# This file is interpreted as shell script.
# Put your custom iptables rules here, they will
# be executed with each firewall (re-)start.
# Internal uci firewall chains are flushed and recreated on reload, so
# put custom rules into the root chains e.g. INPUT or FORWARD or into the
# special user chains, e.g. input_wan_rule or postrouting_lan_rule.
# This file is interpreted as shell script.
# Put your custom iptables rules here, they will
# be executed with each firewall (re-)start.
# Internal uci firewall chains are flushed and recreated on reload, so
# put custom rules into the root chains e.g. INPUT or FORWARD or into the
# special user chains, e.g. input_wan_rule or postrouting_lan_rule.
## flush mangle table
iptables -t mangle -F FORWARD
iptables -t mangle -A FORWARD -j ACCEPT
## defaulttraffic
iptables -t mangle -A FORWARD -I br-lan -m connmark --mark 0x0/0xf0 -j ACCEPT
iptables -t mangle -A FORWARD -I br-lan -j DSCP --set-dscp 0
##ACCEPT ROUTERIP
iptables -t mangle -A FORWARD -i eth+ -s \10.0.0.1/32 -j ACCEPT
##packetlimit
iptables -t mangle -A FORWARD -p udp -s 192.168.1.2 -m hashlimit --hashlimit-name gamingudp --hashlimit-upto 250/s --hashlimit-burst 250 --hashlimit-mode srcip,srcport,dstip,dstport --hashlimit-htable-gcinterval 1000 --hashlimit-htable-expire 1000 -j CONNMARK --set-mark 0x46 -j ACCEPT
iptables -t mangle -A FORWARD -p udp -s 192.168.1.2 -m connmark ! --mark 0x46 -m conntrack -m multiport ! --ports 53,5353,60887 -m connbytes --connbytes 0:770 --connbytes-dir both --connbytes-mode avgpkt -j DSCP --set-dscp 46
## game traffic
iptables -t mangle -A FORWARD -p all -s 192.168.1.2 -m multiport ! --ports 53,5353,60887 -j DSCP --set-dscp 46
