First of all, this is ethical hacking, not trying to violate any copyright or should be considered disrespectful to @hackpascal, the recovery is great, but he chose to not disclose the source code, that's not really a problem until you realize the web interface is in Chinese and you can do nothing about it.
My only intention with this was to find out how to translate the interface of this great bootloader, not to steal any intellectual property!
The space is not really problem, the're only a few strings, would need 1-2KB more at most for english translation.
After a looooong day I fully translated it for an old MR-3220v1 (AR7241 SoC).
It has some checks but are easy to bypass.
The recovery is actually a two-stage loader, the first stage checks and unpacks the LZMA-compressed data to the RAM, then boots it, and that's the actual code running the recovery.
Previous steps:
- Get breed bootloader
- Install binwalk, lzmainfo from apt, and lzma sdk version
- Run binwalk on it, keep an eye for lzma compressed data, note down the decimal offset:
# binwalk breed-ar724x-reset11.bin
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
21640 0x5488 Copyright string: "Copyright (C) 2021 HackPascal <hackpascal@gmail.com>"
22056 0x5628 LZMA compressed data, properties: 0x6C, dictionary size: 33554432 bytes, uncompressed size: 308884 bytes
- Split the files:
Note down the packed data size! (87868 bytes)
# dd if=breed_bootloader of=boot bs=1 count=22056
22056 bytes (22 kB, 22 KiB) copied, 0.0505826 s, 436 kB/s
# dd if=breed_bootloader of=packed_data.lzma bs=1 skip=22056
87868 bytes (88 kB, 86 KiB) copied, 0.209102 s, 420 kB/s
- Check the current compresion settings, note down the dictionary size, lc, lp and pb:
# lzmainfo packed_data.lzma
packed_data
Uncompressed size: 0 MB (308884 bytes)
Dictionary size: 32 MB (2^25 bytes)
Literal context bits (lc): 0
Literal pos bits (lp): 2
Number of pos bits (pb): 2
- Unpack the data
# lzma -v -d packed_data.lzma -c >> unpacked_data
packed_data.lzma (1/1)
