Is it possible somehow to set up with SQM (or whatever) so that the bandwidth is evenly divided? For example, the first user starts downloading, almost the entire bandwidth is given to him, but then the second user connects and the bandwidth is divided between them 50% / 50%, and then the third one connects, and also starts downloading, and the bandwidth is already divided between them 100%/3=~33% for each, then 4, and the bar splits 100%/4=25% for each.
I'm talking about downloading users. It is clear that there is no need to divide the bandwidth between those who have minimal traffic consumption.
Because I don't like how SQM works now. I have an x86 router (22.03), I set it to ~85% of my bandwidth, and if one user starts downloading, then others start having problems browsing the web, for example. And if I turn off SQM, then the downloading user gets much more speed, and other users experience less speed problems. I also noticed that for sqm download / upload is the same, and if, for example, I have 175000 (175 megabits) for downloading and uploading in sqm, then the downloading user gets 130 megabits for downloading, and 45 megabits for uploading. I do not understand why this is done if I have full duplex Internet, and I can download and upload at a speed of 200 megabits (isp max speed for me, stable connection and speed).
I would really appreciate if someone could help me solve these problems!
Even though you are on x86, it sounds like you are out of cpu. What's your network card?
This documentation page should get you close to what you want.
The TL;DR version is to use the "nat dual-dsthost" options for your ingress and "nat dual-srchost" options for your egress to enable per-host isolation.
1 Like
i225 2,5 gb from intel
CPU j4125
4gb ddr4
nvme
its mini pc
Of course I have already read this page.
CAKE also has a means of fair sharing bandwidth amongst hosts. A simple example/question: If I have two hosts one which starts 2 data streams and the other starts 8, then one host would get 80% of the bandwidth allocated to it and the other 20%. From a fairness point of view it would be better if the available bandwidth was split evenly across the active hosts irrespective of the number of flows each host starts, such that one host cannot obtain all of the bandwidth just because it starts all of the transfers.
But I don't see how to do it? Please help.
Post the output of:
ifstatus wancat /etc/config/sqmtc -s qdisc
Then we can take it from there.
This does not sound right for normal SQM operation, unless the user that download uses a very large number of concurrent flows. This might indicate that something else is going wrong.
Post this while downloading or just when network without load?
Does not matter initially, the first two do not differ between loaded and idle, for the tc -s qdisc output just note whether this is from an idle network or from a loaded one.
Actually, since you asked, it would be great the get the tc -s qdisc both from the idle condition and from the problematic load condition; but we might be getting ahead of ourselves.
BTW im using wireguard vpn to protect almost all traffic and vpn policy routing to make server go without vpn
ifstatus wan
{
"up": true,
"pending": false,
"available": true,
"autostart": true,
"dynamic": false,
"uptime": 52959,
"l3_device": "eth0",
"proto": "dhcp",
"device": "eth0",
"metric": 0,
"dns_metric": 0,
"delegation": true,
"ipv4-address": [
{
"address": "my static ip from isp",
"mask": 25
}
],
"ipv6-address": [
],
"ipv6-prefix": [
],
"ipv6-prefix-assignment": [
],
"route": [
{
"target": "0.0.0.0",
"mask": 0,
"nexthop": "nexthop address",
"source": "my static ip address/32"
}
],
"dns-server": [
"dhcp servers from my isp",
"dhcp servers from my isp"
],
"dns-search": [
],
"neighbors": [
],
"inactive": {
"ipv4-address": [
],
"ipv6-address": [
],
"route": [
],
"dns-server": [
],
"dns-search": [
],
"neighbors": [
]
},
"data": {
"dhcpserver": "dhcp server from my isp",
"leasetime": 600,
"ntpserver": "there was ntp server from my ISP"
}
}
cat /etc/config/sqm
config queue 'eth1'
option qdisc 'cake'
option script 'piece_of_cake.qos'
option linklayer 'none'
option enabled '1'
option interface 'eth0'
option debug_logging '0'
option verbosity '5'
option download '185000'
option upload '185000'
tc -s qdisc