iptables -t mangle -A FORWARD -p all -d 192.168.1.2 -m multiport ! --ports 53,5353,60887 -j DSCP --set-dscp 46
#DNS traffic both udp and tcp
iptables -t mangle -A FORWARD -p udp -s 192.168.1.2 -m multiport --port 53,5353 -j DSCP --set-dscp 26
iptables -t mangle -A FORWARD -p tcp -s 192.168.1.2 -m multiport --port 53,5353 -j DSCP --set-dscp 26
iptables -t mangle -A FORWARD -p udp -d 192.168.1.2 -m multiport --port 53,5353 -j DSCP --set-dscp 26
iptables -t mangle -A FORWARD -p tcp -d 192.168.1.2 -m multiport --port 53,5353 -j DSCP --set-dscp 26
##firewall
iptables -A FORWARD -s 192.168.1.2 -j ACCEPT
iptables -A FORWARD -d 192.168.1.2 -j ACCEPT
##resetlinks
iptables -t filter -A FORWARD -m conntrack --ctstate established,related -m dscp ! --dscp 0 -j ACCEPT
#tcpdump
#tcpdump -i br-lan and udp and portrange 1-65535 and !port 53 and ! port 80 and ! port 443 -vv -X -w /root/cap-name.pcap
Powered by LuCI openwrt-18.06 branch (git-19.020.41695-6f6641d) / OpenWrt 18.06.2 r7676-cddd7b4c77
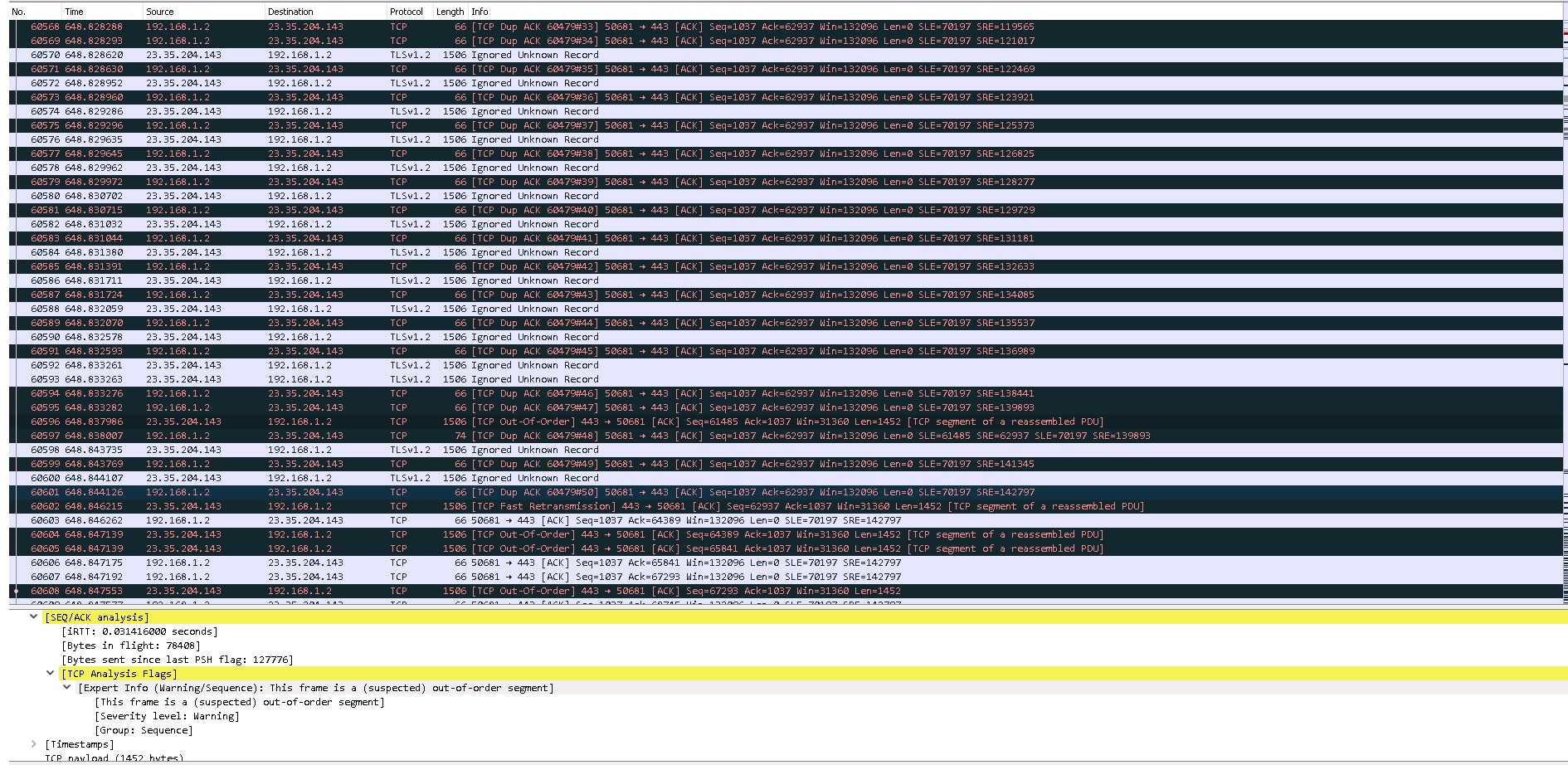
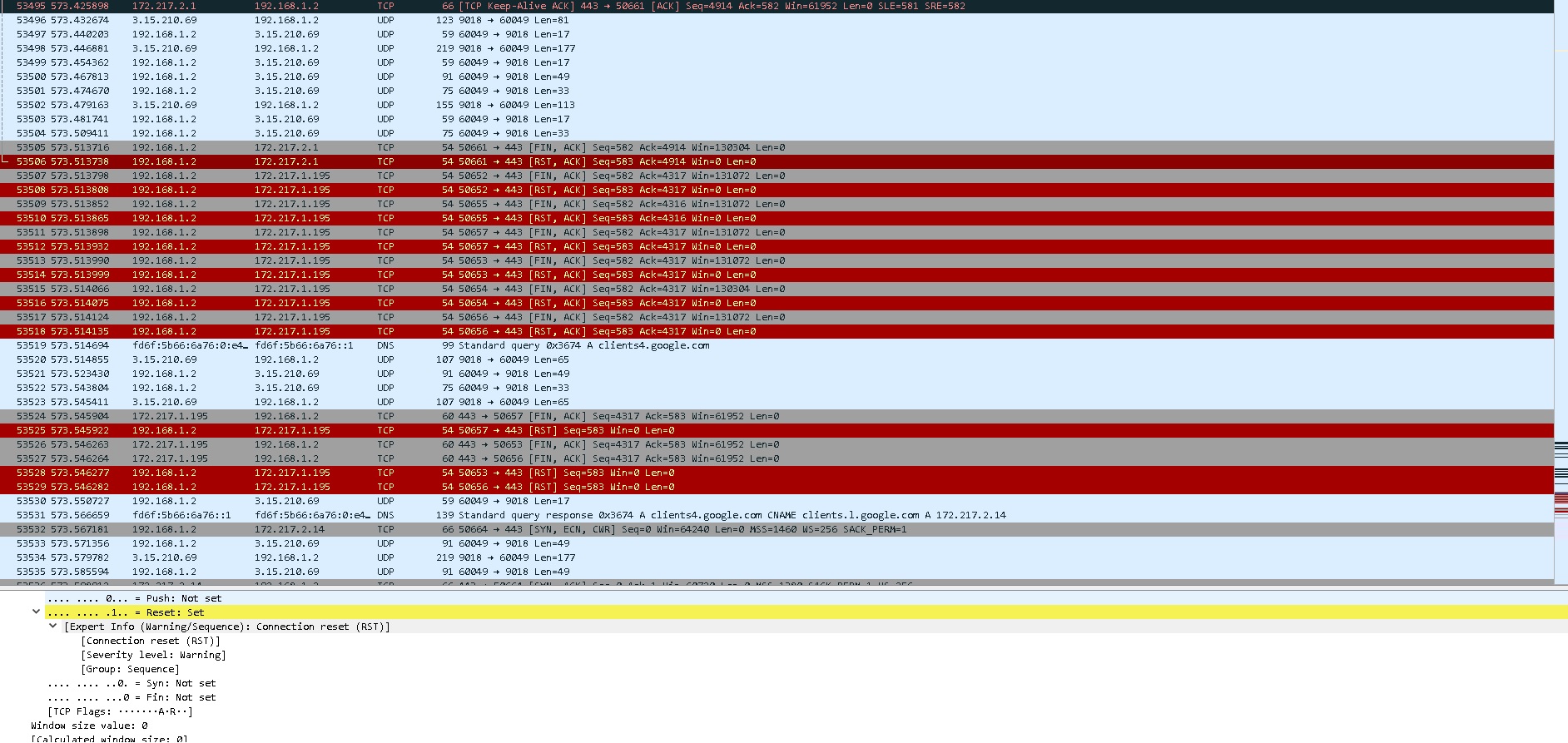
I'm running into dropped packets abnormally. I am confident this is a TCP connection issue is there any way to clean up the 1506kb TCP connection using hashlimit and conntrack. This is my current ruleset and it is not working the switch from advancedtomato to openwrt cake cleaned up the UDP transmissions but it just doesnt transmit and receive to the game servers like video, it transmits like a .gif looking stutter when I input user actions and it has been happening consistently only during any type of my inputs. One thing i've noticed in Wireshark is that there are 0 UDP issues occuring they are all TCP.