100 % 85.2 KiB / 301.6 KiB = 0.282
- Edit the data
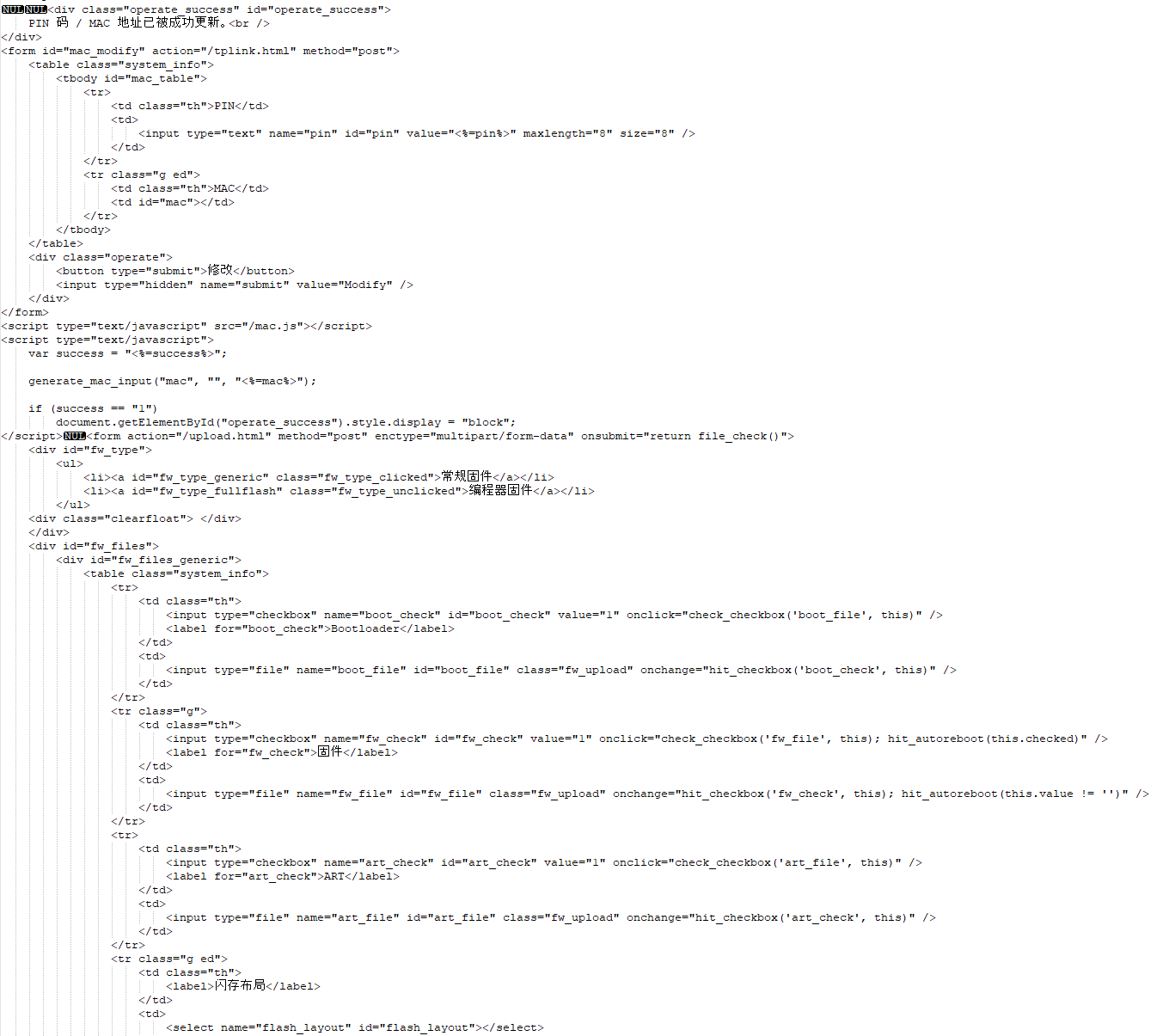
The data is now extracted, there're no checksums for the html, open the file unpacked_data with any editor.
You'll see the HTML code everywhere at about 3/4th of the file, can me modified pretty much as needed as long as the sections positions are kept.
Remember to set encoding as UTF-8 or the chinese chars will look like garbage data.
Each code section starts with a NULL char and '<'(<div>, <html>, etc ) , so if you search the hex 00 ·3C you'll find them quick.
You must ensure the NULL char stays in the same place, so after modifying each section adjust by adding/removing spaces.
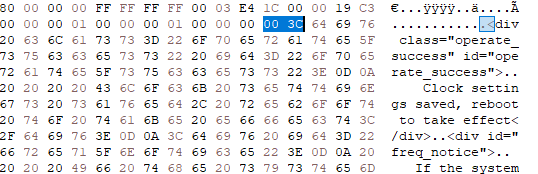
The easy way is to only modify one section at a time, save the file and compare the bytes, removing or adding the said spaces until it matches the original size.
Then there's a harder section with constants and strings, some parts of the web interface use it.<br
It's more tedious because they can't extended easily, you must modify them carefully to avoid causing havoc.
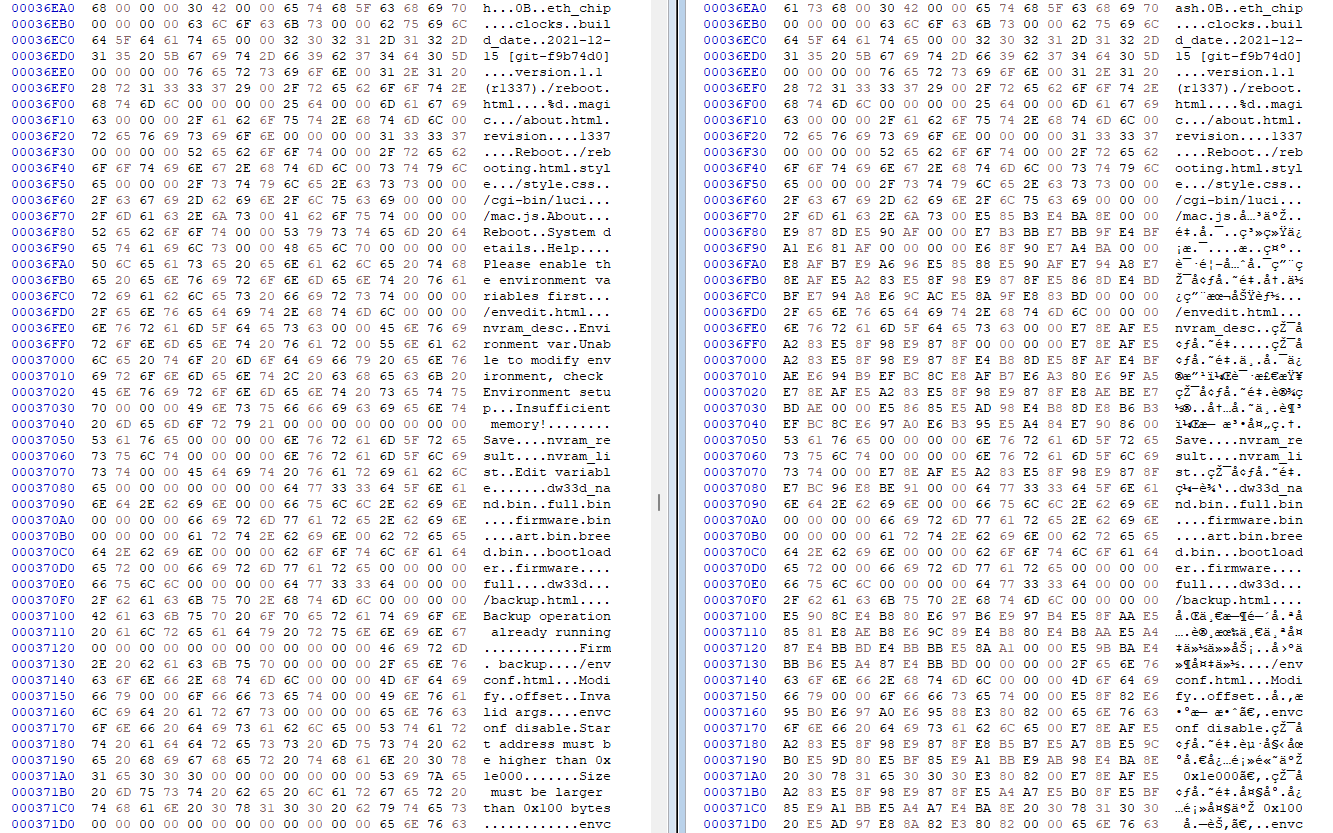
They're single strings separated by null chars, so you can slightly extend them if there's at least a null char between the next string.
Because the original text is Chinese, it uses UTF-8, it takes 2-3 bytes per character, so you have a lot of space when writing normal ASCII, most of the time you'll have so much space left that part of the old string remains, fill with null chars (00) until reaching the next existing null char in the string table.
HxD doesn't support UTF-8, so I opened the file in Notepad++ to find the sections easier, but modified in the hex editor:


- Repack the data.
Remember to use the SDK version, normal version lacks these switches.
Get the parameters you got from lzmainfo, we'll use them to repack the file.
The -d option is the number of bits (32MB = 2^25, so -d 25)
Note down the output size!
# lzma e unpacked_data packed_data_new -d25 -lc0 -lp2 -pb2
LZMA 22.01 (x86) : Igor Pavlov : Public domain : 2022-07-15