qdisc noqueue 0: dev lo root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc cake 8009: dev eth0 root refcnt 5 bandwidth 185Mbit besteffort triple-isolate nonat nowash no-ack-filter split-gso rtt 100ms raw overhead 0
Sent 1041541210 bytes 5862196 pkt (dropped 1, overlimits 151605 requeues 7387)
backlog 0b 0p requeues 7387
memory used: 393240b of 9250000b
capacity estimate: 185Mbit
min/max network layer size: 42 / 1514
min/max overhead-adjusted size: 42 / 1514
average network hdr offset: 14
Tin 0
thresh 185Mbit
target 5ms
interval 100ms
pk_delay 24us
av_delay 4us
sp_delay 1us
backlog 0b
pkts 5862197
bytes 1041542504
way_inds 97328
way_miss 74614
way_cols 0
drops 1
marks 1
ack_drop 0
sp_flows 3
bk_flows 1
un_flows 0
max_len 7764
quantum 1514
qdisc ingress ffff: dev eth0 parent ffff:fff1 ----------------
Sent 11164217282 bytes 9214510 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc mq 0: dev eth1 root
Sent 3248470761 bytes 3681055 pkt (dropped 0, overlimits 0 requeues 933)
backlog 0b 0p requeues 933
qdisc fq_codel 0: dev eth1 parent :4 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
Sent 676361982 bytes 794797 pkt (dropped 0, overlimits 0 requeues 206)
backlog 0b 0p requeues 206
maxpacket 3028 drop_overlimit 0 new_flow_count 390 ecn_mark 0
new_flows_len 0 old_flows_len 0
qdisc fq_codel 0: dev eth1 parent :3 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
Sent 660465741 bytes 840562 pkt (dropped 0, overlimits 0 requeues 180)
backlog 0b 0p requeues 180
maxpacket 4542 drop_overlimit 0 new_flow_count 493 ecn_mark 0
new_flows_len 0 old_flows_len 0
qdisc fq_codel 0: dev eth1 parent :2 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
Sent 1160664354 bytes 1162056 pkt (dropped 0, overlimits 0 requeues 216)
backlog 0b 0p requeues 216
maxpacket 3028 drop_overlimit 0 new_flow_count 854 ecn_mark 0
new_flows_len 0 old_flows_len 0
qdisc fq_codel 0: dev eth1 parent :1 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
Sent 750978684 bytes 883640 pkt (dropped 0, overlimits 0 requeues 331)
backlog 0b 0p requeues 331
maxpacket 3028 drop_overlimit 0 new_flow_count 483 ecn_mark 0
new_flows_len 0 old_flows_len 0
qdisc mq 0: dev eth2 root
Sent 1593415277 bytes 7520992 pkt (dropped 0, overlimits 0 requeues 1075)
backlog 0b 0p requeues 1075
qdisc fq_codel 0: dev eth2 parent :4 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
Sent 471763732 bytes 692453 pkt (dropped 0, overlimits 0 requeues 141)
backlog 0b 0p requeues 141
maxpacket 4542 drop_overlimit 0 new_flow_count 1440 ecn_mark 0
new_flows_len 0 old_flows_len 0
qdisc fq_codel 0: dev eth2 parent :3 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
Sent 360481659 bytes 3637417 pkt (dropped 0, overlimits 0 requeues 51)
backlog 0b 0p requeues 51
maxpacket 3028 drop_overlimit 0 new_flow_count 708 ecn_mark 0
new_flows_len 0 old_flows_len 0
qdisc fq_codel 0: dev eth2 parent :2 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
Sent 535481076 bytes 2604236 pkt (dropped 0, overlimits 0 requeues 646)
backlog 0b 0p requeues 646
maxpacket 6056 drop_overlimit 0 new_flow_count 1871 ecn_mark 0
new_flows_len 0 old_flows_len 0
qdisc fq_codel 0: dev eth2 parent :1 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
Sent 225688810 bytes 586886 pkt (dropped 0, overlimits 0 requeues 237)
backlog 0b 0p requeues 237
maxpacket 3028 drop_overlimit 0 new_flow_count 3373 ecn_mark 0
new_flows_len 0 old_flows_len 0
qdisc mq 0: dev eth3 root
Sent 29208163009 bytes 23385195 pkt (dropped 861, overlimits 0 requeues 9627)
backlog 0b 0p requeues 9627
qdisc fq_codel 0: dev eth3 parent :4 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
Sent 6439547092 bytes 5407556 pkt (dropped 69, overlimits 0 requeues 3417)
backlog 0b 0p requeues 3417
maxpacket 25738 drop_overlimit 0 new_flow_count 2503 ecn_mark 0
new_flows_len 0 old_flows_len 0
qdisc fq_codel 0: dev eth3 parent :3 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
Sent 17614653899 bytes 12709616 pkt (dropped 335, overlimits 0 requeues 4031)
backlog 0b 0p requeues 4031
maxpacket 25738 drop_overlimit 0 new_flow_count 4047 ecn_mark 0
new_flows_len 0 old_flows_len 0
qdisc fq_codel 0: dev eth3 parent :2 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
Sent 4664471987 bytes 4258104 pkt (dropped 113, overlimits 0 requeues 1261)
backlog 0b 0p requeues 1261
