Recent cake in master and maybe 18.6.2? will automatically figure out the overhead the kernel adds automatically and subtract that before the sqm overhead is added. In other words no need to worry about this anymore. Use tc -s qdisc to get a detailed report from the running cake instances that will also inform about the potentially kernel-added 14 bytes of overhead. But make sure not to use tc-stab or htb-private as link layer adjustment methods.
In that case is the information here incomplete or old? https://www.bufferbloat.net/projects/codel/wiki/Cake/#extensive-framing-compensation-for-dsl-atm-pppoe
Assuming the figures in the brackets are the overhead in each case.
Well, basically the via-ethernet does not do -14 anymore, but cake will look at each packet to account for any potentially kernel added overhead.
Yeah, I just wondered if those figures in there can be used as the 'overhead' figures for SQM configuration via the luci interface.
Well if you know the exact encapsulation, you can use those values as a look-up table of sorts, but the challenge is to figure out the encapsulation more than the exact values for each component.
Though presumably in this case (VDSL) the answer is simplified because of the following:
Two more new keywords deal with the basic VDSL2 configurations. Again, the overheads use IP as a baseline, but this time ATM cell-framing is turned off.
pppoe-ptm (27)
bridged-ptm (19)
So those who put down pppoe as the protocol should put in 27, and in this case (TalkTalk) and with a protocol of 'dhcp' what is being used is 'bridged ptm' ?
Alas it is not that simple. For one, you are right in that the values on the website seem out of date, here is the current man tc-cake output relevant to VDSL2:
VDSL2 Overhead Keywords
ATM was dropped from VDSL2 in favour of PTM, which is a much more
straightforward framing scheme. Some ISPs retained PPPoE for compati-
bility with their existing back-end systems.
pppoe-ptm
Equivalent to overhead 30 ptm
PPPoE: 2B PPP + 6B PPPoE +
ETHERNET: 6B dest MAC + 6B src MAC + 2B ethertype + 4B Frame Check
Sequence +
PTM: 1B Start of Frame (S) + 1B End of Frame (Ck) + 2B TC-CRC
(PTM-FCS)
bridged-ptm
Equivalent to overhead 22 ptm
ETHERNET: 6B dest MAC + 6B src MAC + 2B ethertype + 4B Frame Check
Sequence +
PTM: 1B Start of Frame (S) + 1B End of Frame (Ck) + 2B TC-CRC
(PTM-FCS)
See also the Ethernet Correction Factors section below.
But even with that corrected thee still is the VLAN issue, if your ISP uses a VLAN you will need 34 and 26 instead of the 30 and 22 above. Also if you instantiate the shaper for a PPPoE link on pppoe-wan the numbers are fine, but if you use the underlaying ehernet interface like eth0, you need to subtract 8, IIRC.
1 Like
Apologies for reviving this thread but a thought occurs to me. In the scenario of connecting with a VLAN it's common to get a device corresponding to the vlan and one to the VDSL connection itself (so dsl0 and dsl0.101 in this case), presumably the same reasoning applies; i.e if I apply shaping to dsl0.101 I don't include the VLAN overhead, whereas if I apply it to dsl0 then I do?
Mmh, I believe these to be slightly different. PPPoE header live inside the ethernet payload and will be accounted as payload for the packetsize if looking at the physical interface, while on the pppoe interfacde itself that overhead has not yet been added to the packets and hence is invisible. VLANs will live outside the payload and j=hence never be automatically accounted by cake. But you can test this, instantiate cake in sequence first on dsl0, then on dsl0.101 run a speedtest and then look at the output of tc -s qdisc, where cake will tell you about the payload sized it detected/accounted for.
But the idea in general is a good one.
Where am I likely to see this? Is it some function of network layer size and overhead-adjusted size?
tc -s qdisc:
[...]
qdisc cake 80bd: dev pppoe-wan root refcnt 2 bandwidth 36Mbit diffserv3 dual-srchost nat nowash no-ack-filter split-gso rtt 100.0ms noatm overhead 34 mpu 68
Sent 357978234 bytes 2413002 pkt (dropped 107, overlimits 175721 requeues 0)
backlog 0b 0p requeues 0
memory used: 111872b of 4Mb
capacity estimate: 36Mbit
min/max network layer size: 28 / 1492
min/max overhead-adjusted size: 68 / 1526
average network hdr offset: 0
[...]
The payload size is reported as "network layer size", in my case that is a pppoe interface on top of eth1.7, so as you can see the 4 byte VLAN tag is not visible in the payload. It does show in the "overhead-adjusted size", but only because I specifically requested 34 bytes of overhead.
Hi, I'm on a VDSL2 line (PTM) on Deutsche Telekom and try to determine the real overhead for Qosify.
I've made a Wireshark trace on ptm0 interface. In the trace I can see the following
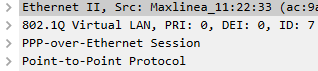
So in my opinion its 14 + 4 bytes (Ethernet Frame + VLAN Tag) + 8 bytes PPPoE: Makes a total overhead of 26 bytes. Why I can't see the 4 bytes frame check?
