Next round of tests, I hope these are useful.
Test rrul, AC_BE all default:
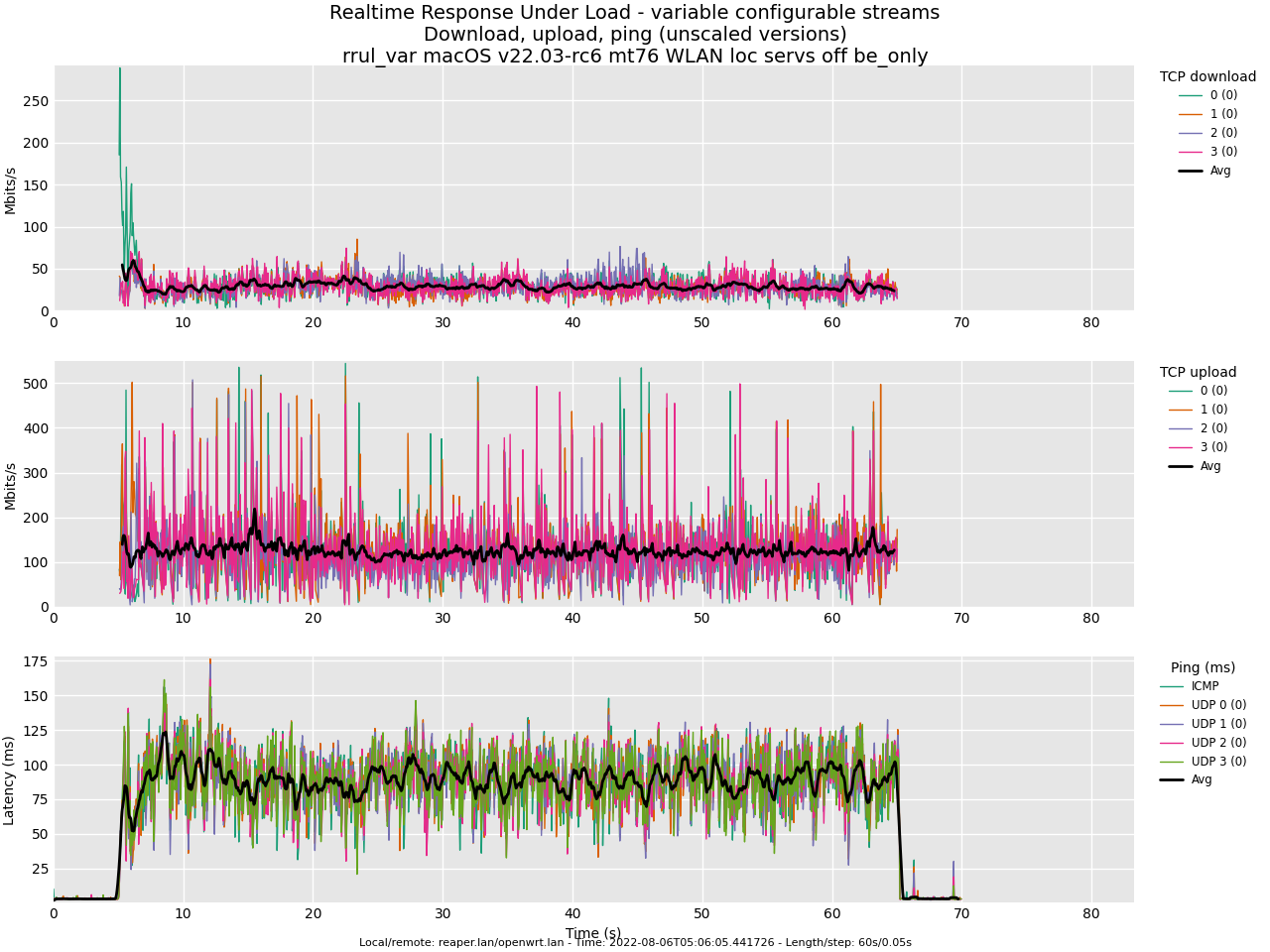
Test rrul, AC_VI all default:
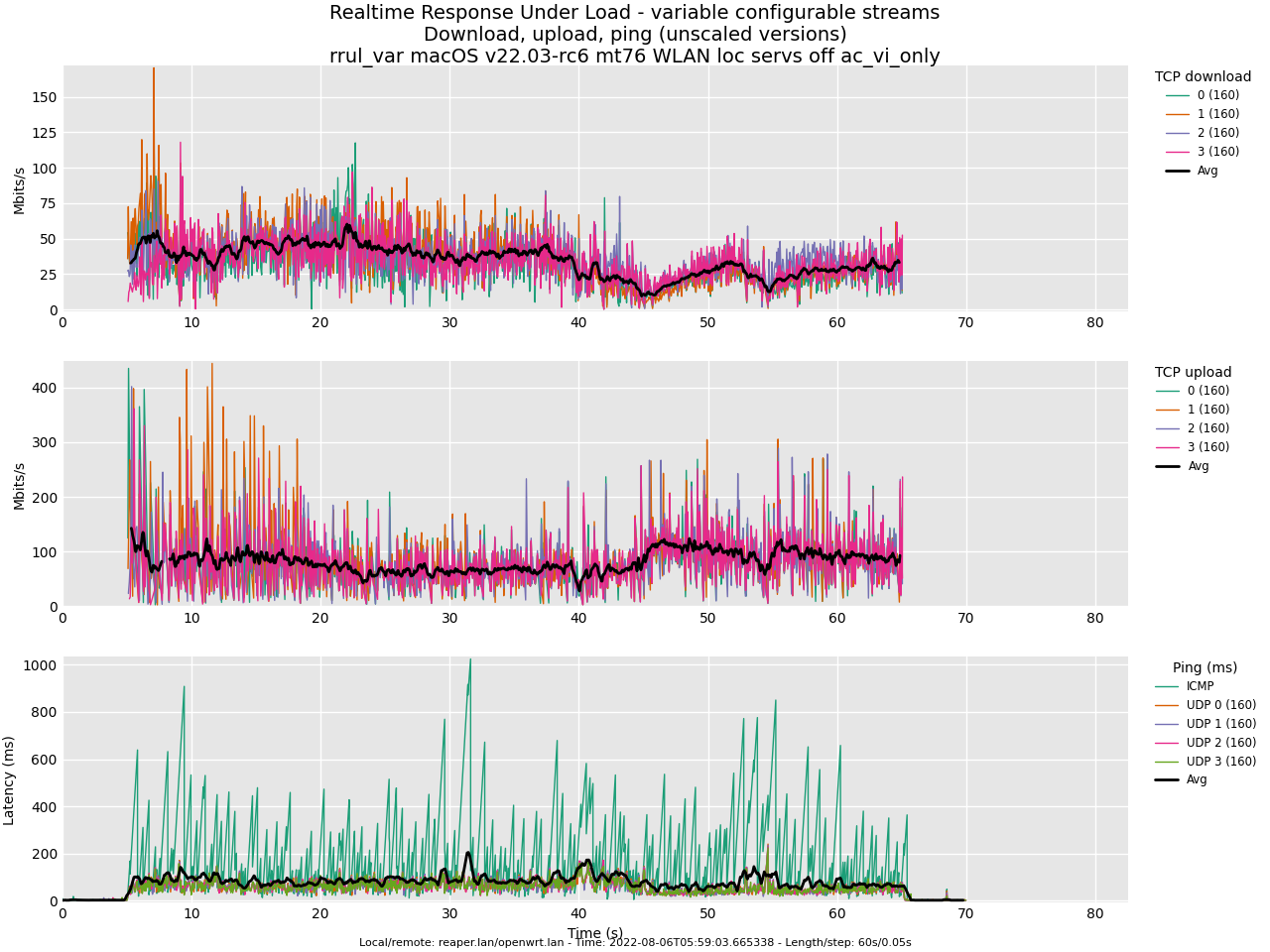
Test rrul, AC_BE and AC_VI, all default:
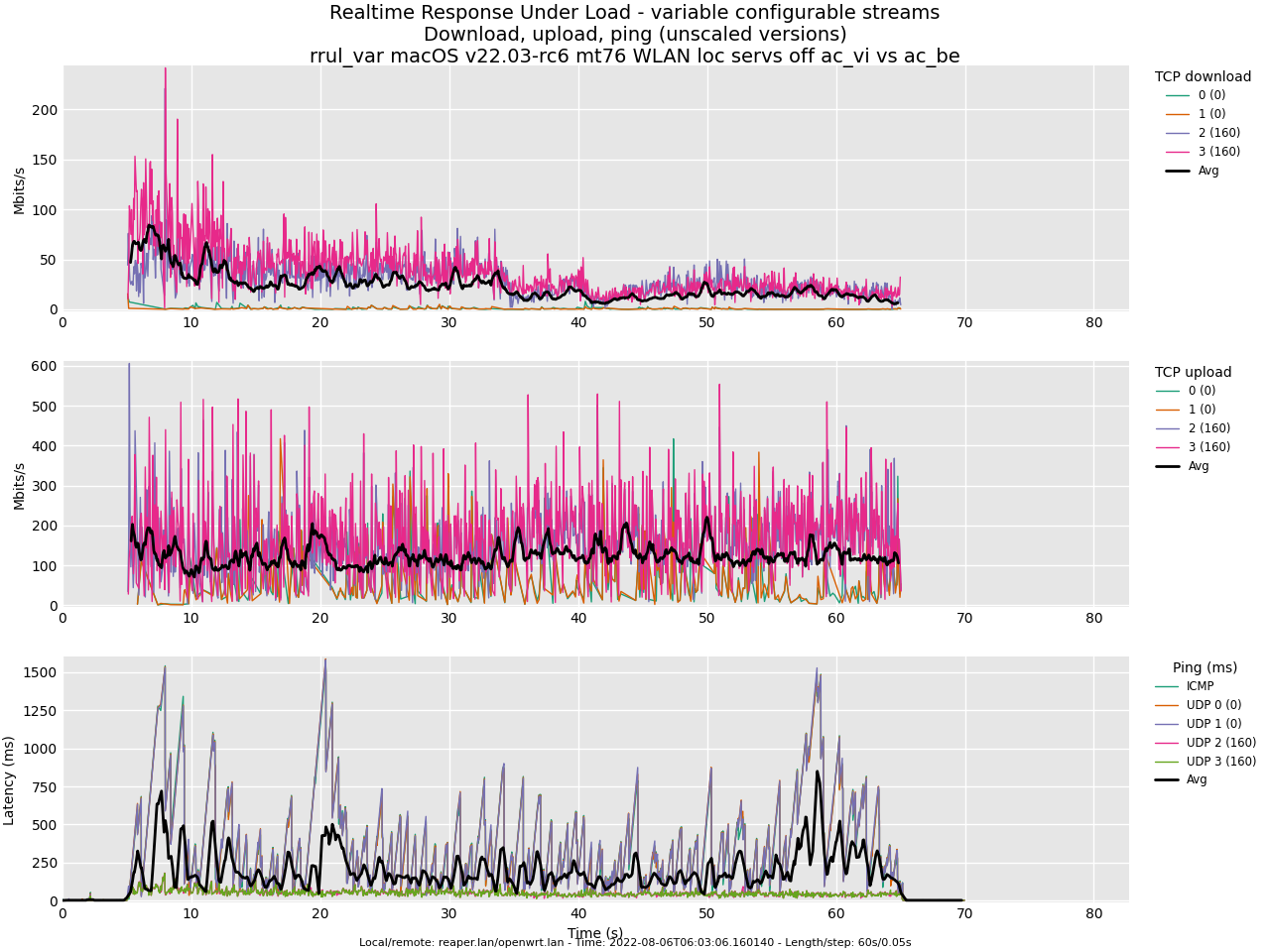
