Hi,
Just wanted to get a recommendation on this setting. I'm using layer cake on an x86 box connected after a ISP provided Arris router on a DSL connection. Would "Ethernet with Overhead" and per packet overhead of 26 or 34 suffice? ISP is through AT&T and the only thing I can tell about my connection is modulation is VDSL2.
Given that little information it is hard to make precise statements.
But unless At&T went out of their way and used ATM over VDSL2, let's assume PTM being used.
So plain VDSL2/PTM will cause an overhead of 22 bytes: ETHERNET: 6B dest MAC + 6B src MAC + 2B ethertype + 4B Frame Check Sequence + PTM: 1B Start of Frame (S) + 1B End of Frame (Ck) + 2B TC-CRC (PTM-FCS)
Now if your ISP also uses a VLAN tag, add 4 bytes and if PPPoE is used add another 8 byte.
Now, specifying more overhead that truly exists, will cost you a tiny sliver of maximally achievable speed, while underestimating the true overhead can cause bufferbloat to flare up unexpectedly, I always recommend to err on the side of too large an overhead, so I would just go for 22+4+8 = 34 Bytes, which should cover your uncertainties well. And yes "Ethernet with overhead" is the correct setting.
When setting the shaper gross speed, please keep in mind that VDSL2/PTM uses a 64/65 encoding, so if you take the modem's sync rates as reference you need to reduce them by at least 100-100*64/65 = 1.538 -> 1.6%-age points otherwise your shaper is not going to fix bufferbloat.
BUT most ISPs do not seem to relay on using the DSL link's sync as method of choice to restrict users to their contracted rates and hence in all likelyhood you will need to run a few seedtests first to figure out the achievable goodput to make an educated guess for the shaper gross rates.
Rule of thumb: run a few speedtests, take a robust estimate of the achievable rates (throw out the outliers) and use this net-rate as your shaper's gross rate.
If you are unhappy with the rate sacrifice you can iteratively increase the shaper rate in steps while measuring bufferbloat, just stop at those shaper rates that give you an latency under load increase you are willing to accept/tolerate.
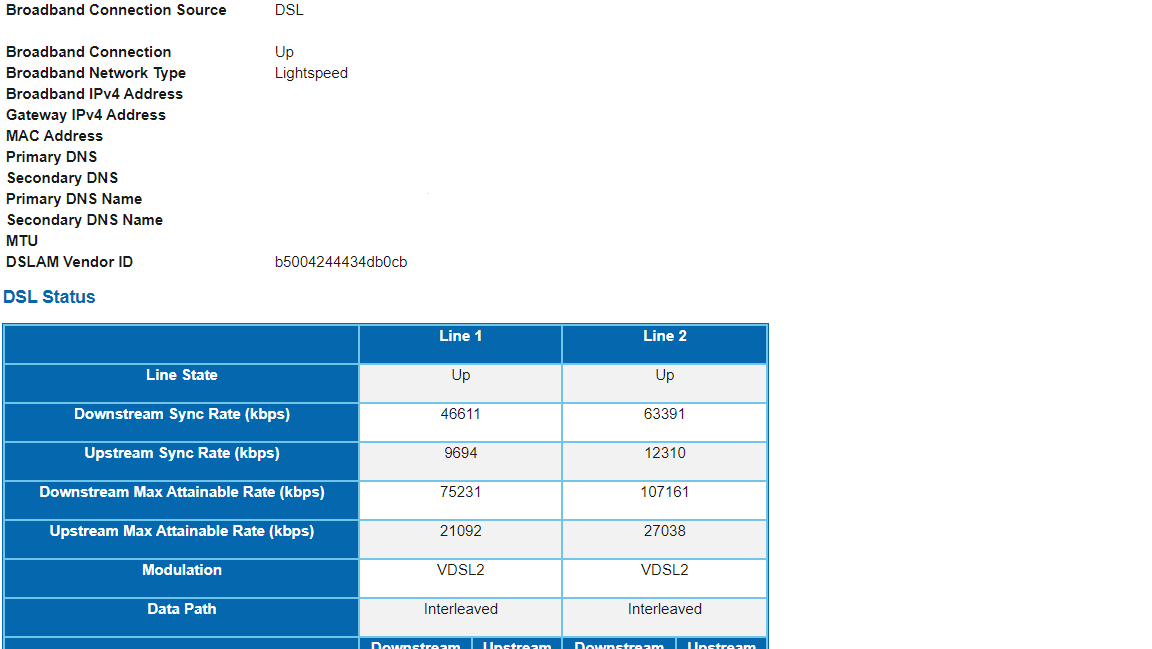
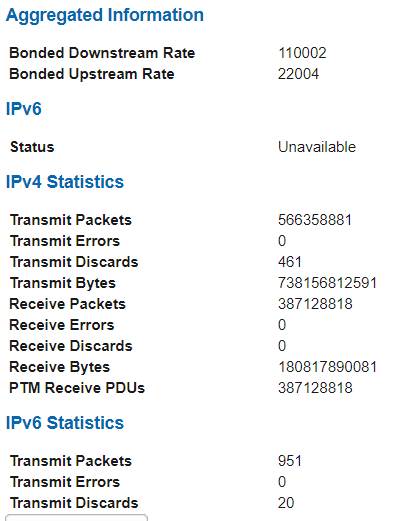
thanks @moeller0 for the feedback. After browsing through the Arris router settings, the only connection type info I could find that might have any meaning is the following:
Ah, so this is a bonded link (basically two VDSL lines in parallel), not sure if there is additional overhead from the bonding.
It seems you are bold enough ;). The 64/65 factor comes from the fact that in PTM every 65th byte does not carry user data, but data important for the PTM state/synchromization, the sync rate as reported does count all bytes, so you need to account for that non-data carrying byte, hence the observation that on VDSL2/PTM one needs at least to subtract ~1.6% from the sync rates to be able to successfully fight bufferbloat. But often enough that 1.6%-age point reduction from the sync rates is not enough, be it because downstream shaping is less precise and hence needs a larger bandwidth sacrifice, or because the ISP might have a different traffic shaper upstream of the DSLAM that has over-sized and under-managed queues.