Input size: 308884 (0 MiB)
Output size: 87207 (0 MiB)
- Build the image
# cat boot packed_data_new > breed_mod.bin
- Final step
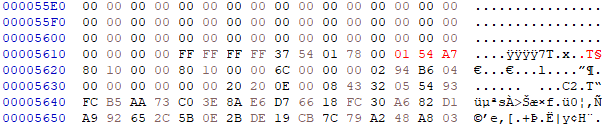
Convert the original data size (87868) to hex (1573C).
Convert the new lzma output size (87207) to hex (154A7).
Open breed_mod.bin with a hex editor, go to the data offset (0x5628), few bytes upper (12 ?) you'll find the original data size.
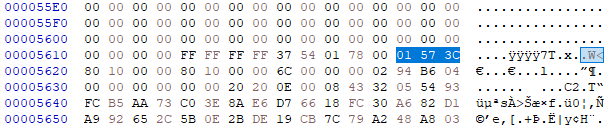
Modify these bytes to match the new data and save the file.
Wrong data size will cause the bootloader to complain with "Bootloader data is corrupted!" error.
Upload the image and done!
This is not translated by google!
Now the details are known, it shouldn't be hard for the community to modify the bootloaders, perhabs making a github project with them.
Edit:
Pages are almost identical, I translated Breed for AR9331 in 2 hours.
It's definitely much easier to edit with Notepad++, but be careful!
- Open the file, select UTF-8 encoding, don't select UTF-8 conversion!
- Don't save the file while in UTF-8 mode, it'll mess everything up, return to ANSI encoding first.
- If you already messed up, don't worry, change the encoding to ANSI and save again.
- Avoid modifying chars nearby non-printable chars (Those appearing in BLACK with NUL and other symbols)
- I repeat, only modify a section at a time, those between 00 3C (NULL and '<'), save the file, then pad with spaces until matching the original file size, repeat for each section, otherwise you'll missalign the sections and break it.
- Finally open original and modded unpacked files and ensure those 00 3C between HTML code are in the same place, re-adjust if necesary by adding/removing spaces.
Attached the files for AR7241 and AR9331 here
(Spam / bot protection: Copy the URL and remove the extra 'E' from 'drivee').
BTW I compiled Openwrt 22.03 for MR3220v1 (AR7241) and WR740Nv4 (AR9331), both modded to 64/16M, they're doing really well for their age! ![]()