Why do you think prioritizing udp in general is a good idea in the age of quic?
1 Like
Eh. When I use ping I use it to figure out how well my priority packets will behave, since I intentionally treat those other priorities roughly and make them wait. So I typically remark pings to the same priority as game packets. If they're delayed I know that games or voip will be too.
Yes, I could leave it all alone and manually set priorities with ping, but this would be a more viable option if ping weren't so stupid at the command line: -Q TOS where TOS is a decimal or hex number... no thanks. -Q CS4 or -Q AF41 would be totally fine with me.
1 Like
Windows sets CS1 on ping as best as I recall. Why make a measurement packet priority by default? Make it measure your worst case by default.
Because I specifically don't care about my worst case, I delay bulk packets up to 200ms on purpose.
or you might say that the worst-case that I care about is the worst-case of the latency sensitive traffic. I don't care that a torrent for example has to wait even several seconds.
It's just the default where there is no other rule. The default config already ships with an override for UDP port 80. By the way, the syntax gives you full control over where you want to overwrite the mark and where you want to preserve it. If you add a + everywhere (including the default values), non-zero values will not be overwritten.
I'm not at the point yet where I would call the default config sane. I'm currently more focused on giving people a reasonable set of knobs to play with.
3 Likes
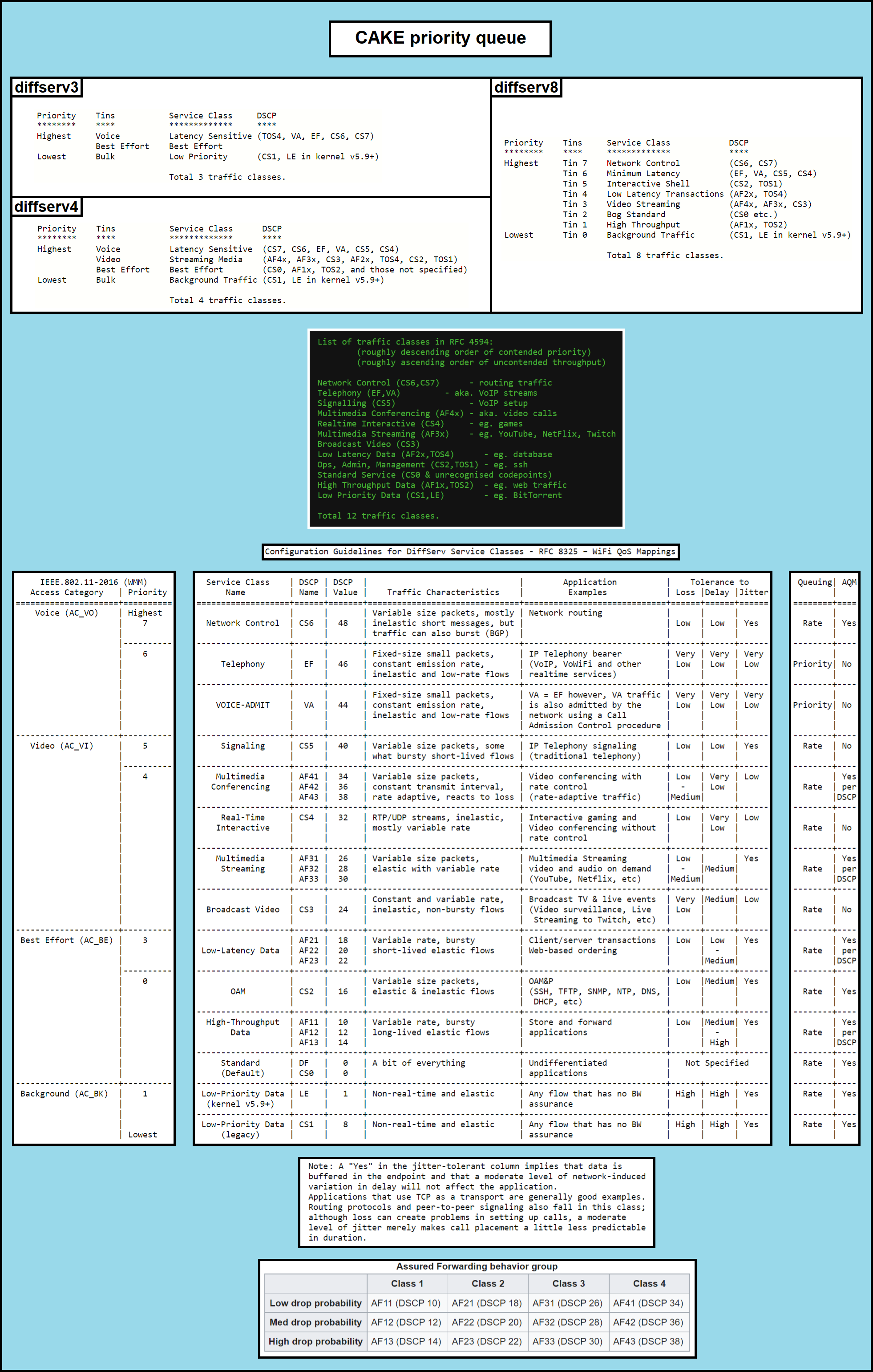
I would argue that whatever openwrt does with defaults for this package should be conservative in nature, target depriorizing certain kinds of traffic like icmp, rsync and bittorrent, try to follow the RFCs, especially for videoconferencing, and try to only put sparse traffic in the wifi VI queue, and voice, only, in the VO queue. VO in Wireless n cannot aggregate and I'd actually recommend just using the VI queue for voice also. I'd actually map CS6 out of the VO wifi queue also as it is mis-used by at least one bgp daemon and by babel.
