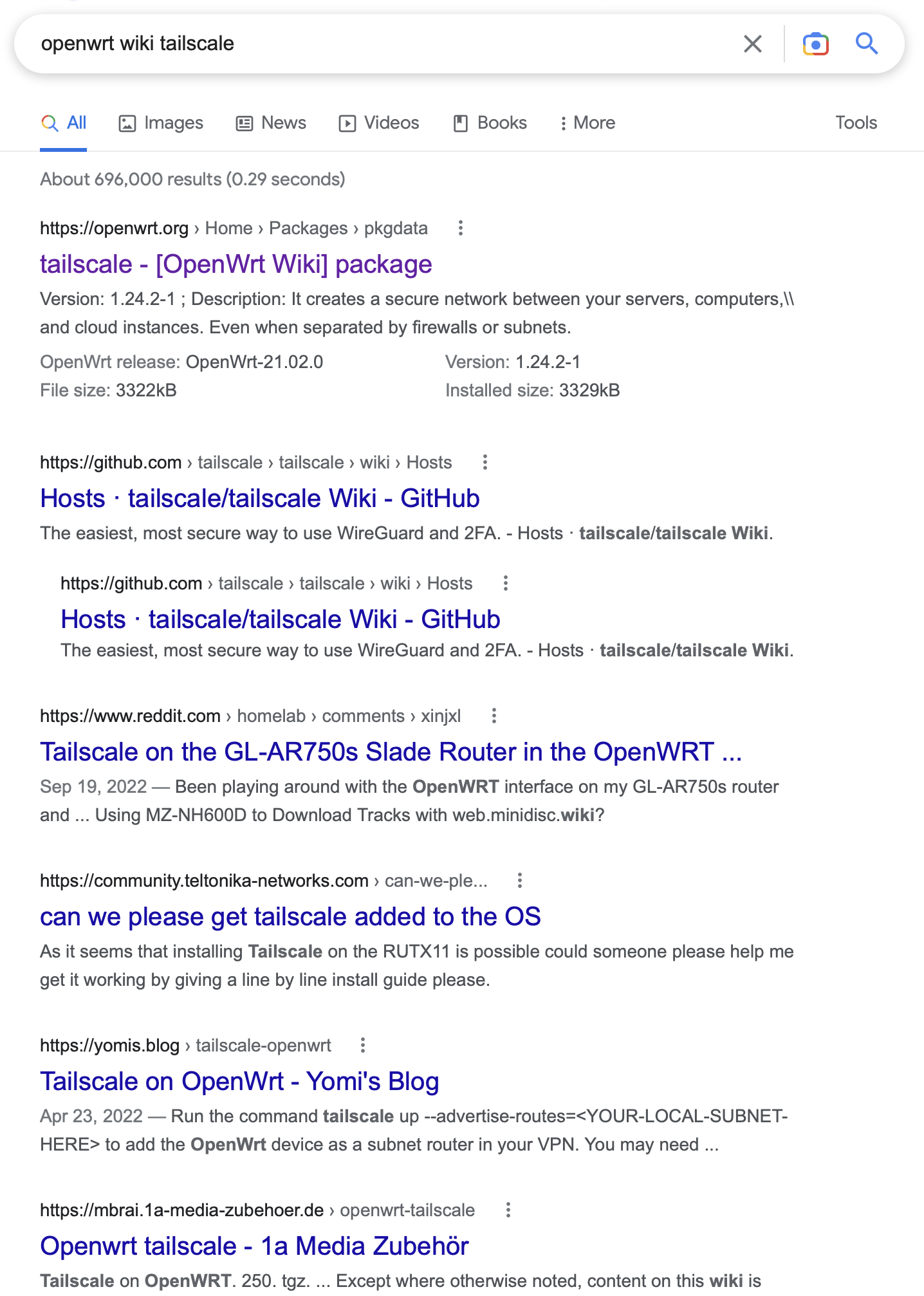
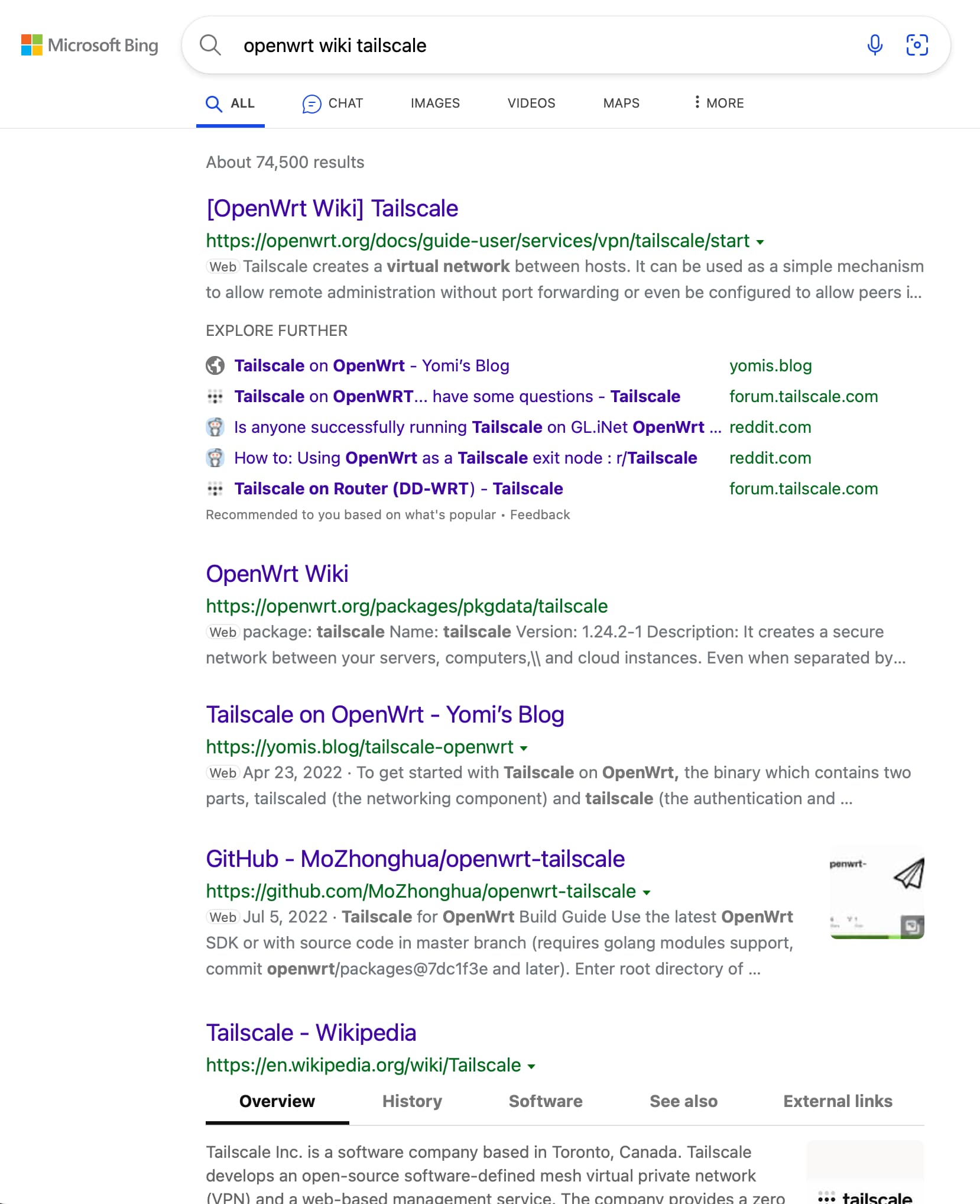
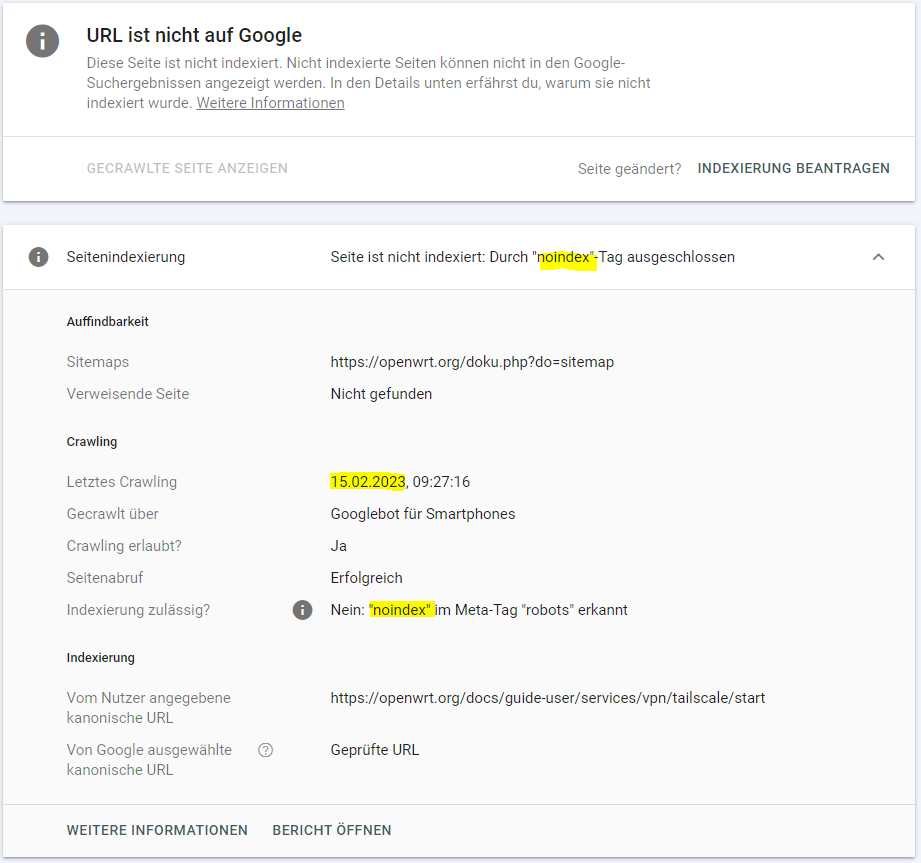
This seems like a disservice to new users who are likely using Google instead of wiki search. Does anyone know if this is intentional or the background on this? If it's not intentional, who can remove these disallow lines to get our content indexable?
