Yes that seems like a good idea, setting MSS to BW * 0.005 seconds will help VoIP a lot on slow links less than 3Mbps.
According to docs on HTB setting quantum less than MTU is invalid and leads to incorrect bandwidth calcs
HFSC doesn't have a quantum concept, it works based on packets actual size and the configured bandwidth settings for the class. Really quite nice once you wrap your head around it.
Oops, sorry, you are correct, I guess I was talking about fq_codel's quantum parameter. (Actually sqm-scripts scales HTB's quantum with bandwidth to somewhat keep the CPU cost under control).
Best Regards
Yes so for example suppose you have two classes, voice at highest priority guaranteeing 10 Mbit/s and surfing at low priority guaranteeing 900 Mbit/s on a 1000Mbps link. You have absolute priority for voice, and you've only got say 2 phone calls so you really only need 200kbit/s so it seems like this would be ideal.
However, by default HTB uses 10 for r2q and then calculates quantum ~ 1e9/10 = 1e8 bits, so latency between switching classes is maybe around 100 ms if I understand correctly. Once HTB gets ahold of a surfing bucket, it sends packets from it for hundreds of milliseconds! Of course, you can set r2q = 100 say and now your quantum is basically 10ms worth, but it requires more CPU and soforth In general, HFSC does the right thing with tunable parameters that directly reflect latency and bandwidth concerns (if you use the m1 d m2 format for specifying the service curves). And the decision is made on a per packet basis so there's no batch latency issue. I'm not sure how the CPU usage compares.
If I recall correctly, the costs of the shapers, be it HTB, HFSC, or cake is pretty similar (see: https://openwrt.org/docs/guide-user/network/traffic-shaping/sqm section: "Selecting the optimal queue setup script") HTB has a tendency to strictly enforce the configured latency goal (well HTB as used in sqm without "burst") while HFSC (as configred in sqm) and cake will make concessions in the latency goal but will allow somewhat higher bandwidth, but if we ignore the wifi results (wifi has its own set of issues so leave this out) both HTB and HFSC are in the same order of base2 magnitude (which indicates to me that both have comparable CPU cost).
Thanks for the details on HFSC.
@dlakelan - I am curious if in the intervening 2 years you have changed your opinions any regarding the need for hfsc vs cake's methods? It came up again...
Hi Dave, thanks for asking! I still use HFSC. The scheme works well if you are doing custom DCSP and I really like the real-time behavior. My current HFSC setup uses 2 real-time queues and 4 link share queues. the top real-time queue is for VOIP phones. The VOIP queue long term behavior is to have enough bandwidth for about 10 simultaneous calls... But for a burst of up to 20ms it gets 50 times that bandwidth. This makes my calls ROCK solid.
Next comes about 10Mbps of gaming traffic, which works great too, it bursts at 20x that rate for up to 20ms. Most of the time it's not a major player on my network but it's nice that my kids don't complain about lag.
Essentially all the real time traffic is UDP, so I don't use fq_codel below these classes, I use pfifo. The design of these queues is that they essentially never have more than a few packets in them due to their allowed burst rate.
My link share queues are kind of a Video, Normal, NFS/Samba, and Bulk system.
Video gets low latency through high bandwidth burst at 60% of the link, but long term is limited to something like 20% of the link. it's for both streaming and vidconf at the moment.
normal is where most stuff starts. It gets 20% of the link in burst, and 50% of the link in steady state. Stuff that transfers more than a few seconds of data continuously gets demoted to bulk.
The NFS queue is where all my network mounts sit. It gets 15% burst (so it is a time donor) and 20% long term.
Bulk gets 5% burst (it's a HUGE time donor) and 10% normally, with an overall hard limit of 95% of link (when its the only thing going at the moment, it still leaves a little room for new connections to initiate).
In addition to queues on the router, I use smart switches that have WRR behavior based on DSCP. This keeps purely local LAN traffic from interfering with high priority packets. This is an issues since multiple machines network mount home dirs via NFS4 and the NFS server has a bonded link and can saturate some of my wires and all of my APs. I also have one portion of my house served by a powerline adapter, which is limited to about 40Mbps in my switches. that limit plus WRR behavior results in a stable link across this bottleneck.
I think cake made some mistakes in it's DSCP mappings for diffserv4 that mismatch both with commonly available switches and with default Linux driver WMM mappings. but for the most part, cake is great. most people should try piece of cake, and then cake diffserv4 before anything else.
