Summary: How do I set up SQM/cake to work with both ISP native (ipv4) traffic and 6in4 (ipv6) traffic?
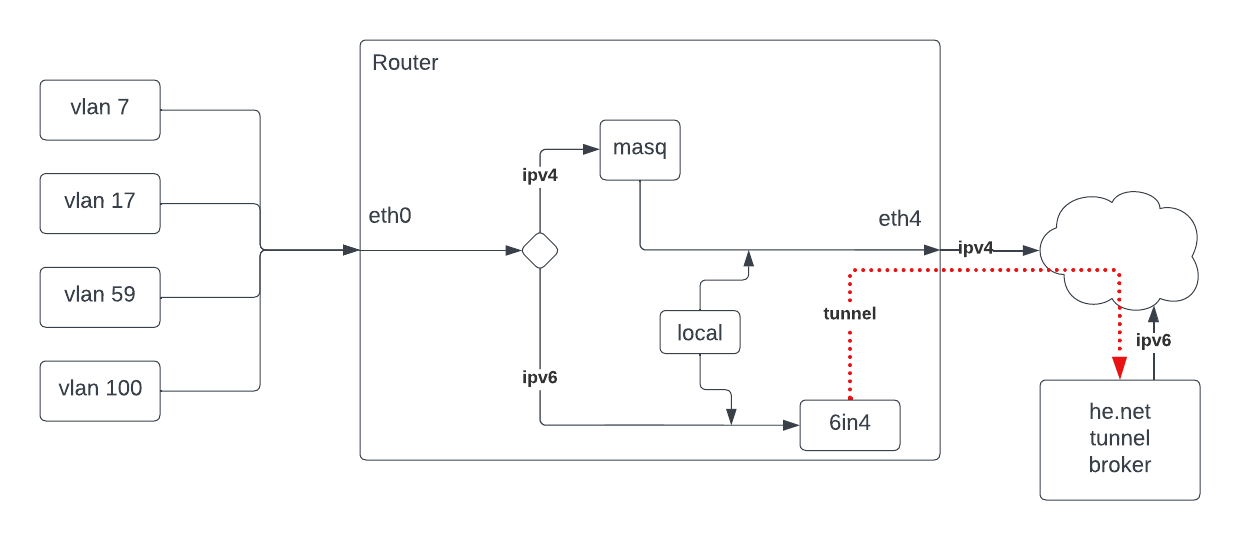
Goal: I would like to use SQM/cake/diffserv4 with my multiple internal vlans for egress to my ISP's ipv4-only connection and 6in4 (he.net) tunnel.
Comments: I understand that the out-of-the-box SQM is configured against a device, in my case eth4 which is connected to my cable modem, and is confimed by tc -s disc. While this does specific shaping on ipv4 traffic, it aggregates the ipv6 traffic into one flow encapsulated in an ipv4 connection. I only want cake on the egress (to internet) traffic. I do not see any options in luci to connect cake to something better, eg that will work on all (ipv4 and ipv6) traffic. How can I achieve this?
Other: Can I set up an ifb for all egress traffic, apply cake to it, then split the ipv4 traffic to eth4 and the ipv6 traffic to the 6in4 tunnel device? Is there a better or more simple way to do it?
