That looks good. I guess the only obvious improvement would be to specify the correct per-packet-overhead, which for fiber links unfortunately is somewhat hard to get right... (that and testing whether internal host isolation works*)
*) you do not actually need to run flent on multiple internal hosts; as long as you have one flent-capable host simply use the dslreports speedtest (configured for multiple streams on the windows hosts, make sure to extend the test duration to 30 seconds or more). Then expect the flent measured throughput to scale back to the (1/concurrently active hosts) fraction whenever the windows hosts have their speedtests running. BTW https://www.dslreports.com/forum/speedtestbinary gives command line clients for the dslreports speedtest, making testing a bit simpler.
This is the most important one as this sort of summarizes how you ended up configuring cake. Since it says "raw" instead of "overhead NN" I believe that you did not configure the per packet overhead explicitly and hence mentioned it.
The fact that there were drops tells me the shaper is doing its job...
AFAIK, this shows the peak delay cake induced, it looks quite nice.
This tells me only very few of your data flows use ECN, as otherwise there would be less drops and more marks.
And this shows that you do not suffer from large meta-packages (from GRO or GSO) as otherwise max_len would be larger, 1514 is typical for MTU 1500 packets as the linuk kernel skb structure will add the size of the ethetype and the two ethernet MAC addresses (the kernel fills these fields and hence 1514 is true from the kernel's perspective, even though it is not really suitable for any shaper).
