No idea yet why it gets send out, but the PLC applies it and the PC sets it to 536.
Such small packets causing for sure a slow throughput.
I am wondering if there is a minimum MSS size which you have to maintain.
The default TCP maximum segment size is 536, I am wondering if the PLC is allowed to go below it, even when it gets the request by the SYN packet.
Oh boy, I found the problem which caused the main issue:
The number after the mssfix are the bytes now.
In older versions it just enabled or disabled it, but in the current version you have to write it like this: option mssfix ' '
On this way has it set the MSS to 1, but is was limited somwhere to 60.
The PLC applied the 60, the PC applied the 536 and this was the reason why it was worse on the PLC side compared to the PC.
Probably got the PLC overflooded by a high amount of small packtes and this caused further problems.
I will have a look on Monday if there is anything else not in order with the PLC, because something is still strange when packets get re-ordered and I think I will create a new setup without VPN to prevent any problems from there.
Yep, that'd do it. Glad you figured it out, hopefully with mssfix set to something like 500 or 1000 or even 1400 or whatever it will just behave more normally.
Yes, mssfix is not set to any value, so it applies its default value from my option fragment '1344' setting and my TCP packet size is now 1287 byte, what sounds reasonable to me.
The upload time from the PC looks pretty stable at around 9s, the PLC upload time varies between 9s - 36s, what is for sure much better as it was before.
I will do more tests (delay, packet loss, packet re-ordering) next week with a router only setup to prevent any influences from the Internet or VPN line during my tests.
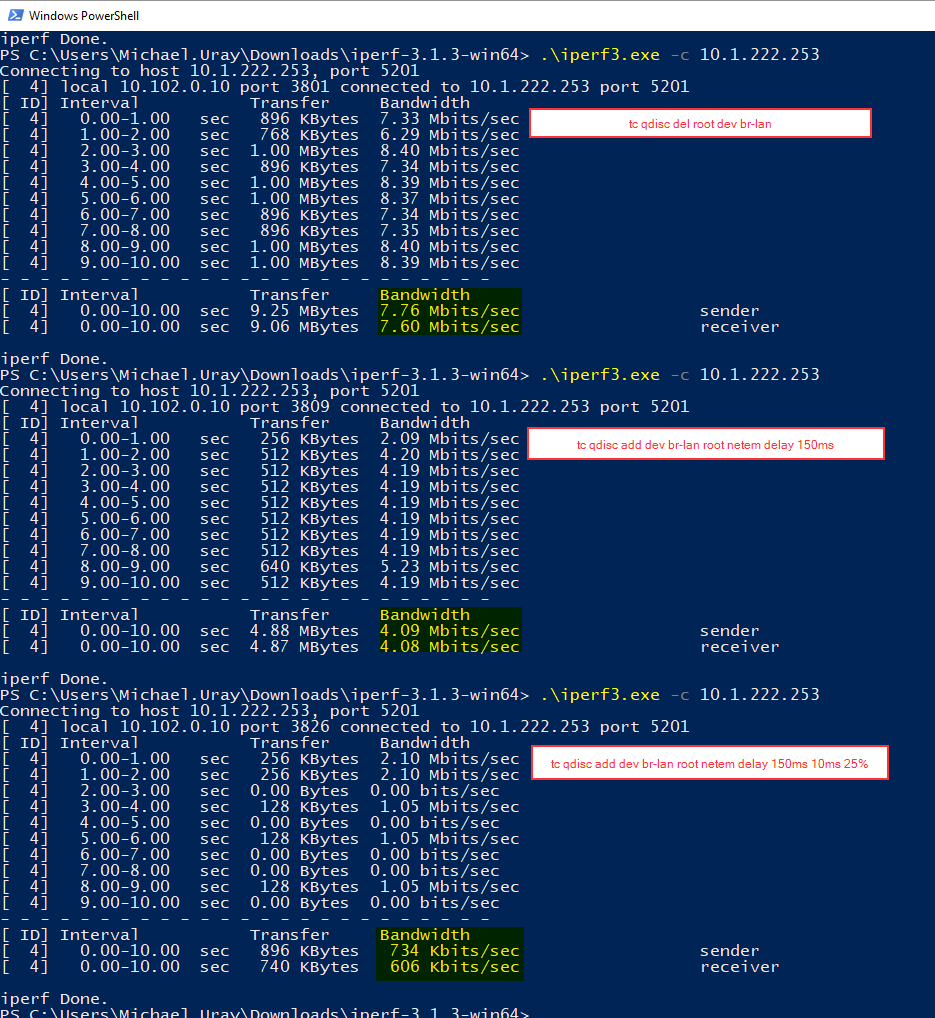
I got some interesting test results how the throughput changes with delays in the line as well as when package reordering starts.