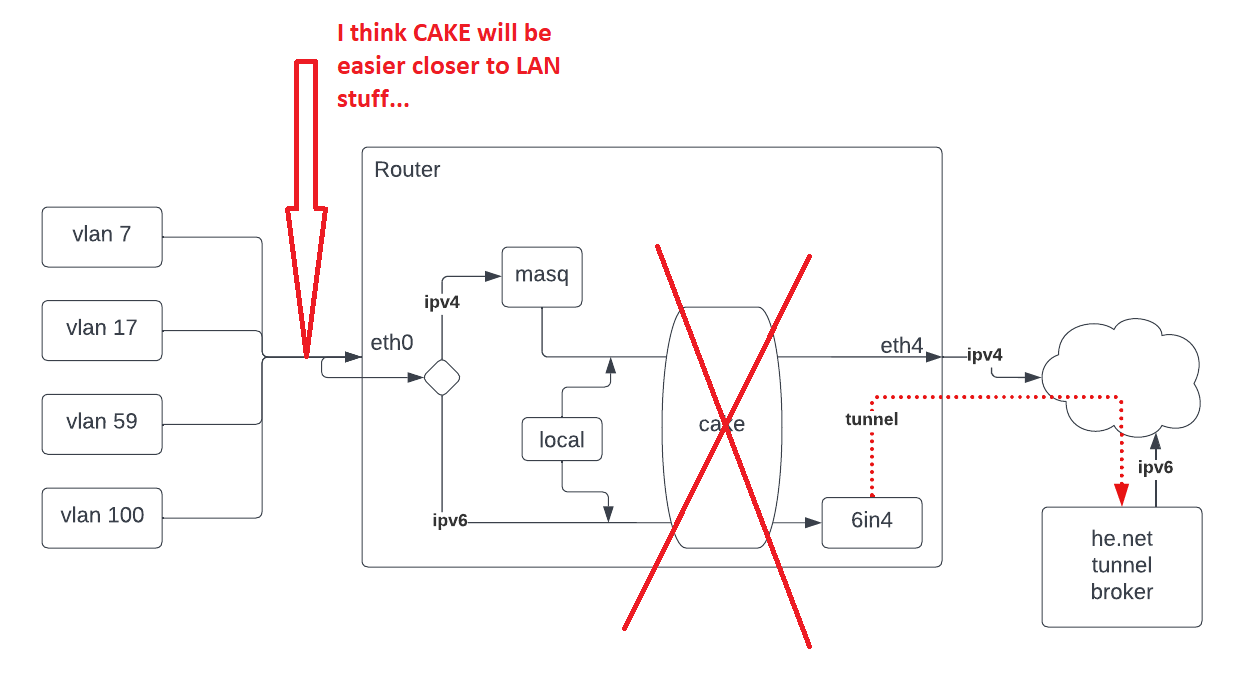
I'm not an ipv6 expert but I imagine you can set up IFBs for this. Incase it is helpful I recently put this together - it shows one way to set up dual IFBs and cake manually:
as best as I recall, fq_codel and cake both peer deeply into the packet and strip off the header and will hash on the actual ipv6 headers. You can verify this is the case by doing 4+ uploads in parallel and inspect the bk_flows parameter.
fq_codel and cake both peer deeply into the packet and strip off the header and will hash on the actual ipv6 headers
Hmm, I couldn't reproduce that. I have cake setup on the outbound wan ipv4 interface with diffserv4, and I can classify ipv4 stuff and see the counters go up in the appropriate tin. I made a rule to classify all ipv6 tcp traffic from the lan and it didn't cause the cake stats for that tin to incremented. I used https://ipv6.google.com to generate traffic, seems like it's really ipv6 packets.
I recently put this together - it shows one way to set up dual IFBs and cake manually
Nice, thanks for sharing. I looked at what you're doing and extracted what I thought was relevant, namely create the ifb-ul device, set it to up, add the ingress qdisc to a lan vlan, add the redirect filter for that vlan device to ifb-ul, and add cake to the ifb-ul device. (The "root prio" line didn't work, there appeared to already be a root qdisc for that device)
I saw data flowing into the ifb-ul, and the device on that vlan still worked (eg access internet), but the cake stats never changed, eg always 0 packets/bytes, etc. So it seemed like this path wasn't working like expected.
I'm pretty sure that I don't fully understand the qdiscs and filters. I think your setup is redirecting from inbound-from-lan to the ifb, but I'm not sure if that's appropriate for what I'm trying to do.
I am no ipv6 or vlan expert but perhaps the following may help here.
Please can you draw a diagram showing where your flows originate and end up? The beauty about IFBs is that you can pull out flows from anywhere (and the combined flows can have been pulled out from different points). So I wonder here if it is just a case of pulling out the flows at different points in their journey.
Quote from the developers to someone trying to do the same thing: Doing traffic control on vlan's may not work as expected because the vlan pseudo-device does not have any transmit queue.
Since you've already written your rules to rate limit by subnet, it's a matter of getting Linux to rate control it.
I would suggest working around it by putting the VLAN in a bridge (though for consistency's sake you might want to create a bridge for every VLAN):
brctl addbr br113
btctl addif br113 eth0.113
You can then apply your tc rules to br113 instead of eth0.113.