Why do I stick to HFSC? I really like the control of latency and bandwidth and the ability to separate real time from link share. I like being able to stick my high priority UDP traffic in something other than codel as it really shouldn't ever drop. (I probably should use RED in my UDP flows... but in truth it's never needed). I don't want dropped packets in my high priority UDP flows. I like the fact that the HFSC does a really nice packet-by-packet job of interleaving packets. It rarely if ever actually drops packets:
my lan egress queue:
qdisc hfsc 1: root refcnt 2 default 40
Sent 302603740730 bytes 456270028 pkt (dropped 11, overlimits 7353071 requeues 0)
backlog 0b 0p requeues 0
eleven packet dropped out of 456M
and my wan egress queue:
qdisc hfsc 1: root refcnt 2 default 40
Sent 88526041589 bytes 309218709 pkt (dropped 1, overlimits 1528385 requeues 0)
backlog 0b 0p requeues 0
It dropped ONE packet out of 309 million
What HFSC is really good at, when its class hierarchy is designed well, is interleaving packets in such a way that they all meet their time deadlines
of course it doesn't hurt that I have ATT gigabit GPON fiber 
The home network environment, particularly for people with say home+office, has gotten rather closer to what used to be "enterprise" requirements. In say 2005-2010 entire college campuses of 10000 people had less bandwidth to the internet than I do to my home. For me it's super important that my family NEVER EVER garbles my business phone calls for example. Now that we're in coronavirus lockdown, it's also really important that my family NEVER EVER garbles my wife's video lectures or seminars. Having different priority items go into different queues designed for their purpose makes sense to me. Of course, we're running more like a business in my house than a typical home network.
Also, I'm using nftables for all my firewalls, and sophisticated DSCP marking schemes are quite easy in that system.
I had hoped to expand on that more, but OpenWrt seems to have issues with nftables in recent releases so I was stymied a bit. After a future release, where nftables works correctly, I will return to that to try to teach people how to DSCP mark their important traffic.
1 Like
Thank you for the detailed reply. A few questions:
-
AT&T GPON got ipv6 yet?
-
What "smart switches" do you use? Certainly I don't think much of the ones I have, as they treat dscp as strict priority queues...
-
I would be very interested in making cake's four tier model line up more with reality
-
I am going to be adding some security cameras and I don't know what they will do to the network. Ironically rolling those out was stalled out on how bad the ath10k was behaving on my backbone and all those radios were the right POE type for the cameras I never deployed, so...
-
I abandoned the hfsc attempt in sqm because it was buggy, and in particular, didn't break up superpackets, which I found necessary to do on the links I have, which are typically 100mbit down, 10Mbit up, these days. How well is HFSC handling superpackets these days? (you can see below how often I get them)
-
In my case I have had a sudden increase in zoom traffic on my campus, in particular, and I didn't know a lot about its characteristics. "zooming" around the web I see pretty bad frame rates and encodings for many folk, which I tend to put down to slow uplinks and bad bufferbloat, but I'm still tearing apart captures, and fiddling with servers (trying sylkserver now) running locally where I can at least see rtp stats after they've been decoded.
I have a feeling zoom, et al, tend to over-react to any level of packet loss.
Bulk Best Effort Voice
thresh 562496bit 9Mbit 2250Kbit
target 32.3ms 5.0ms 8.1ms
interval 127.3ms 100.0ms 103.1ms
pk_delay 6.2ms 8.4ms 881us
av_delay 1.6ms 578us 168us
sp_delay 19us 69us 5us
backlog 0b 0b 0b
pkts 768141 535738245 2796824
bytes 749471121 113409386700 655953809
way_inds 6183 33349585 184243
way_miss 43154 8894534 160920
way_cols 0 0 0
drops 89 116793 5
marks 118 102 4
ack_drop 0 52660752 439
sp_flows 1 5 1
bk_flows 0 2 0
un_flows 0 0 0
max_len 15605 25936 4542
quantum 300 300 300
YES! I am a happy camper. In my particular case I have to ask for separate /64s rather than asking for the /60 and sub-dividing myself. It requires a custom wide-dhcpv6-client config. But I think this is just a quirk of my CPE device. I bought in ASAP after they rolled it out, so I've got an older Arris NVG599 as the CPE.
I use two, one is a Zyxel GS1900-24e and that lets me set either strict or WRR behavior, and I can apply a custom map of DSCP to queues and stuff... It's pretty nice. The other is the super cheap TP-Link sg108e which uses WRR behavior but treats DSCP like a strict priority ranking number. It's got 4 queues and it just breaks up the DSCP range into 4 ranges, and then applied 1,2,4,8 weighting to the queues... Because of this mismatch I retag all my CS0 traffic to CS3 so I can use CS2 for my NFS stuff and CS1 for bulk... But cake takes CS3 to be video priority, and WMM in linux takes it as BestEffort... sigh
I would be very happy to work with you time permitting. The first thing I think you should look at is how linux by default maps WMM, and try to line up the cake tins with the WMM tins: https://wireless.wiki.kernel.org/en/developers/documentation/mac80211/queues
Maybe we should have a private message conversation about what your projects are and what kinds of stuff I could send you to test against cake and etc? I have a kind of complex hierarchy of queues I set up with @hisham2630 at one point and it kind of recreated a lot of cake functionality more or less. I can add you to my private github repo on that and you can take a look at it. PM me your github account. Most likely it's time to make that public anyway but maybe we could discuss and it could get incorporated into SQM at some later time?
