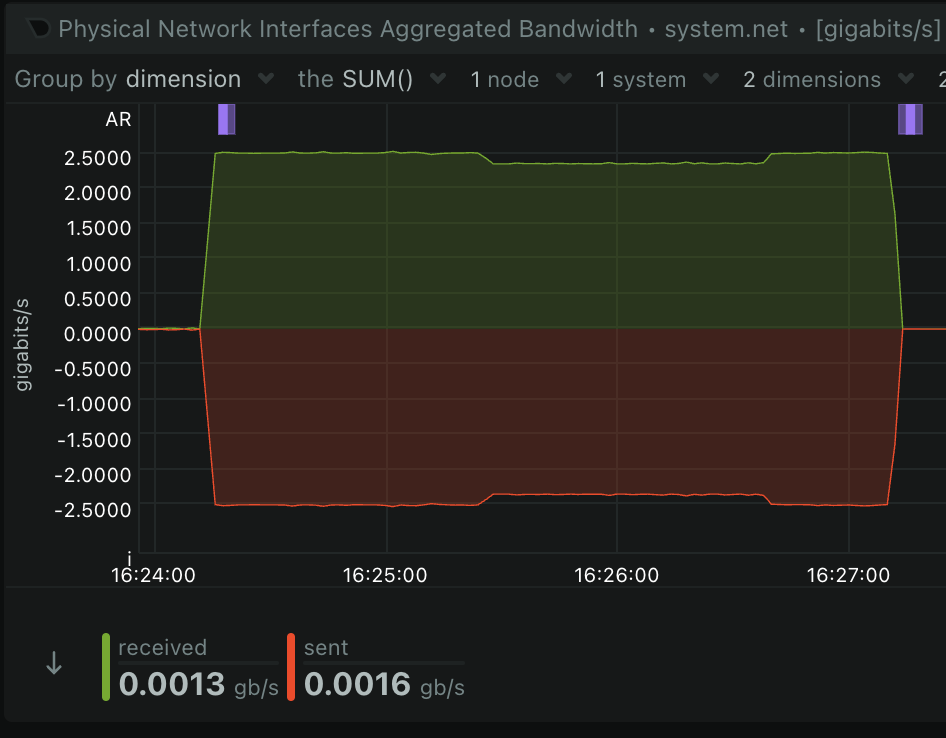
As I said earlier in the thread, it has no problem doing 2.5G. Below are various graphs showing it working. The first half of the graph is with no qdisc. The second half is when I added the CAKE qdisc. The last little bit is where I deleted the CAKE qdisc before stopping iperf3.