So looks like you could put your vlan in a bridge and then cake on the bridge?
This depends. If you do not want/need WiFi on the router things become considerable simpler. IIRC you just instantiate sqm on br-lan and set the desired internet upload rate in the download/ingress field and leave the upload/egress field empty. The tunneling likely happens between br-lan and wan, so this should get you what you need, however this will also affect transfers from LAN to WiFi and it will also not shape internet traffic originated by your router itself, so is not a general solution...
All in all this is a quick way to test things out and if that works, I would refer you to @Lynx who currently seems to be the resident IFB magician to come up with a better solution.
Just keep in mind that IFBs do incur a small CPU-cost so don't go overboard with IFBs (sqm typically uses one IFB, and I am sure increasing to 2 IFBs will be fine, if that pushes you over CPU wise you have been living to close to the edge already )
It always helps to post the output of tc -s qdisc so we are all on the same page.
I think IPv6 is a red herring here, the issue is "tunneling" in general so the IPv4 tunnel for IPv6 flows causes the same challenge your VPN does. In theory one could have cake look deep into the 6in4 tunnel since that is not encrypted, but it appears cake does not do this by default.
This reminds me why I try to get away with as little VLAN manipulations as possible, tricky business that.
Try cake on eth0 with ingress and egress rate flipped around (ingress/egress are in reference to a network interface, and eth0's ingress is your internet upload). At that point you should be set, but you still need to add 20 bytes to the per-packet-overhead, as 6in4 surely will have an additional 20 byte IPv4 header that cake does not know about.
Mind you you can also follow @Lynx's great example, but for quick testing cake on eth0 should work...
.. not that I really understand vlans properly. What will this do with per-internal-host-fairness if on eth0 as you propose @moeller0? Will it just work? Or would something different be needed to make that work properly?
Ah cool. @beetlrokr in case it helps I found 'tcpdump' very helpful in looking at the flows although it can be deceptive so has to be used with caution. But you can use formulations like 'tcpdump -i $interface -v' to show TOS values for packets in the interface and you can even filter with e.g. 'tcpdump -i $interface -v ip[1]!=0' to show non-zero TOS values, or using port number with e.g. 'tcpdump -i $interface -v port 53' or by host 'tcpdump -i $interface -v host 1.1.1.1', etc. I've found it very helpful to check DSCP values get set correctly and correct packets in IFB interfaces. Not sure if this will work in your vlan case though since I don't understand those yet.
I spent some time with this today. Here are some observations.
First, setup and testing methodology:
Client is a lan machine running iperf3 using "-S 0xB8" to a public iperf3 server (ipv4 and/or ipv6). In all cases, I see the DSCP value in the packets on the wan.
cake was applied to either br-lan or wan interface (eth4), with diffserv4.
When iperf3 was running, I would watch while true; do tc -s qdisc | grep cake -A29 ; sleep 1; clear; done to determine how cake was tin'ing the packets/flows.
Observations:
With cake applied to br-lan, everything (ipv4 and ipv6) from the lan was being catagorized/processed in cake as expected, including vlan traffic. However, traffic to the router was also included in cake processing, eg dns lookups, etc. When I ran iperf3 server on the router and using a lan iperf3 client, the speed was limited to the cake-configured max speed; without cake, the speed was 5x.
With cake applied to the ipv4 wan interface (eth4), only ipv4 traffic was categorized in cake. I could see the encapsulated ipv6 within the ipv4 packets in tcpdump eth4, and the DSCP value was present, but that ipv6 traffic ended up in the "default" tin instead of the higher priority tin.
I see in the linux kernel 5.10 source code for cake, a special-case processing block for 6in4. If it was intended to introspect the packets like it's doing for vlan's, it's not working.
And... got it to work. Found a message on the cake mailing list that describes how adding this to the wan6 interface config allows 6in4 introspection: option tos 'inherit'
Now my 6in4 ipv6 traffic is correctly categorized by the wan cake.
I spent time today dealing with e.g. DNS hijacking by just creating appropriate nft rules. I've committed changes that address this to:
If you redirect to IFBs you can control what gets redirected by tc filtering on fwmark and setting the appropriate fwmarks in nftables - see my .nft file.
You have to really think about the flow of traffic and the various nftables hooks.