And I'm also missing the PTM overhead, which should be 4 bytes. Is there a way to trace the PTM overhead?
Another thing I don't understand is why I need to add the PTM overhead to tc-cake? As the pppoe-wan interface is the decisive one in the Qosify config and all the PTM overhead is removed by the kernel driver before, shouldn't the overhead be matching the pppoe-wan interface? (In my case 26 bytes)
Maybe you could give me some clarification where I'm wrong.
Thank you very much!
Because your NIC/driver already removed that, frames with a non-matching FCS are treated as errors and are IMHO not propagated deep into the kernel. But the FCS field is present on the actual links and hence will eat into a link's capacity and hence needs to be accounted for (for a bottleneck on a true ethernet link you also need to account for preamble, SFD and inter frame gap, in spite of the IFG not consisting out of data octets, it really is a pause in transmission)
The PTM overhead only exists on the actual PTM link, which only exists between the modem and the DSLAM. And IIRC the PTM layer is handled internally to the DSL chip/driver and not exposed to the kernel.
Because your VDSL-link has a limited capacity and if you want to avoid overcommitting data so that it queues inside the modem/dsl-driver you need to make sure you never commit more data than the link can actually transfer in the expected amount of time, and that means that all overhead that exists on that link needs to be accounted for.
You are free to set any per packet overhead you want, but conceptually, if you want to keep the latency under load increase (aka bufferbloat) bounded, you need to make sure that you account each packe t with at least the "virtual" size the packet will carry across the bottleneck link (keeping in mind that depending on the packetsize distribution the position of the bottleneck might actually jump around).
In your case you have two potential bottlenecks you need to deal with:
a) the ISPs traffic shaper at the BNG
b) the limited capacity of the actual DSL link
depending on the details one or the other might be more relevant for the relevant per packet overhead.
Say if you have a 50/10 plan but your link syncs with 116/40 a) will be your problem, while b) will likely be irrelevant, but if your 50/10 plan syncs at around ~50/10 then b) will be relevant under some assumptions.
If you have any more questions, just ask.
Hi @moeller0,
thank you very much for the quick response and the good explanation!
Because your NIC/drover already removed that, frames with a non-matching FCS are treated as errors and are IMHO not propagated deep into the kernel. But the FCS field is present on the actual links and hence will eat into a link's capacity and hence needs to be accounted for (for a bottleneck on a true ethernet link you also need to account for preamble, SFD and inter frame gap, in spite of the IFG not consisting out of data octets, it really is a pause in transmission)
Oh ok, I've always calculated the Ethernet frames with 14 or 18 bytes (802.1q tagged). But how to calculate the overhead in VDSL2 with VLAN tag then?
(4 bytes PTM) + (8 bytes PPPoE) + (14 bytes + 4 bytes VLAN + 8 bytes Preamble and SFD + 4 Bytes CRC for Ethernet) which gives a total overhead of 42 bytes - is that correct?
In your case you have two potential bottlenecks you need to deal with:
a) the ISPs traffic shaper at the BNG
b) the limited capacity of the actual DSL link
depending on the details one or the other might be more relevant for the relevant per packet overhead.
Say if you have a 50/10 plan but your link syncs with 116/40 a) will be your problem, while b) will likely be irrelevant, but if your 50/10 plan syncs at around ~50/10 then b) will be relevant under some assumptions.
Ahhh ok. So what does that mean in practice? If the modem is synced with 116/40 and the BNG does the traffic shaping, I haven't to worry about the PTM and PPPoE overhead?
If you have any more questions, just ask.
Oh yes, QoS is a completely new area for me. I'm trying to build the knowledge from the lowest layer up to the top ![]()
This really depends what layer you are interested in, but say you want to make sure to properly account for what happens on a VDSL2 link in relation to the reported sync (let's assume a sync/ gross rate of 100 without units, which can be easily interpreted as percent), here is the number you could measure a maximum goodput in a speedtest of:
100 * 64/65 * ((1500-8-20-20)/(1500+26)) = 93.68%
Let's tackle the terms one by one:
100:
that is simply the sync gross rate in arbitrary units
64/65:
This accounts for the fact that VDSL2/PTM uses every 65th octet/byte for its own purposes and not for the "payload" frames
(1500-8-20-20):
This is size of the IP payload, we start the ethernet payload size (1500 bytes is the maximum size over the internet, often smaller) and then subtract:
8: for PPPoE (2 Byte PPP + 6 Byte PPPoE)
20: for the IP header, here IPv4, as IPv6 will require 40 bytes instead of 20
20: the TCP header (without options)
-> 1500-8-20-20 = 1452 bytes
(1500+26):
This is the on-the-wire-size of a data packet on the PTM link for the Deutsche Telekom situation. The 26 bytes consist out of:
VLAN (IEEE 802.1Q): 4 Byte VLAN
VDSL2 (IEEE 802.3-2012 61.3 relevant fuer VDSL2): 1 Byte Start of Frame (S), 1 Byte End of Frame (Ck), 2 Byte TC-CRC (PTM-FCS), = 4 Byte
COMMON (VDSL2/Ethernet): 6 (dest MAC) + 6 (src MAC) + 2 (ethertype) + 4 Byte Frame Check Sequence (FCS) = 18 Byte
-> 4+4+18 = 26
--> 26+1500 = 1526 bytes
Now how much per-packet-overhead you need to set in sqm depends a bit of how much of the overhead is visible to the kernel... For example on a pppoe-wan interface, the packets will not yet carry a VLAN tag nor the PPPoE header, so you need to instruct sqm to calculate that in, resulting in 26+8 = 34 bytes of overhead.