Hi moeller0,
I tried running multiple dslr test in parallel and got unexpected results: no fair sharing and increased bufferbloat, so I'd like to try the dual-cake setup.
I think the right configuration is to set ingress or egress for both interfaces, because they face opposite direction (please correct me if I'm wrong), but I don't know which is better and how to apply dual_xxxsource options.
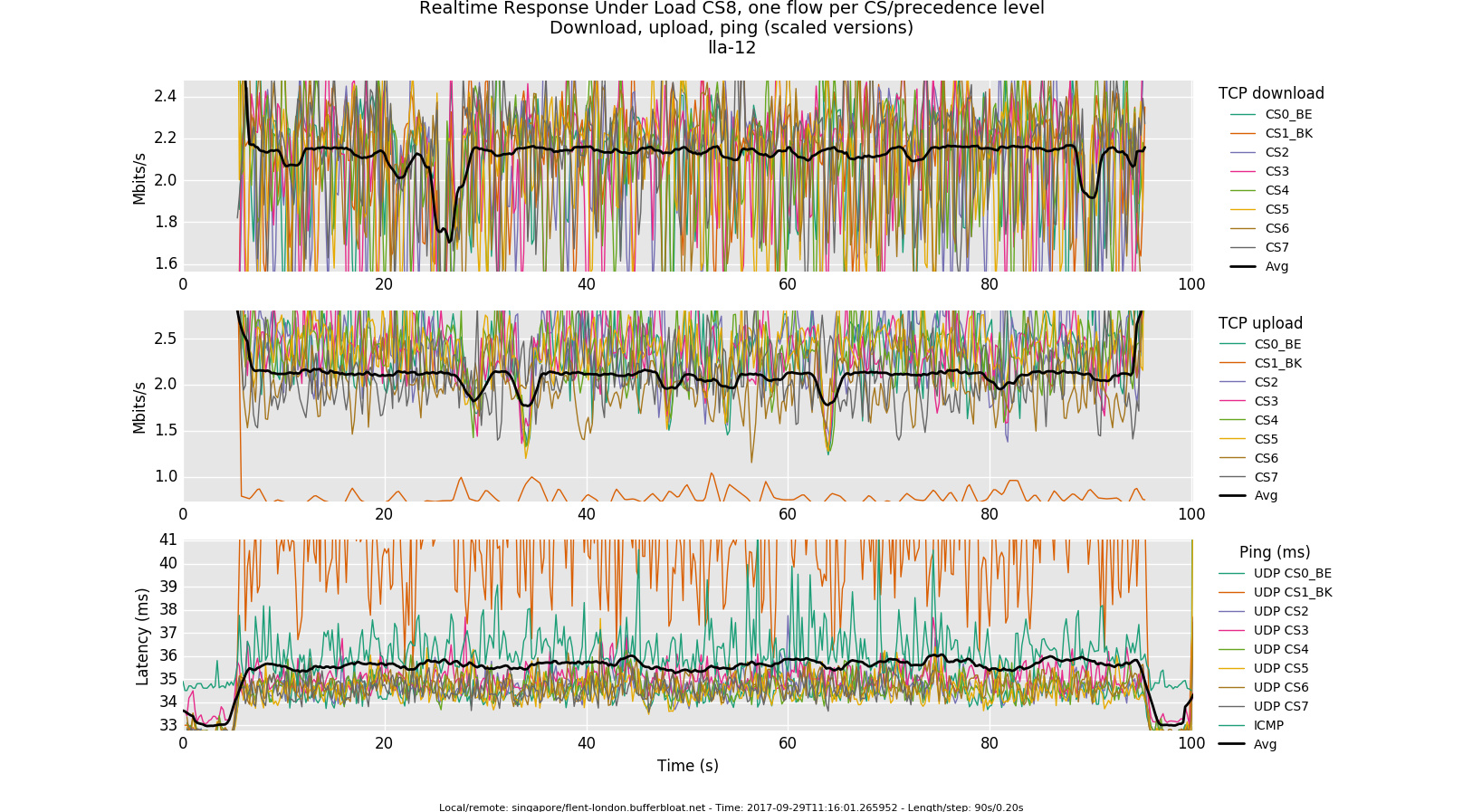
Since you use flent, could you post the RRUL_CS8 all plot here in the thread and annotate at what times the other windows host ran their speedtests, please?
Correct, but ingress requires an IFB which incurrs some processing cost, so on case of using two interfaces, always instantiate sqm-scripts on egress (by setting the ingress bandwidth to 0, which denotes "do not shape" as "shape to 0" would end up with a non-functional link...)
Just to confirm this; flent will automatically save a data file (even if you just requested a plot). So unless you actively deleted that file it should be somewhere on your linux machine, most likely in the directory from which you called flent.
The name would be (for a hypothetical rrul test performed at 2017-06-06):
Hi all,
some news from my tests about link layer adaptation: I found an optimal value of 12 bytes by trial and error, I applied it only to the WAN iface.
rrul_cs8
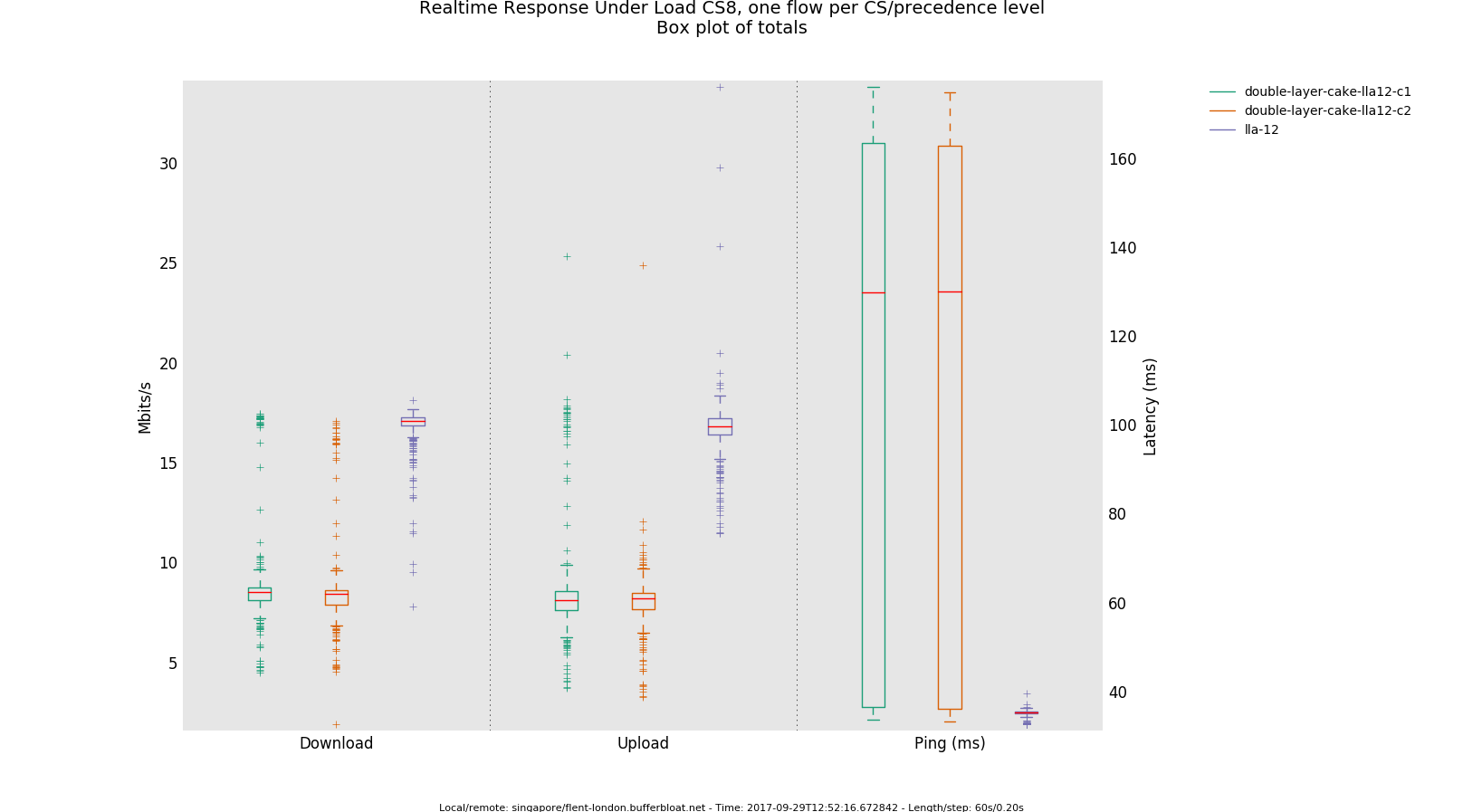
Now I'm trying to get fair sharing, but running 2 parallel flent test from different machines against the same server (flent-london.bufferbloat.net) gave me this results:
Interesting, could you post the output of "cat /etc/config/sqm", "tc -d qdisc" and "tc -s qdisc" again please?
Not sure, the bandwidth sharing looks roughly okay, but the latency skyrockets. I wonder, could you repeat that test again with both shapers set to 15000? Ingress shaping is a bit approximate and will generally need more playroom the more flows you have. The thing is qdisc shapers traditionally shape their output to the desired rate, but that most of the time there are more packets coming in that are dropped, but for ingress shaping that behaviour is not ideal. Cake's principal author believes he has a solution for that (by making cake attempt to shape its incoming rate) but that is still in testing.
As I expected, you are not using cake's overhead compensation, but tc's stab option. That is not bad in itself (it actually is quite fine), but stab does not account for the amount of overhead the kernel automatically adds for ethernet interfaces, namely 14 bytes (6 dst mac, 6 src mac, 2 ethertype). In essence this expands your specified overhead of 12 bytes into a more reasonsable 26 bytes. Why do I say 12 bytes is unreasonable? Because ethernet overhead alone takes more than that...
Hi moeller0,
I've noticed some strange behaviours during my tests, so I reverted to LinkLayerAdaptation=none to keep it simple. I also disabled ingress_ecn for LAN iface to reflect single cake setup' defaults.
Same settings for both test except queue setup script, but opposite ping results, could it be related to squash_dscp / sqash_ingress settings?