The delay has a high influence on it (what would have expected somehow), but the package reordering much more (what I did not expect, since TCP should be able to handle it).
It is only TCP where the bandwith drops, UDP works fine, even with the delay and the packet-reordering.
Test without VPN, directly connected to the OpenWRT router.
PC->USB->Ethernet->Router1-> Router2 (iperf3 server)
Delay and packet reordering is enabled: tc qdisc add dev br-lan root netem delay 190ms 10ms 25%
Poor and older implementations of TCP will acknowledge the first packet that is part of the contiguous reconstruction, forcing the sender to resend everything else, you can imagine if you send 10 packets and the first one arrives last that you will resend the other 9.
There might be options you can enable in the PLC to do selective packet acknowledgement which should mitigate.
I did this iperf3 test with a Windows 10 PC connected to an USB Ethernet adapter to an OpenWRT router which routes (and delays) the traffic to a second OpenWRT (10.1.222.253) router which acts as FTP server.
Both running with OpenWRT 18.06.1.
This is the Wireshark capture of my FTP upload test from the OpenWRT router (10.1.222.253). Routed, delayed and packets reorderd via another OpenWRT router (10.1.222.254 &192.168.80.1) to a Windows 10 PC (192.168.80.2), there is no PLC involved in all of my iperf3 tests.
Right, so you may be able to force the devices you are doing these tests on to use selective acknowledgement because their operating systems are going to support it.... but if you manage to get that to work... it doesn't mean you can get it to work with the PLC unfortunately, since both ends of the conversation must support it.
I'm interested to see what your wireshark looks like. I'll take a look and see if there's anything I can figure out from that.
So when I look at your very slow transfer, there's a TCP conversation you can filter out using this filter that's the main data transfer:
(ip.addr eq 192.168.80.2 and ip.addr eq 10.1.222.253) and (tcp.port eq 5841 and tcp.port eq 5201)
packet 30 is an Ack for the first 38 bytes, and then packet 34 is the first data transfer for byte 13178 so about 13000 bytes are missing. the receiver then in packet 35 re-acks the 38th byte indicating to the sender "Hey I haven't gotten anything past byte 38" then the receiver receives in packet 36 seq number 7338 (out of order) and receiver sends again "ack 38" .... this continues like this quite a bit... basically almost all the bytes being sent are arriving out of order and the receiver is ignoring anything that comes in that isn't byte 39 and onward....
So you can imagine this is terribly inefficient because only 1 in 100 packets is useful to the reconstruction.
TCP selective ACK would, instead of ACK=38 say "ACK=38, SACK=13178" on packet 35 which would tell the sender "Hey I haven't received past byte 38 but I did receive bytes starting at 13178" so at least eventually the packet for bytes 13178 wouldn't need to get resent.
With this much reordering though, I suspect you'll never get anything fast even with SACK.
The UDP throughput stays almost at the same in all situations, but the TCP throughput goes down drastically when I activate a delay, independent from the packet-reordering.
Nice testing results. TCP has a bunch of timers involved, including all the various possible options, it's a fairly complicated algorithm. One thing that might be happening is as your delays get up in the 190ms range, your round trip time is enough that the ACK doesn't come fast enough and the sender winds up re-transmitting under the assumption the packet was lost and no ack is coming... or something similar. There are a large number of sysctls available to tune TCP in the Linux kernel, but I don't know how many of them will help when only one side of the connection supports it.