$ ./robots /tmp/robots.txt https://openwrt.org/docs/guide-user/services/vpn/tailscale/start 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)'
user-agent 'https://openwrt.org/docs/guide-user/services/vpn/tailscale/start' with URI 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)': DISALLOWED
$ ./robots /tmp/robots.txt https://openwrt.org/docs/guide-user/services/vpn/tailscale/start 'Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Googlebot/2.1; +http://www.google.com/bot.html) Chrome/110.0.5481.177 Safari/537.36'
user-agent 'https://openwrt.org/docs/guide-user/services/vpn/tailscale/start' with URI 'Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Googlebot/2.1; +http://www.google.com/bot.html) Chrome/110.0.5481.177 Safari/537.36': DISALLOWED
$ ./robots /tmp/robots.txt https://openwrt.org/docs/guide-user/services/vpn/tailscale/start 'Googlebot/2.1 (+http://www.google.com/bot.html)'
user-agent 'https://openwrt.org/docs/guide-user/services/vpn/tailscale/start' with URI 'Googlebot/2.1 (+http://www.google.com/bot.html)': DISALLOWED
This is also evidenced by the results returned for the same query against multiple search engines, which in my experience, have roughly similar results for well optimized content.
I'll dig a little deeper and get to the bottom of this but just to be clear, I'm not particularly concerned about my individual contributions here but more concerned overall in the quality of search engine relevance of documentation on the wiki. Arch Linux is one of the most well-known distributions in large part due to their excellent wiki and documentation. Everybody is doing a great job with OpenWrt and I'd love to see the work appreciated by a larger audience.
Now we recompile and rerun the offending URL, robots.txt, and User-Agent and we get:
$ ./robots /tmp/robots.txt https://openwrt.org/docs/guide-user/services/vpn/tailscale/start 'Googlebot/2.1 (+http://www.google.com/bot.html)'
Matched: /*.html
user-agent 'https://openwrt.org/docs/guide-user/services/vpn/tailscale/start' with URI 'Googlebot/2.1 (+http://www.google.com/bot.html)': DISALLOWED
If we remove the Disallow: /*.html:
user-agent 'https://openwrt.org/docs/guide-user/services/vpn/tailscale/start' with URI 'Googlebot/2.1 (+http://www.google.com/bot.html)': ALLOWED
I think this line should be removed from the robots.txt for optimal SEO. Just keep in mind that this will increase server load as google (and others) have likely not been indexing almost any pages on the wiki.
These pages are safe to cache and highly cacheable. I would update Dokuwiki's cache settings before changing the robots.txt to ensure the servers can accommodate the new load.
Looking at DokuWiki's documentation on caching, it's not entirely clear to me how to influence downstream http cache headers as these pages refer to page generation caching. It seems like this may be functionality that needs to be added by a plug-in.
Anyways, I have removed the *.html now from robots.txt
Google search console is telling me that this page has not been indexed due to the "noindex" tag, which is absolutely correct, since the page had been edited on 14.02.2023, and the crawling took place on 15.02.2023.
Thanks for taking the time to look into this tmomas. I really appreciate it.
Based on what you're seeing in the console, it does look like the meta tag is more likely to be the root cause here. I'm not sure why Disallow: /*.html matches. This also doesn't make sense to me but I can add more logging and try to figure out why.
With regards to the indexdelay option in Dokuwiki, this setting looks like it's designed to prevent vandalism and link spam from new accounts on wikis with open registration.
If you have a quick community (eg. at this wiki spam usually never lasts longer than a day) or have a closed user group you may want to lower the indexdelay option or even set it to 0 for disabling delayed indexing.
Since OpenWrt registration is closed, does it make sense to set this to 0?