I have sqm configured to allow for 1.5mb because thats what my tcp is reading in wireshark, and my udp is generally around 770kb avg. So I just opened up my sqm for 3 mb to account for 1.5mb packets each way.
The config I want to use is:
EF/46 for all protocols for my gaming rig
MED/26 for DNS
LOW/0 for all lan traffic
And basically this bit:
iptables -t mangle -A FORWARD -p udp -d 192.168.1.2 -m hashlimit --hashlimit-name gamingudp --hashlimit-above 220/sec --hashlimit-burst 100 --hashlimit-mode srcip,srcport,dstip,dstport -j CONNMARK --set-mark 0x46
iptables -t mangle -A FORWARD -p udp -d 192.168.1.2 -m connmark ! --mark 0x46 -m multiport ! --ports 53,5353,60887 -m connbytes --connbytes 0:700 --connbytes-dir both --connbytes-mode avgpkt -j DSCP --set-dscp-class CS5
The main point here is there is no other upload traffic on the lan whatsoever so my game traffic should be transmitting fine but of course it is hitting congestion. Now when I look at hashlimit and connmark I don't feel like this applies to my config because I can just literally cs0 everything and cs5 my rig by ip/mac -so do I have this in there for nothing?
Another question is since my ISP doesn't require the VLAN do I need to use VLAN? Could that be a problem, but then my wifi would not be able to be used right?
The dsl line should be clean with very little local traffic day or night - none of the other lines would be torrenting so this is not an issue either. Right now I am using a zyxel dsl modem instead of the Asus because for some reason the Asus will knock out the dsl line and I have to get a tech out to the dslam just to get my signal back up even though I configure them similarly.
