This looks somewhat odd, the first and last values imply the measurement might not be have been long enough.
weird. I didn't stop the script, it ended by itself.
I'll try again.
I've done some tests : it seems better. Updating a game on a PC a watching a movie on the other PC (always through SSH mount) makes it less glittering (or not at all with 480p movies).
I don't think we can do better with such an connection. I'll try to look for a video player that can buffer more (didn't find it onVLC)
Here is another result of ATM overhead detector, that ran for less than hour and stopped ![]()
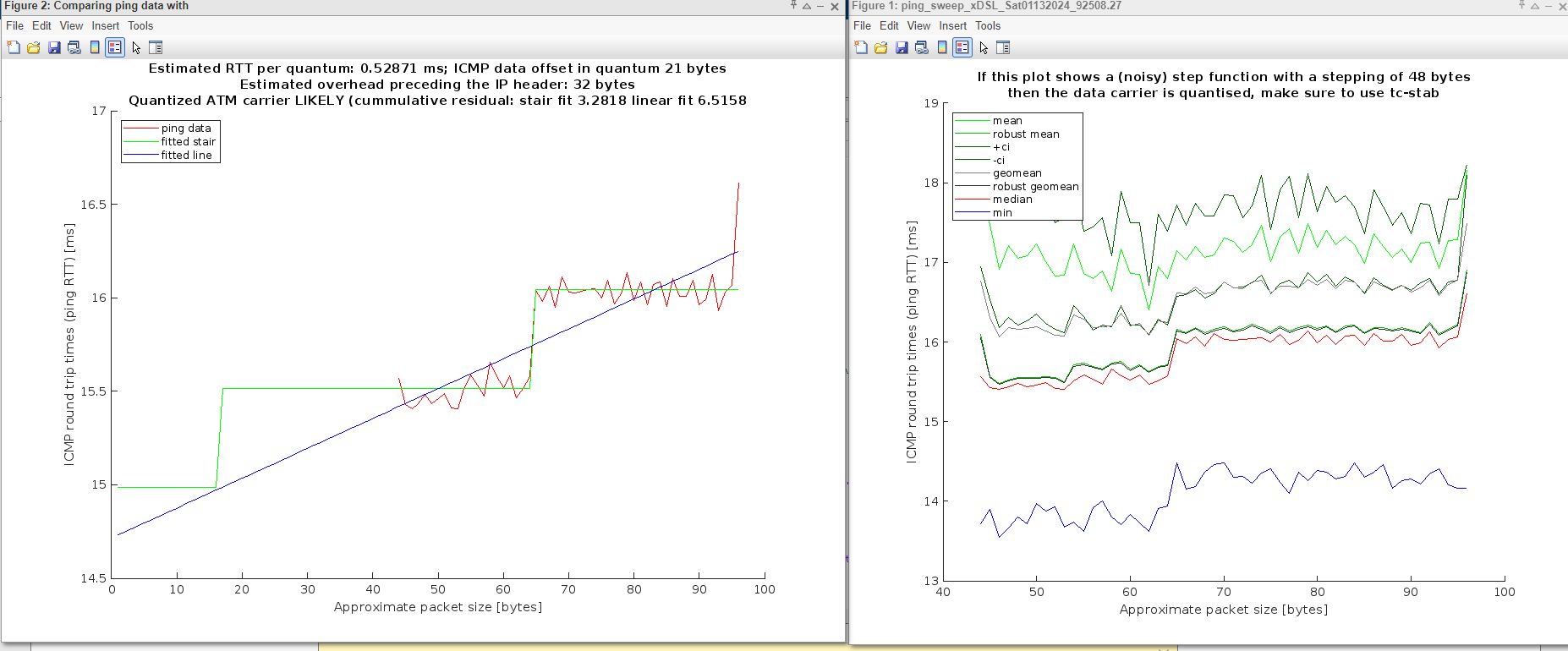
Thanks for your time and explanations @moeller0 . That's better now ![]()
Mmmh...
Would you mind sharing the data file with me, so I could have a look at what is going on here? My guess is that the ICMP reflector only responds to a small set of ICMP packet sizes and that causes some issues... which IP address did you use as reflector?
I didn't change the reflector and kept the one in the script : Google DNS 8.8.8.8
Here are the ping results : https://filetransfer.io/data-package/OzCochKm#link
Ah, it turns out 8.8.8.8 will not reflect arbitrarily sized ICMP echo requests, but limits thngs
´´´
user@123-1234563 space % ping -c 2 -s 95 8.8.8.8
PING 8.8.8.8 (8.8.8.8): 95 data bytes
76 bytes from 8.8.8.8: icmp_seq=0 ttl=115 time=10.822 ms
wrong total length 96 instead of 123
76 bytes from 8.8.8.8: icmp_seq=1 ttl=115 time=10.974 ms
wrong total length 96 instead of 123
--- 8.8.8.8 ping statistics ---
2 packets transmitted, 2 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 10.822/10.898/10.974/0.076 ms
´´´
Please try 1.1.1.1 instead of 8.8.8.8 as it seems 1.1.1.1 still responds to larger packets...
I do believe though that the result might actually be correct, but with less than 2 cell quanta in the plot that is just that a believe/hope that should be confirmed...
Same thing with 1.1.1.1
File is same size than with 8.8.8.8 : 8 MB
Here it is : https://filetransfer.io/data-package/kq1AWL41#link
So switching from median to truncated_mean (robust_mean in the code) we get*:
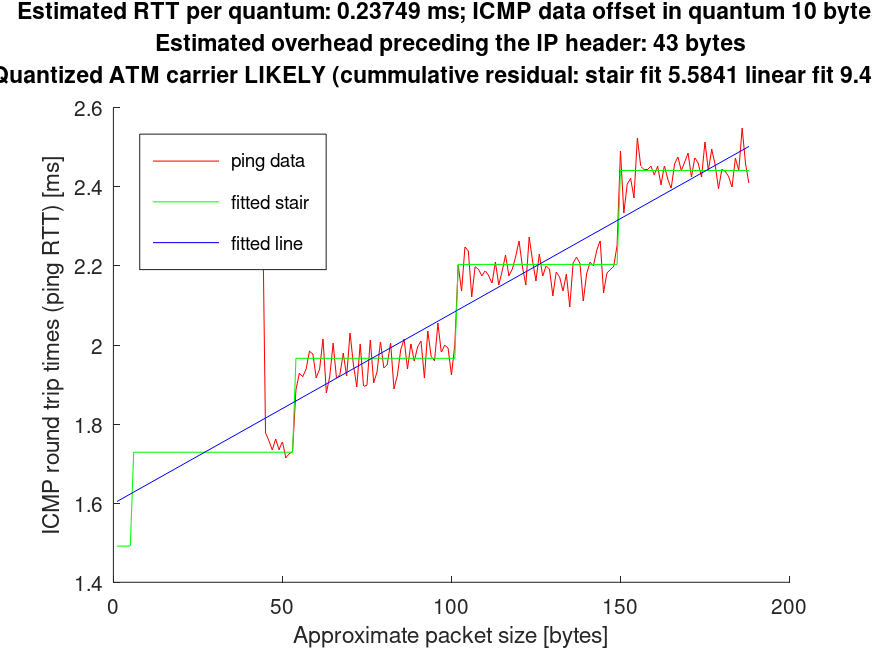
Now we see at least the expected number of samples. However the number 43 is completely new to me, I would recommend sticking to the 44 you have right now.
*) Probably required due to the level of noise in the data...
1 Like
Got it !
Thanks again for your time and analysis.
Have a great day ![]()