Throughput, you can see where CAKE is shaping it to 2.3G:
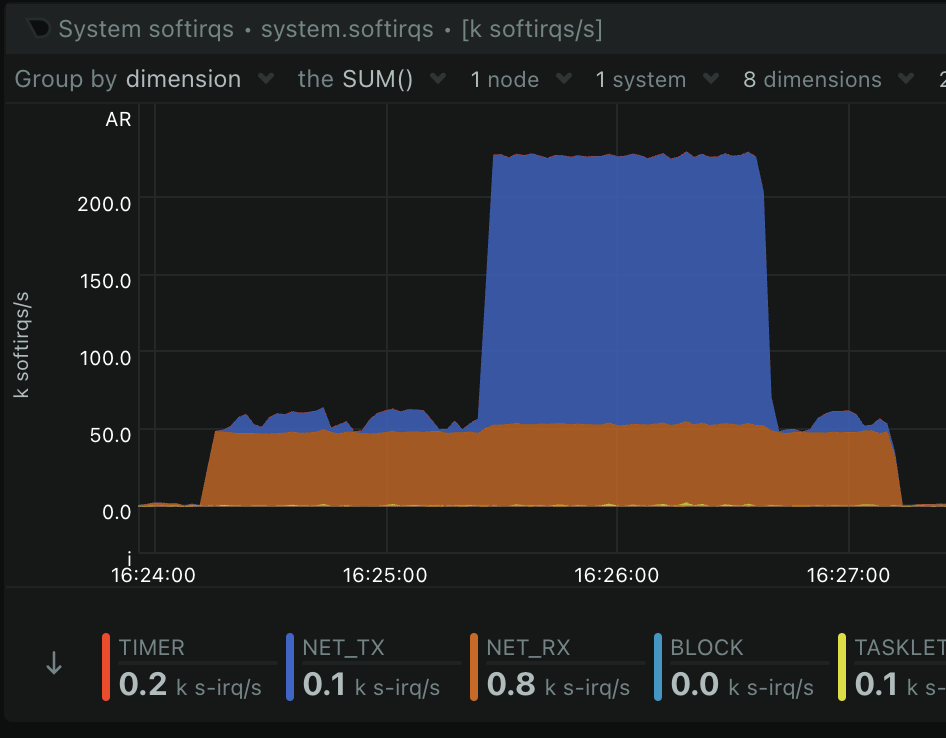
Softirqs, you can see NET_TX goes nuts when CAKE is enabled:
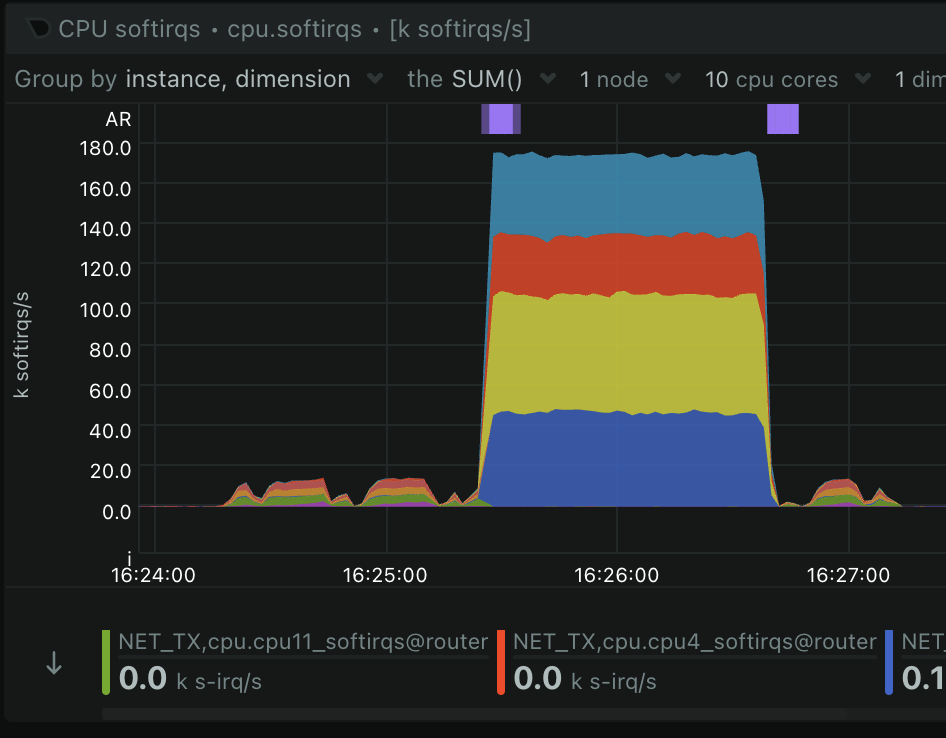
Breaking down the NET_TX softirqs. You can see they are distributed across 4 cores:
Per core CPU utilization:
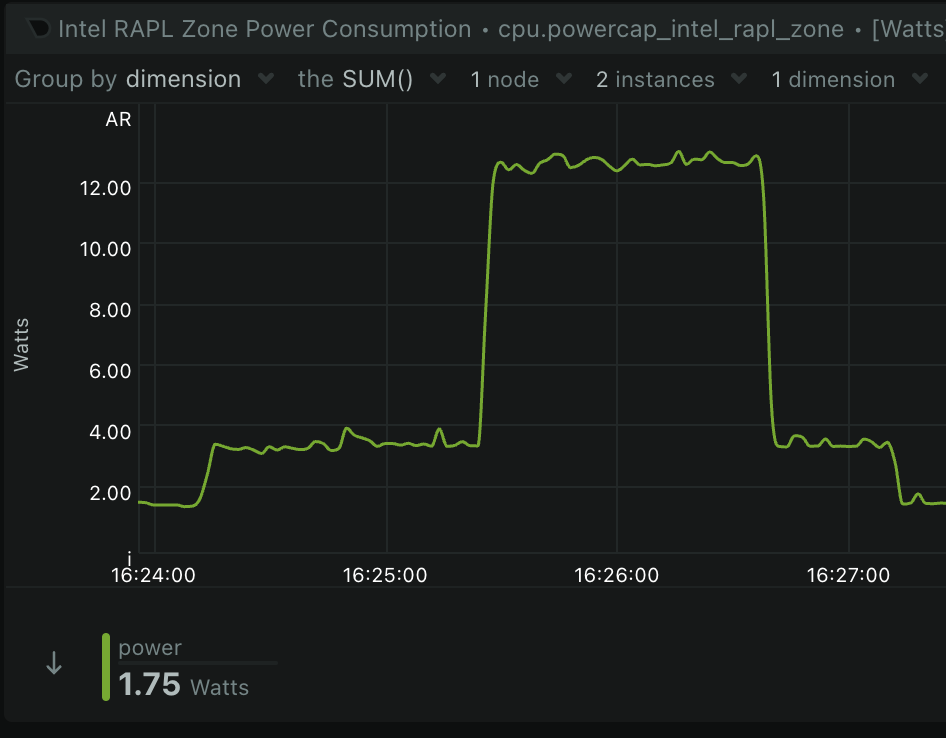
Power consumption:
1 Like