Ah yes, I forgot to mention I have 4 IP video cameras. I use the PoE version of the sg-108e to power them. I put them on their own VLAN, and that VLAN has zero forwarding to the internet. I put a bandwidth limit on each camera port egress and ingress at 10Mbps. Two of the cameras are on the far side of my powerline link. So far, with my scheme in place, they haven't caused any trouble at all with my media PC which is also on the far side of that powerline link. I do think they use DSCP, but I don't remember what they put on the packets.
I honestly don't know. I have seen superpackets in captures, and I haven't complained much about problems... so my basic inclination is to say it handles them fine at least when it's not under heavy bandwidth pressure... Here's me opening up netflix and starting to stream an episode of ST:TNG while surfing the web and using NFS4 for my home directory:
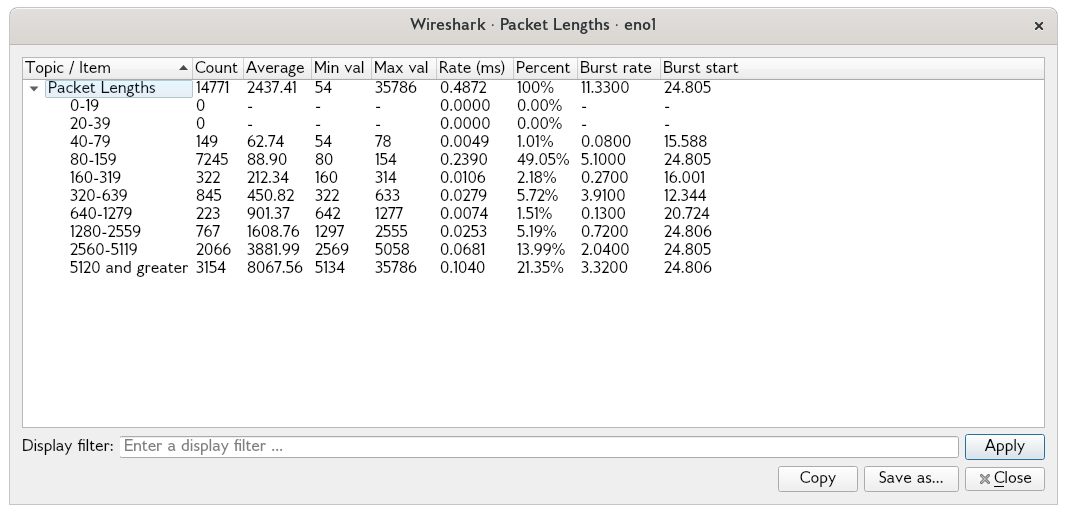
So, yeah, superpackets are a major thing. This desktop runs my HFSC scheme on egress. I don't have complaints but would be willing to test things if you had specific questions.
Superpackets on my network are probably not so important due to the high speed. At 10Mbps a 35000 byte packet which was the max captured above is pretty painful though, 28ms of delay would hurt VOIP a lot. I wonder if it's possible to create a qdisc that just breaks up superpackets? Something like "psuperfifo" which when it gets a superpacket queued, it just breaks it into multiple packets and shoves those in its fifo? I'm not sure how that would work really, because you'd probably want it at a leaf, but then you'd want it to feed into something like fq_codel or drr or whatever, and I don't think you can piggyback qdiscs that way unless they're classful right?
I've seen some pretty horrid zoom images/sound... I have been telling everyone who will listen to not use zoom due to security stuff. I'm a big fan of https://meet.jit.si/ and I think it has better audio quality in general, but in general if you have a terrible network connection, and many people do, then there's kind of nothing that can be done except fix that. Everyone who gets on their congested wifi in a big apartment or dorm, and has interference, and background wifi scanning, and blablabla... winds up looking horribly blurry and jerky and stuff on all these vid-conf services.
I will say that my mother, who is on a VDSL link with ~ 4000kbps uplink, and a wire, running cake on a ZyXel Armor Z2 (OpenWrt, remote managed by me) has a rock solid image and sound on Jitsi. She's always the only major user on her network though.
interactive video is a new thing, and people are mostly putting up with crappy connections because most people don't have anything like the necessary skills to know how to improve it. cake should be a huge win for them.
Yes, video conferencing has similar latency demands as interactive on-line games, so quite a number of folks might become sensitive to the issue right now....
thx for the long reply. I note that I'm no fan of WMM and would prefer the AP (at least) not use it at all, relying on better scheduling on the AP to get things right. This includes things we don't do, presently, notably reducing the max size of the txop in the beacon and AP when under contention, and scaling hw retries down as a function of the actual rate. The people that designed 802.11e were on drugs, IMHO. That said, I see a use for it for voice traffic from the clients, and perhaps - although I've not pursued it very hard, videoconferencing.