maxpacket 25738 drop_overlimit 0 new_flow_count 2191 ecn_mark 0
new_flows_len 0 old_flows_len 0
qdisc fq_codel 0: dev eth3 parent :1 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
Sent 489490031 bytes 1009919 pkt (dropped 344, overlimits 0 requeues 918)
backlog 0b 0p requeues 918
maxpacket 25738 drop_overlimit 0 new_flow_count 2229 ecn_mark 0
new_flows_len 0 old_flows_len 0
qdisc noqueue 0: dev br-lan root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc noqueue 0: dev br-lan.99 root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc noqueue 0: dev br-lan.54 root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc noqueue 0: dev br-lan.70 root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc noqueue 0: dev br-lan.59 root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc noqueue 0: dev br-lan.69 root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc noqueue 0: dev myrsv root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc noqueue 0: dev wireguardif root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc noqueue 0: dev wireguardrursv root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc noqueue 0: dev wgprotonru root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc cake 800a: dev ifb4eth0 root refcnt 2 bandwidth 185Mbit besteffort triple-isolate nonat wash no-ack-filter split-gso rtt 100ms raw overhead 0
Sent 11294253452 bytes 9214510 pkt (dropped 0, overlimits 7957153 requeues 0)
backlog 0b 0p requeues 0
memory used: 286Kb of 9250000b
capacity estimate: 185Mbit
min/max network layer size: 48 / 1514
min/max overhead-adjusted size: 48 / 1514
average network hdr offset: 14
Tin 0
thresh 185Mbit
target 5ms
interval 100ms
pk_delay 119us
av_delay 25us
sp_delay 3us
backlog 0b
pkts 9214510
bytes 11294253452
way_inds 8
way_miss 43664
way_cols 0
drops 0
marks 0
ack_drop 0
sp_flows 0
bk_flows 1
un_flows 0
max_len 5856
quantum 1514
This is probably good, but will add some complications we need to keep in mind.
OK, so tis is the interface we should select for SQM.
Which is what you are doing, good.
Mmmh, if the wireguard traffic also goes over eth0, the cake instances there will see all VPN traffic as as a single flow and cake's fairness modes will not work (the VPN purposefully hides the information that cake needs to figure out the different flows constituting the aggregate traffic which it needs to teat all flows equitably).
This might be you problem. But @Lynx has solved a pretty similar setup, with some IFB trickery that still allows proper fairness even with wireguard VPN.
Mind you if ALL of your traffic goes via the VPN the easiest would be to instantiate SQM on the wg interface (with appropriately configured overhead) however if you mix some traffic over the raw wan and some via the VPN that will not work all that well.
1 Like
@Openwrtfunboy I have two possible solutions for you to consider:
The first would be by far the easiest and does this:
wg_endpoint=$(wg show | awk '{if($1 == "endpoint:"){split($2,a,":"); print a[1]}}')
# apply CAKE on upload (must be besteffort flows nonat nowash to work with the skb->hash preservation)
tc qdisc add dev $wan_if root cake bandwidth 30Mbit besteffort flows nonat nowash no-ack-filter split-gso rtt 100ms noatm overhead 92
# ifb interface for handling ingress on WAN (and VPN interface if wg show reports endpoint)
ip link add name ifb-wg-pbr type ifb
ip link set ifb-wg-pbr up
# capture all packets on WAN
tc qdisc add dev $wan_if handle ffff: ingress
tc filter add dev $wan_if parent ffff: prio 2 matchall action mirred egress redirect dev ifb-wg-pbr
# if 'wg show' reports an endpoint, then pass over wireguard packets on WAN and capture all VPN packets
if [ ! -z "$wg_endpoint" ]
then
tc filter add dev $wan_if parent ffff: protocol ip prio 1 u32 match ip src ${wg_endpoint}/32 action pass
tc qdisc add dev $vpn_if handle ffff: ingress
tc filter add dev $vpn_if parent ffff: matchall action mirred egress redirect dev ifb-wg-pbr
fi
# apply CAKE on download using the ifb
tc qdisc add dev ifb-wg-pbr root cake bandwidth 25Mbit besteffort triple-isolate nat wash ingress no-ack-filter split-gso rtt 100ms noatm overhead 92
It is run as a service and there is an appropriate hot plug file to handle VPN going down and/or up.
The second is slightly wacky (one might say: 'bat shit crazy').