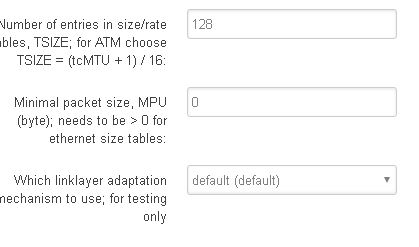
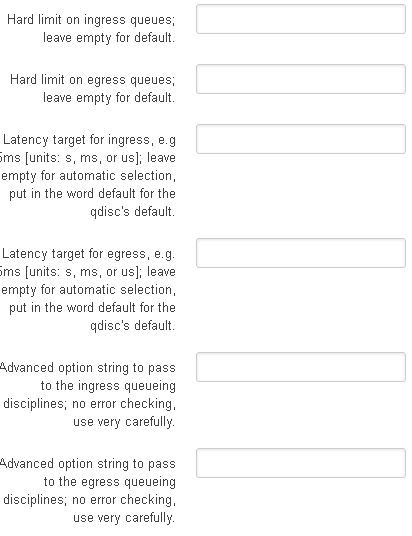
Now I have cake/layer cake on egress for interface on eth1.2(wan, wan6 - not on the pppoe-wan tunnel interface) and cake/piece of cake on egress for interface eth0.1(lan - not on the br-lan bridge). So I begin to adjust my sqm settings and this was not a problem because there was just no changes on one sqm (one egress+ingress) vs. 2 sqm(wan egress layer cake, lan egress piece of cake). The numbers were adjusted to allow for 33% or 95% sqm headroom and there was no change. No change for the sqm type(cake vs. layercake) on LAN egress, keeping layercake on WAN egress for DSCP marking. I could not or as dlakelan has stated it is impossible to vethpair on OpenWRT and it involves using Debian linux coding - I looked into that and for my Linksys32xx it is literally a page where you copy the code and build your entire modem config using linux and it is a complete mess. It would just end bad. I would not even be able manage the scripts if I had a problem, especially if I brick it over and over without knowing why. I cannot use linux without knowing excatly what would cause the brick if I even manage to recover the $250 device -and I imagine I will be soldering some special part in in the middle of all this and i'm sure that there are other devices running this type of user interface with a better support system on a different modem but I have this modem and OpenWRT.
WAN above, LAN below