I think putting VOIP phones into the VO queue and video conferences in the VID queue, and bittorrents and long downloads into BK queue makes the whole thing work a lot better provided you don't try to run way too much voice or video traffic through the the appropriate queues... it seems like if you enforce a min modulation rate of 12Mbps and you put less than 1Mbps through the voice queue, it works fine. I can cover a whole single family home with 1 AP using 12Mbps min rate just fine (though I have two).
So, I do think if you have voice and video chat systems (and games) it pays to identify them and DSCP them. With appropriate DSCP the WMM is automatically utilized. With nftables, tagging packets is relatively easy, though I think iptables is much less friendly.
If you want to use default settings for WMM queues, then CS6 for voice, and CS5 or AF41 for video work. If you use EF for voice, it goes into the video queue ![]()
1 Like
The voice queue on 802.11n cannot aggregate packets, so it has generally seemed that VI was the better queue.
not if you're really doing voice.
And do see the ongoing thread on the ath10k about how horrible be and bk behave when vo and vi are saturated in a bufferbloated chip. In general packet aggregation is so much more efficient than 802.11e scheduling and provides better results as we showed in https://arxiv.org/pdf/1703.00064.pdf - so long as you are using our algorithms for those chips. Other chips, well, it's a crapshoot. As you say, if you don't flood those queues, sometimes they do work better.
Also yes, if you have some kind of smarts in the driver it may well be a different story. I don't have ath10k devices, at the moment everything is unfortunately on mvebu which really does have all kinds of issues, especially with power saving devices, and requires me to reconnect my devices a few times a day.
I'm just waiting for cheap enterprise APs using WIFI6 with the 6GHz spectrum (did the FCC actually approve that ?) ( I just looked online, and apparently the vote is April 23... https://www.forbes.com/sites/waynerash/2020/04/02/fcc-approval-expected-for-expanded-wifi-at-april-commission-meeting/ )
And to avoid that we can use HFSC. So for example if you have a real-time queue with a 1Mbps max rate, and shove all your CS6 packets in there, then this is enough for about 10 VOIP calls or more, but guarantees you don't flood the WMM VO queue.
I suspect a link-share queue set for the VI/BE/BK queues would be helpful.
Obviously wifi is variable rate, but the packet-interleaving and the hard sending limit of the real-time queue for the VO should help a lot.
That in a nutshell is where WMM goes pear-shaped, there is no real incentive to use the higher ACs sparingly, so in a crowded wifi environment all AC_VI or even all AC_VO is the subjective optimum...
Which is not so bad, after all most competition is from the AC_BE queues of your neighbors (the race to start a tx_op is independent of SSID and basically happens between all units operating on the same or really close by channels, as far as I understand).
Is this still true for 802.11ac and higher, though?
Erm, a station flooding a channel with AC_VO packets will basically starve everything else on that channel to a trickle, no air-time fairness code in the AP really has a fighting chance against that. We would need something adaptive in the AP that will escalate the AC classes for all packets to assure a certain minimum airtime access, no?
But that is what WMM should have fixed on the architectural level, arguably. Making it bad to flood these "higher" ACs in some way, or limit their use ot a certain fraction of tx_ops...
You need to do this on all devices using that channel though so AP(s) and all stations, most client machines will not use a traffic shaper, no?
Out of the everything is terrible department, but at least I got to complain ![]()
True, client machines are a different story... But I have yet to see an instance where a non-malicious client made my APs grind to a halt. And I haven't tried a malicious client, but I suspect the modulation limit would help somewhat.
All I can say is that in practice this makes wifi smartphones usable as SIP clients, and without it, they're unusable. It's possible that you could put your SIP phones into VI queue and do fine, but it's also possible that you'd find someone firing up a video chat would make your phone call go to hell.
1 Like
Oops, in my ranty bickering about my perceived short-comings of the WMM architecture, I also directed critique against your network set-up. That was not intended, sorry.
The thing is, DSCP are free for all, so even a bulk sender marking all packets CS6 is technically misguided, but not unambiguously malicious.
I am not sure, video chats are by necessity sending their frames ASAP and hence pace out their traffic relatively nicely (okay, they will burst all packets required for a given frame, but after that will by quiet until the next frame happens, at least on the video side, and the voice packets for video chats have similar constraints as pure VoIP packets). My hunch is, AC_VI probably works sufficiently well, as long as long term bulk flows are kept to AC_BE and AC_BK. But my understandimg just comes from running flent over a wifi link with different DSCPs and WMM in use, so I might be too generous in judging the latency effects...