Of course the second is the more powerful, but also trickier to setup and far more prone to messing things up.
1 Like
Kernel wireguard + cake is supposed to retain the flow hash values. Though I forget when that patch went in. Inbound... ugh...
1 Like
Yes the first solution above relies upon skb->hash preservation, but this only works for upload and DSCPs get stripped out. @tohojo wrote the following to restore DSCPs:
See: Qosify: new package for DSCP marking + cake - #1041 by tohojo
but to get round this I instead just set up two IFBs like this:
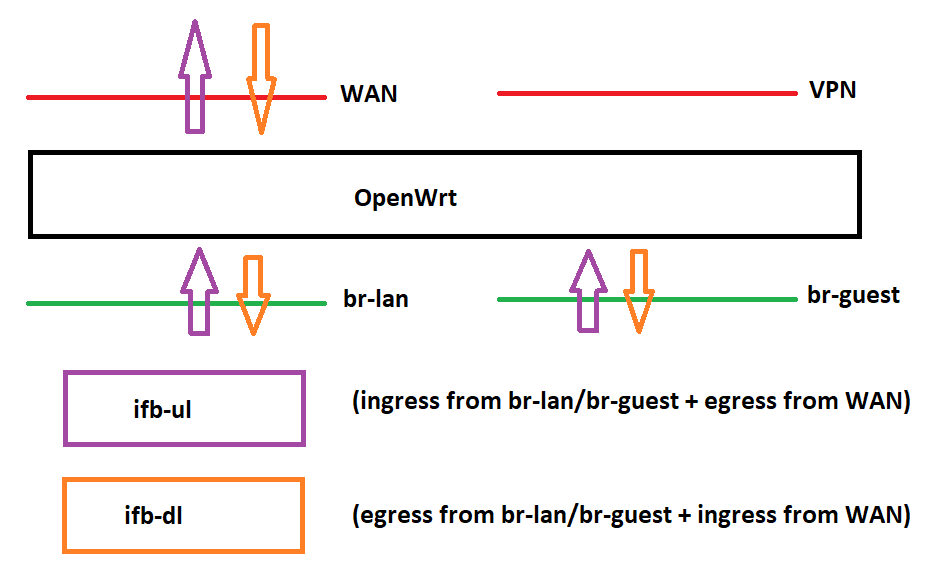
That is, create 'ifb-ul' by mirroring (purple arrows):
- a) appropriately selected ingress from br-lan and br-guest; and
- b) appropriately selected egress from wan.
And create 'ifb-dl' by mirroring (orange arrows):
- a) appropriately selected egress from br-lan and br-guest; and
- b) appropriately selected ingress from wan.
Appropriate selection is achieved through fwmarks using nftables to isolate and avoid duplication of the relevant flows including unencrytyped WireGuard traffic and OpenWrt->WAN and WAN->OpenWrt traffic, and skip out the LAN-LAN traffic.
Then apply CAKE on 'ifb-ul' and 'ifb-dl'.
This permits CAKE to properly function despite complex setups like use of VPN pbr and a guest LAN.
1 Like
Yes, but only if:
- cake and wireguard run on the same machine (likely the case here)
- only with simple flow fairness, the per-IP-isolation modes do not work for this
- only for egress traffic.
@Lynx solved 2) and 3) with ingenious use of IFBs so that two cake instances see all traffic unencrypted.
The only small sacrifice one needs to make is all packets need to be accounted with wireguards additional overhead. For encrypted packets that is all proper, but for those packets the by-pass the VPN that accounts for a bit too much overhead. But IMHO this is fine as it only trades in a small throughput loss for retaining responsiveness under load.
No chance CAKE could be patched to allow specifying multiple overheads based on fwmark?
1 Like
Oh sure cake could be patched, but who is going to produce the patch and who, with a straight face is going to convince the kernel's network maintainer to accept that exercise in detail-orientation-to-a-fault? ![]()
Realistically, before somebody takes this tangent too seriously, the loss of throughput is really tiny for anything like normal traffic, not worth stressing about. AND cake-autorate can be used if that loss appears still too large.
1 Like
Does SQM makes fair bandwidth by default? (100/2 if two clients, 100/3 if three and etc)
Btw i just changed SQM intefrace to my wireguard interface and now i will measure performance
No, to do this it needs to know the directions of the internet link, BUT its default approximates fair bandwidth sharing (actually it tries to be fair over both the internal and external addresses, which for many use-cases is very similar to the strict per-interal-IP-fairness that you describe).
If you want strict per-interal-IP-fairness you need to configure a few things...