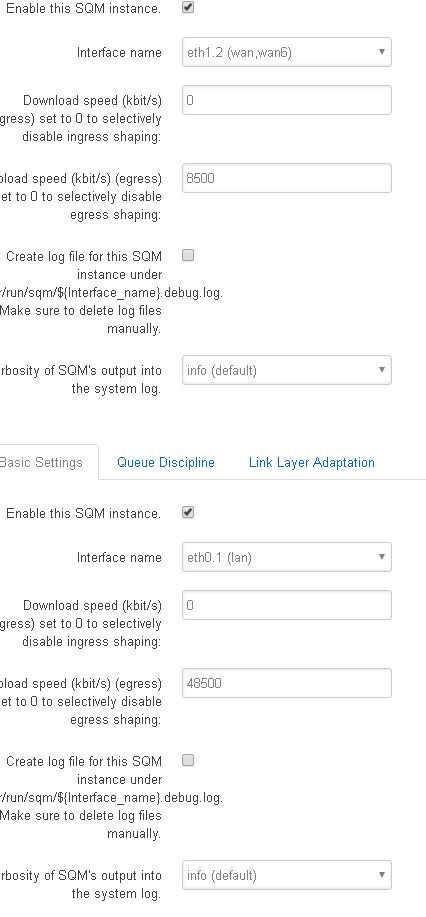
WAN

LAN
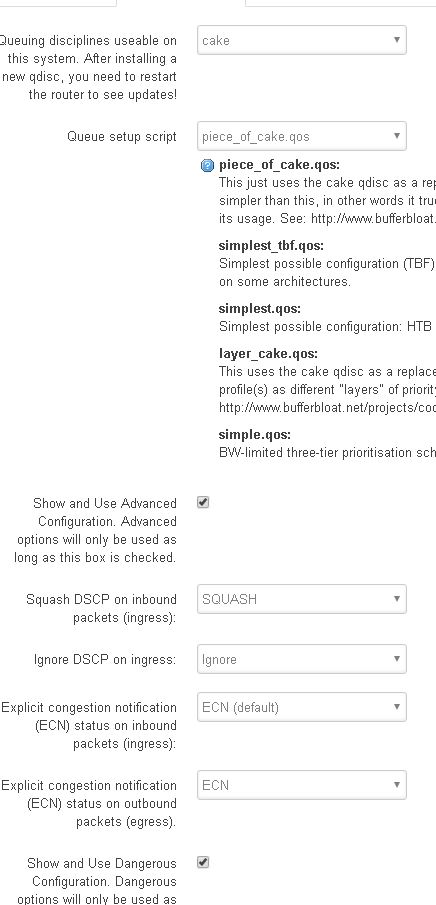
LAN w/dual-dshost ingress and ECN enabled

VDSL2 no VLAN from ISP config
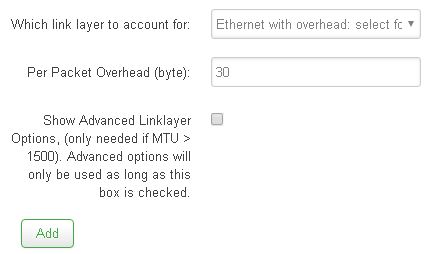
Switches
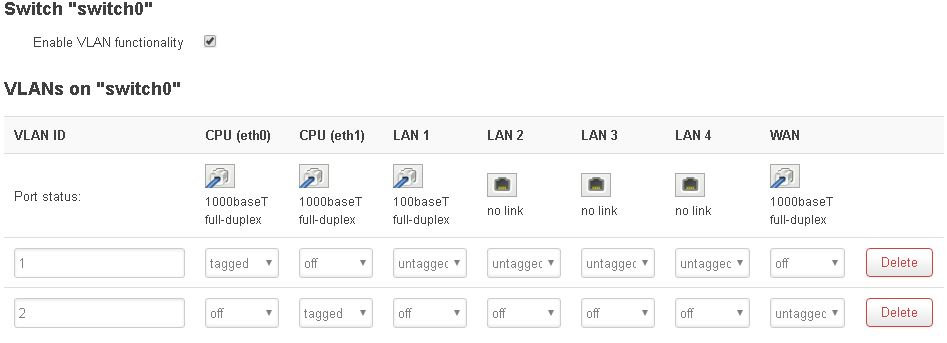
Wireshark
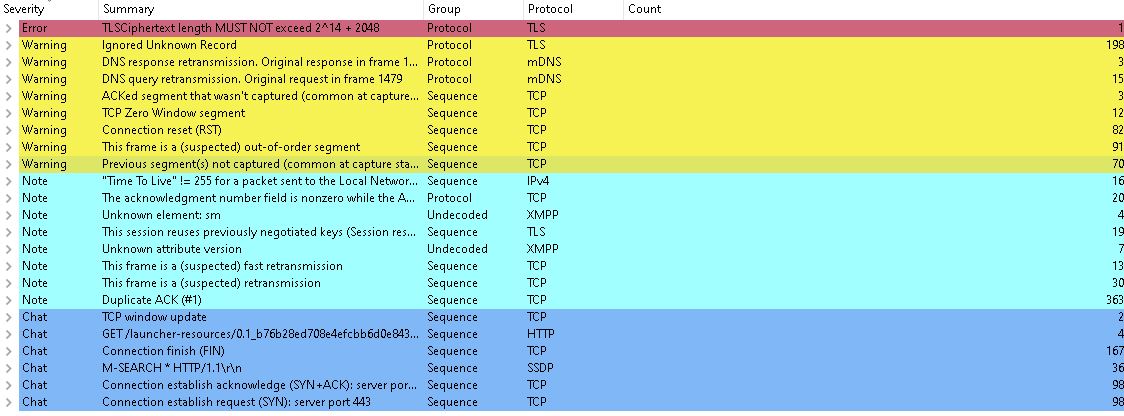
One >1 min fortnite session:
Statistics
| Measurement | Captured | Displayed | Marked |
|---|---|---|---|
| Packets | 18630 | 18630 (100.0%) | — |
| Time span, s | 425.171 | 425.171 | — |
| Average pps | 43.8 | 43.8 | — |
| Average packet size, B | 294 | 294 | — |
| Bytes | 5473387 | 5473387 (100.0%) | 0 |
| Average bytes/s | 12 k | 12 k | — |
| Average bits/s | 102 k | 102 k | — |
Interfaces: pppoe-wan/wan/wan6, br-lan(lan,wireless)
PC(capable of sustaining 144fps) > 5 ft cat5e > Zyxel/ASUS DSL68u(new firmware)> 5 ft cat 5e > Linksys 3200ACM(stock firmware)/ OpenWRT install(50down/10up) > 6 ft cat 5e phoneline to jack > 25 ft cat5e line > ~1/4 mile to ISP node(cable and DSL functionality)
cFos doesn't do anything I can't do in windows and the VyperVPN gave me frame drops. I do not have hardware limitations but rather some type of linux issue to adjust the code or look for other avenues to stop the stuttering/congestion. Now essentially it is a transmission issue which I feel like can be remedied through the OpenWRT firewall config. pls help
Main picture is a streamer with fiber/vdsl line im not sure but 32 ping
Picture in picture is mine about 64 ping