It depends... but probably not. The problem here is which has a higher per packet overhead, the BNG shaper or the PTM link, the safe option is to simply account for the maximum of the per packet overhead of either the BNG or the PTM link. The challenge is that we do not know how the BNG shaper is configured (and Telekom has not been forthcoming with that information, treating it as a secret which is daft as everybody can easily measure the consequence of that setting, but I digress).
Ah, I would not really consider traffic shaping a part of QoS, but I guess different people use different definitions.
Ok, this makes sense! Thank you very much! I understand the calculation of the overhead now.
But what about the PPPoE Header? Isn't the on-wire-size 1526 + 8 bytes PPPoE? ![]()
Ok, so detecting the real overhead is the common solution for both. That's why I'd like to understand the things behing ![]()
The PPPoE header sits inside the ethernet frame hence the 1500 - 8 - 20 - 20 to calculate the TCP payload size of a typical packet, See the German wikepedia article for PPP_over_Ethernet for an image illustrating that:
https://de.wikipedia.org/wiki/Datei:PPPoe.svg
Or have a look at your wireshark screenshot above, showing the stacking order:
ethernet II
VLAN
PPPoE
PPP
{kind=link}
and below that you would find the IP header and whatever else is in the packet.
Yes, except that is somewhat hard. For old-school ATM/AAL5 Jesper Dangaard Brouer and Russell Stuart figured out the details and method how to empirically deduce the actual per-packet-overhead (see here for an implementation), but that relies on the cell quantization that AAL5 requires. For all other link technologies measuring it empirically is harder. The sqm details wiki page for OpenWrt has a section at least showing how one could go and try to figure out whether a given combination of shaper gross speed and per-packet-overhead appears sane.
Same here, I wish I would understand them better.
The consequences of overestimating the overhead is a slight loss in throughput mainly with smaller packets. It's often best to just pick a big enough value and run with it. 45 bytes for example.
1 Like
Decent advice, if it is certain that 45 is >= the true per packet overhead. (This should often be true, but will not be so unconditionally, think GRE or VPN tunnels).
To add a less contrived example I encountered in real live, VDSL2 116/40 over a 100Mbps fast ethernet link (overhead calculated on top of IP payloads):
effektive Overhead: VDSL2 VLAN7, Ethernet, PPPoE:
4 + 4 + 18 + 8 = 34
effective Overhead: 100Mbps ethernet: Preamble, SFD, IFG, VLAN7, ethernet, PPPoE
20 + 4 + 18 + 8 = 50
Because the fast ethernet link was the true bottleneck, these 50 bytes where the appropriate overhead to account on the pppoe-wan interface. If in the same situation the link between router and modem was replaced by a 1Gbps ethernet link things would change. This would show most prominently with small packets so, let's illustrate that with some numbers:
VDSL2:
goodput: 116 * 64/65 * ((64-8)/(64-8+34)) = 71.07 Mbps
and
packet-rate: 116 * 64/65 / ((64-8+34)*8/1000^2) = 158632.48 pps
required gross rate on ethernet for these packets
gross rate: (116 * 64/65 / ((64-8+34)*8/1000^2)) * ((64-8+50)*8/1000^2) = 134.52 Mbps
which clearly is above what 100 Mbps FastEthernet can deliver (100 Mbps gross rate), but not a problem for gigabit ethernet with its 1000Mbps gross rate.
This IMHO indicates that while "erring on the side of too large" is correct and good advice, but it can be surprisingly hard to figure out what "too large" means without diving into details. Alas, for this case with ethernet and VDSL2/PTM the relevant numbers are public, but for link technologies like GPON things get considerably murkier.
Oh yeah.. sure.. thats why it's called PPP over Ethernet ![]()
![]()
Oh yeah, I've looked at your github repo a couple of hours ago hoping to determine the overhead on my VDSL2 line but then I saw the note in the README ("NOTE: The estimated overhead will only be correct for ATM links, so if you are certain your link does not use ATM/AAL5, don't bother to use use ATM_overhead_detector, it will not give you reliable information about your link's per-paket-overhead..." ![]()
I'm having an issue with live tv. When I stream HD streams and downloading a file parallel, the stream stucks. I tried to using Qosify now on a FB7360 (xrx200) but without success. Whenever I activate SQM or Qosify the speed stucks at about 50 Mbit/s and the shaping doesn't work. I guess the CPU is to weak. ![]()
Thanks again for spending your time!