The 80-95% of gross speed reduction recommendation is just a simple heuristic that often gives a decent starting point. That said nowadays, especially with cake's ingress keyword my recommendation is rather to run a few speedtests and pluck the resulting net/goodput number as gross rates into the shaper.
Note that on old ATM links, with its borderline absurd 48/53 encoding 100-100*48/53 = 9.4%-age points are used purely for the encoding, add 5% more for good measure and you see why it was considered a decent starting point in the old ADSL/ATM days...
Well, I probably "Ethernet with overhead" and something like 44 bytes of overhead and tcMPU of 64, as I said before, bufferbloat wise accounting for too much overhead is benign, under-accounting however is to be avoided, so unless more information is available, I would just select 44 and forget about the whole issue
Sounds good to me. Just one last question before I close this thread, can you explain the tcMPU field? Is it another overhead compensation? I've seen you mention it in other topics and how it could potentially become a default in cake in the future. thanks again
Different transmission technologies have different minimum sizes for packets. In ATM the smallest size is a 53 byte cell containing 48 bytes of user data, in Ethernet things are slightly more complex, there is at least 64 bytes between destination MAC and FrameCheckSequence (FCS) and all technologies that use ethernet frames including the FCS, like VDSL2/PTM, GPON, DOCSIS, ... inherit that minimum packet unit () MPUof 64 bytes (adding a VLAN tag increases that size to 64bytes IIRC). I said things in Ethernet are complicated, because in addition to the layer2 ethernet-frame on real ethernet carriers there are additional 20 bytes of overhead leading to an on the wire MPU of 64+20 = 84 (or 88 with VLAN)...
The tcMPU field in /etc/config/sqm is currently respected/evaluated for both the cake and tc-stab link layer adaptation mechanism ("default" will pick either tc-stab or cake), this was different in older versions of sqm scripts, but is easily confirmed by tc -s qdisc where cake will report the configured mpu size (for HTB/fq_codel based qos scripts, I think you need 'tc -d qdisc' but I am not 100% certain).
See above, it is another facet of overhead that should be accounted for, otherwise sqm will underestimate the true relevant size equivalent of small packets which can lead to it failing to control bufferbloat.
I believe that future is already here, at least for OpenWrt 19.7.3...