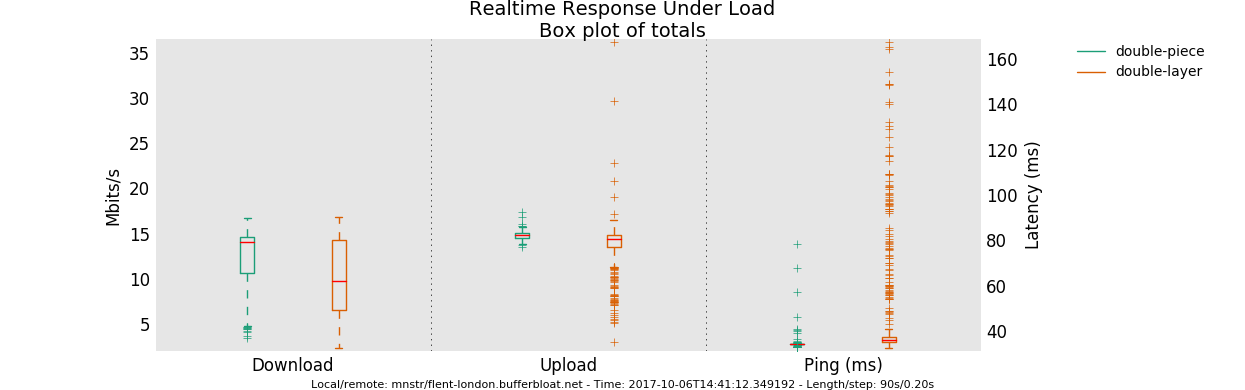
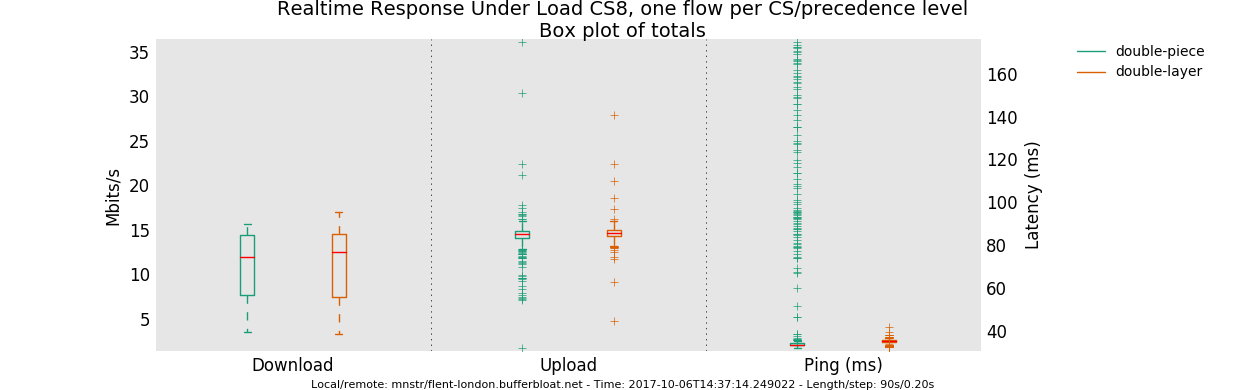
If I understand correctly your post here piece_of_cake and layer_cake should have different defaults, is it correct?
Quick question, I was just trying to understand your request, when the data ans the request disappeared. I hope you found a solution to your question. If so, would you mind sharing that, if you want per PM.
Hi moeller0,
given that I'm not a network admin and until a few weeksdays hours ago I didn't know anything about QoS, DSCP, ECN etc.. I'm trying to understand how different cake scripts and options affect traffic shaping.
I summarise what I think I've understood:
I can't take advantage of layer_cake because I use this transparent approach and the main router that eventually sets DS field is after the cake-box. I could only rely on applications setting DS bits at the source.
Layer_cake is also heavier and it introduces a bit of latency trying to shape into different queues, so the best approach in my scenario is piece_of_cake and squash/ignore DSCP on ingress, is it correct?
I also have a couple of questions about flent tests:
What's the difference between the rrul and rrul_cs8 test? which one is better suited during troubleshoot?
Do you have a good example of box_ping test using layer_cake? Just to know how it looks like.