You might want to start looking for whitepapers or journal articles etc on tuning TCP performance in high delay applications. It's a pretty specialized area of knowledge.
Some of the relevant stuff is around "Bandwidth Delay Product" (BDP) supposing you have a reasonably fast connection, say 10 Mbps, but a very long delay, say 200ms each direction. Then you can push 10Mbps * 0.2 s = 2Mb = 256 kilobytes onto the wire before the other end even sees anything and you could push 512 kilobytes onto the wire before you receive an ack (RTT is 0.4 s). at 1500 bytes per packet that's 167 packets or so one way, and 334 packets round trip. So you'll need large buffers and selective acknowledgement, and etc etc to make this efficient, otherwise you'll send say 3 packets, wait 0.4 ms for acks, and then send 3 more packets... or whatever, TCP can somewhat tune itself but it does make some assumptions about delay times that you might be able to tune and certainly can tune buffers so it can accumulate out of order packets and delay ACKs so that it can acknowledge more packets all at once.
I am wondering how I am am able to achieve a 100 MBit/s download with my Internet line at home.
According to these tests is then a 30ms latency the maximum possible delay to the server with 100 MBit/s.
What if you have a GBit/s Internet connection?
I think what's going on is what I said above. You should try tuning kernel parameters to allow large BDP and alter certain timers, for example:
sack_timeout - INTEGER
The amount of time (in milliseconds) that the implementation will wait
to send a SACK.
Default: 200
tcp_rmem - vector of 3 INTEGERs: min, default, max
min: Minimal size of receive buffer used by TCP sockets.
It is guaranteed to each TCP socket, even under moderate memory
pressure.
Default: 4K
default: initial size of receive buffer used by TCP sockets.
This value overrides net.core.rmem_default used by other protocols.
Default: 87380 bytes. This value results in window of 65535 with
default setting of tcp_adv_win_scale and tcp_app_win:0 and a bit
less for default tcp_app_win. See below about these variables.
max: maximal size of receive buffer allowed for automatically
selected receiver buffers for TCP socket. This value does not override
net.core.rmem_max. Calling setsockopt() with SO_RCVBUF disables
automatic tuning of that socket's receive buffer size, in which
case this value is ignored.
Default: between 87380B and 6MB, depending on RAM size.
tcp_sack - BOOLEAN
Enable select acknowledgments (SACKS).
tcp_comp_sack_delay_ns - LONG INTEGER
TCP tries to reduce number of SACK sent, using a timer
based on 5% of SRTT, capped by this sysctl, in nano seconds.
The default is 1ms, based on TSO autosizing period.
Default : 1,000,000 ns (1 ms)
tcp_comp_sack_nr - INTEGER
Max numer of SACK that can be compressed.
Using 0 disables SACK compression.
Detault : 44
if tcp_rmem is too small then you'll send just a few packets, wait a long time for acks, and then send a few more packets. On my Debian box tcp_rmem is by default:
4096 87380 6291456
You might want to set tcp_rmem to something like:
4096 409600 6291456
and enable SACK
but again, you'll probably not have control like this on your windows machine, and it might not work well for your PLC either.
I do have that (but it's shaped to somewhat lower for various latency related reasons)
Here is a DSLReports speed test limiting my connections to 1 stream at a time:
Here is with the setting at 20 streams but it actually chooses 12:
Obviously if I demand a lot from their servers which are doing a lot of other tests at the same time, they will not deliver more than about 25 Mbps down. I can send 386 up... but if I distribute across multiple connections, then I can get full speed.
Latency is relatively low here, a few tens of ms.
I'm not sure what your OpenWrt routers have for hardware, but they may be CPU and memory limited in such a way that they don't like buffering all those packets to cause the long delays.
That is pretty nice man, as well as these test results!
We only get 6 MBit/s in our company for about 40 people and we already use 4 pairs of copper to get that. I added there a second Internet line via a LTE modem to get rid at least of the web traffic on the DSL line.