Test rrul, AC_BE and AC_VI, tx_burst=5.0:

Test rrul, AC_BE and AC_VI, tx_burst=0.5:
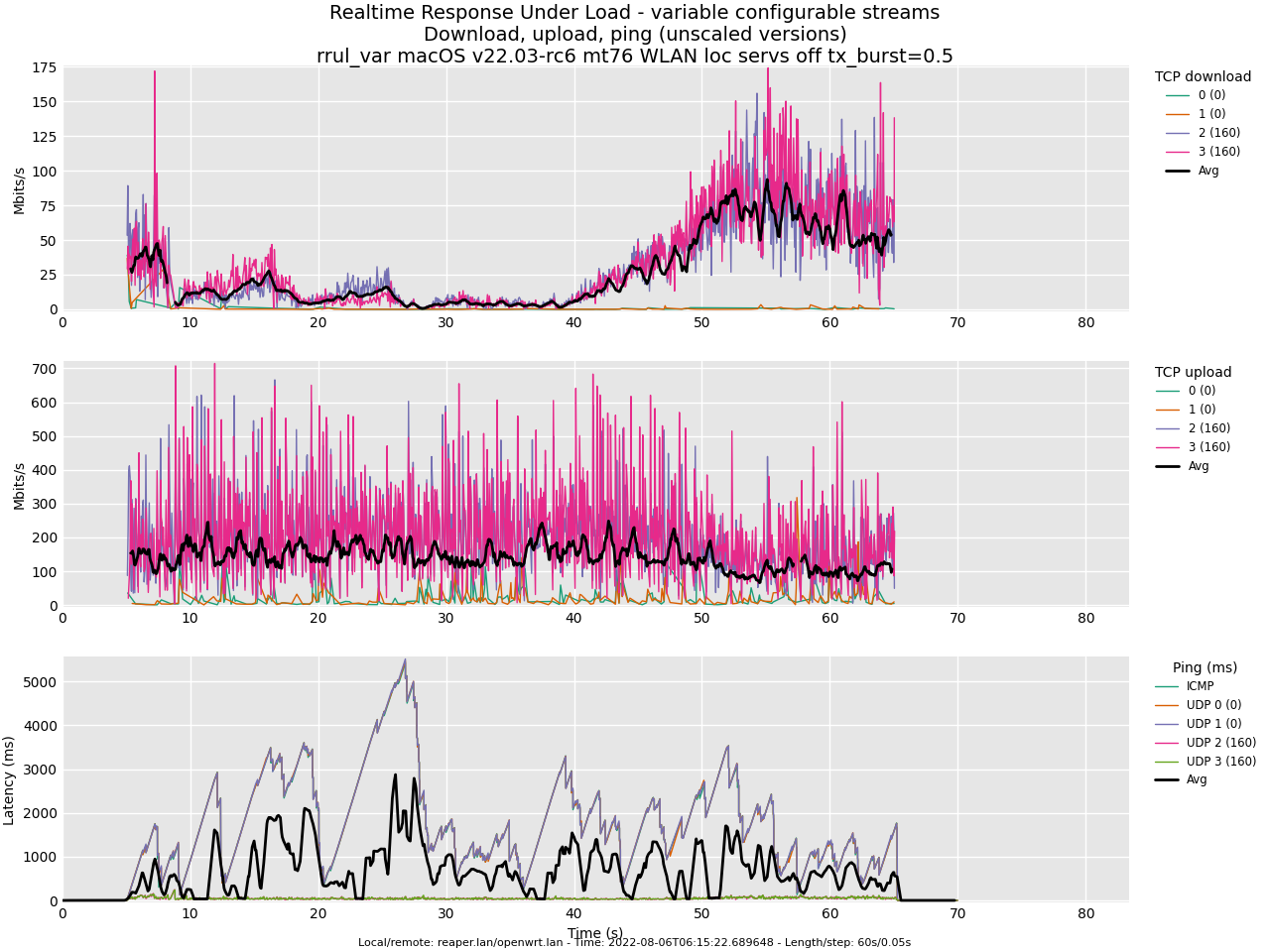