But that is the charming idea about DSCP markings, ideally the end points of a connection set them and the intermediary networks either honor or ignore those. Unfortunately in reality what often happens is that intermediary networks actually re-map the DSCP fields to different values for their internal usage. But the idea is very much that the applications are the ones requesting a specific DSCP and it is up to the network to either honor or ignore this. Some applications actually set meaningful DSCPs already (I believe ssh does) so layer_cake might improve things even if only the egress packets have meaningful markings...
For ingress you would need to run a few packet captures to figure out whether you want to trust the incoming DSCPs or not, if you do set both squash_dscp and squash_ingress to 0. (The first instructs cake to remap the DSCPs to all zero, the default for the TOS field that is universally interpreted as best effort).
Not necessarily, yes layer_cake is more computationally expensive, but I have not quantified how much more expensive, and it might still do the right thing for you assuming your internal applications set the "correct" DSCPs. I guess you need to try it out?
rrul uses four flows per direction all with different DSCP markings. rrul_cs8 uses 8 flows per direction each using one of the the 8 dscp class selector (CS) markings. So rrul_cs8 will simply offer more flows and will also sample the priority band strategy of the whole end-to-end link a bit better. For fast links having 8 instead of 4 flows will make the measured total bandwidth come closer to the real limit (more interleaving of the different TCPs probing for the bandwidth limit).
I like the CS system as it a)only uses 3 of the 6 DSCP bits and b) I strongly believe that 8 different priority bands should be sufficient for most home users. (Heck many ISPs use the 3 priority bits in the VLAN tags so do just fine with just 8 priority bands and wifi/wmm uses just four different priority classes; so the full 6 bit of dscp markings seem quite overkill. I also would love if everybody would agree to split the 6 bits into two groups of three each, one group for the endpoints to code their intention, and one group for each intermediary network to use for real, that way at least the intention would be carried end-to-end; but this is just a dream).
Not at the moment, also I typically see more effects in local tests that when I go though the internet. I will see whether I can create one later. (Typically I see a stronger effect on the bandwidth, as the latency probes are still sparse and will be typically be boosted in comparison to the bulk TCP packets in each of the priority bands that cake uses, so the pings are often flat even though the bandwidth graphs show differences)...
Thank you moeller0, your answers are very useful for me to understand how things works!
Just to be sure:
ingress -> cake on wan iface
egress -> cake on lan iface
There isn't a squash_egress option, right?
For now this is beyond my skills
I've already tried, and in every test layer_cake showed higher avg (few ms) and peak (CS1_BK up to more than double) ping values. I didn't report all my result, because I'm not sure I'm testing correctly.
In fact I'm almost sure I always miss something!
I'm also having problem with the various DSCP marking standard, understanding how they overlap and/or work together.
while (!fully_understand) { try(); fail(); learn(); }
I had forgotten about your exact topology, but I meant packets that pass from your internal network to the internet. But now that you remind me, cake will naturally be attached to the egress side of an interface (for ingress shaping you need the ifb device), so in your case the shaper on the wan side effectively shapes egress, and the one on the LAN egress side handles packets coming from the internet. I hope this clears things up?
With a heavy emphasis on "now", you are making a lot of progress in understanding these things in a very short amount of time (it took me way longer).
Well, CS1_BK is the background "scavenger" class, so it is intended to only use up left-over bandwidth and yield quickly to more important packets, so higher RTT values for probes marked CS1 is to be expected and just shows things to be working as intended. I would be more interested in the relative RTTs of the other classes. Could you maybe post the "all" plots here, as they allow a decent first glimpse into the general sqm performance?
Wellcome to the club As far as I can tell eveybody nowadays hates strict precedence, but other than that there is not a really strict consensus what to use when. There are some heuristics based on some DSCP markings that actually are used in the wild (e.g. by VoIP applications and VoIP servers), but all in all it is a mess. IMHO not to the least because the DSCP bits are not guaranteed to be stable end-to-end, instead they are free for everybody to use and (re-)set when ever they please. That said, on the egress side you have full control (well potentially) over which applications use which markings (I believe in windows that can be set with a group policy, so might not need to be configured explicitly ion each machine, but zero actual erperience myself) and how the AQM interprets those... (Okay, by using cake you will need to make your applications use those DSCP markings that cake actually handles...)