Test rrul, AC_BE and AC_VI, BE parameters equal to VI:
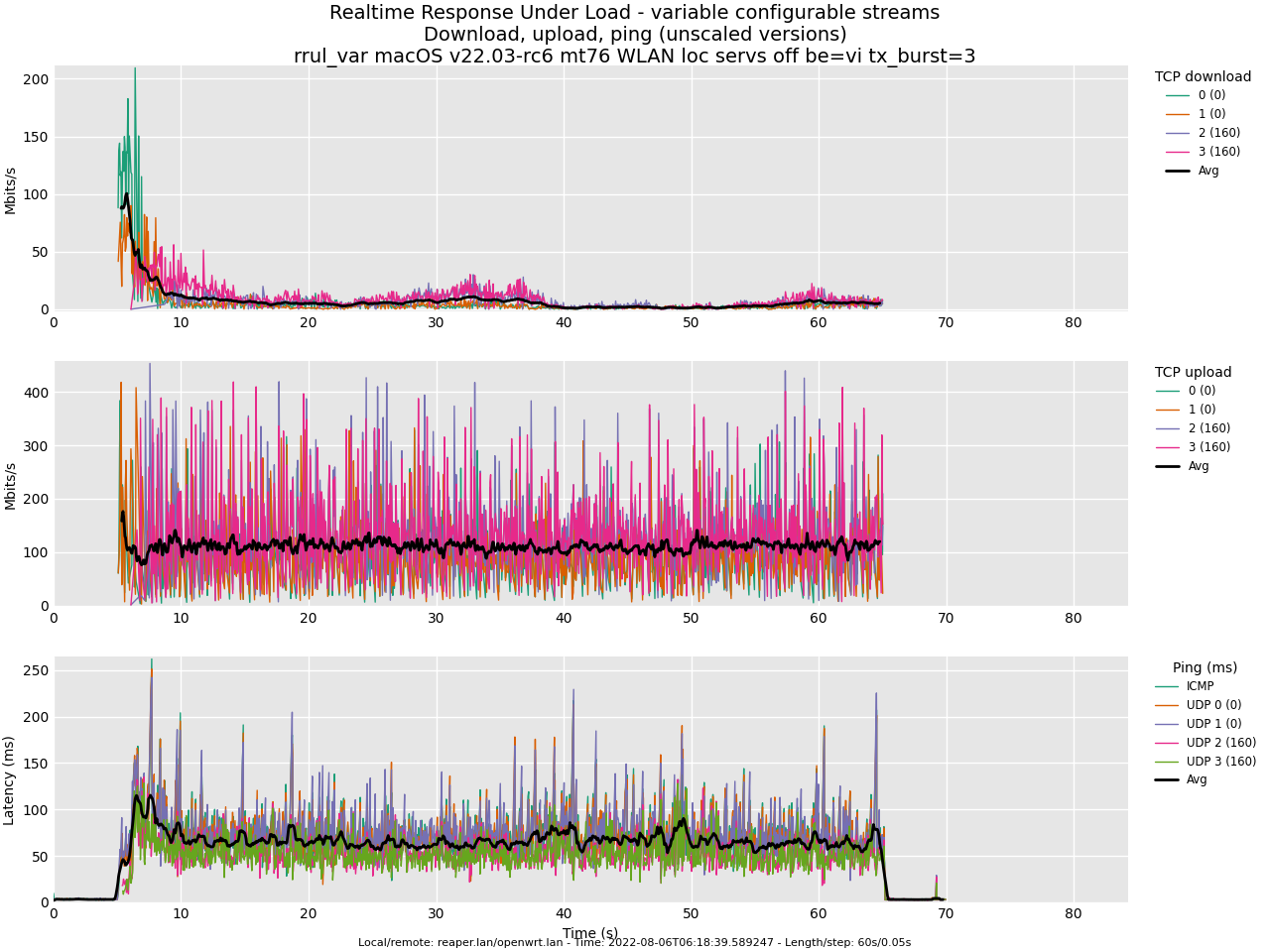
Test rrul, AC_BE and AC_VI, BE parameters equal to VI and BE TXOP=94:

- Please, find all data for this 2nd round clicking here
Updated: mistakenly used 40 as DSCP value in place of 160