Also a study of dscp survival nowadays across multiple ISPs would be nice. In the US at least, on comcast, nearly everything special gets remarked at CS1
In general, FQ alone is usually good enough, IMHO. The sudden resurgence of dscp here, without coherent evidence of the benefits, makes me nervous.
Aside from that, it's really not my call. Y'all have scared me enough for me to finally put this forward in the hope the internet will survive. UDPLITE (especially for ipv4)
The knobs all go to 11. And udp port 443 is going to become troublesome.
My impression of DSCP is that it was never really intended to go across the wide internet. Hence the concept of a "diffserv domain". For me that domain is "inside my house". I wash 100% of the DSCP to CS0 before it leaves towards the internet, and wash 100% of everything from the internet to CS3 in my main switch before it hits my router. The tagging in the firewall is to be used by either my switches, APs, or my router itself.
Until something like what @moeller0 was advocating (3 bits for network priority, 3 bits for application level priority) I don't think there's any other good policy.
Ah, come on that is decimal TOS which is just decimal DSCP multiplied by 4 ;)... i liked the symbolic names in the past until it dawned on me that they really are just 'marketing' as the name/dscp value clearly is decoupled from the per-hop-behaviour (and it is the latter that deserves a name).
1 Like
Oh, I do not disagree, but I can live with that as long as I can still steer ping/ICMP into any tin I want... like (DSCP 2)
ping -Q 8 -c 10 1.1.1.1
should put these packets into the besteffort tin... as long as there is no hard rule to relabel ICMP to something higher. But I also fail to see a strong rationale for moving ICMP by default into any other tin than the one used for the majority of traffic as in all likelihood this will be the latency most relevant for a "naive" user (experts can still change the configuration to suit their needs).
+1; currently many in the IETF display a pretty cavalier approach to end-user safety and quality of experience and happily "volunteer" end users into more or less well-thought-out experiments. My gut feeling is that the QUIC folks fall more on the well-thought-out end of the spectrum, but I still consider these large scale experiments without explicit user consent problematic.
Sounds like a generically useful approach.
Now do I read this correctly that this will use and evaluate the same bulk_trigger_pps and prio_max_avg_pkt_len for all aliases? I am unsure whether different value sets for different aliases might be intersting, but I could make up an example where I want torrent seeding go to BK quite quickly, while data burst from video streaming should stay in besteffort so my family does not become annoyed. Or similar, the example is contrived, but maybe allow to directly configure the two thresholds here (or make prio_boost and bulk_detect aliases themselves, so one could have different sets)? I might be over-complicating things, keeping it simple and predictable seems just as important as allowing unforeseen configurations for experts (giving enough rope to allowing shooting oneself in the foot, as they say).
Now, I am not the best person to tst/judge this as I use extremely few markings/priorities myself, as for my access speed and usage-patterns cake/fq_codel work pretty well without much additional help... (IIRC mosh and ssh are in the higher priority tin, but even VoIP just works in the besteffort tin)
But who wants to memorize decimal DSCP? Its rare to need more than 6 DSCP values, and yet there are 64 of them. To the extent there is any common behavior its defined by things like cake or WMM or my HFSC shaper script or whatnot. This in turn is documented in terms of the names... So if you sit down and say "lets probe the behavior of the voice tin of cake combined with the voice tin of wmm" suddenly you need to find and open about 4 web pages to figure out a number to put in ping... Its a disaster.
It seems to me by default ping should probe whatever users care most about. Few will care about the latency of their torrents or 30 minute long http downloads of steam games. So probing bulk seems pointless. Best effort makes sense by default for average users, but for gamers or heavy voip users or people on video calls all day long the ability to choose to probe their games or voip or video streams by default makes the most sense.
If you are installing a package like qosify you are already someone who cares about differentiation between streams. So probing the stream you care most about makes sense. Most users of ping will not be setting the dscp values but it might make sense to leave them alone if they are already set.
Well, I basically reduced the set I care to currently the CSN's (WiFi WMM is my biggest concern, since I do not want stuff ending up in AC_VI or VO by accident):
CS0/BE= 0; TOS = 0
CS1/BK = 8; TOS = 32
CS2 = 16; TOS = 64
CS3 = 24; TOS = 96
CS4 = 32; TOS = 128
CS5 = 40; TOS = 160
CS6 = 48; TOS = 192
CS7 = 56; TOS = 224
CSN -> decDSCP: 8 * N; decTOS: decDSCP * 4 = 8 * 4 * N
these are easy enough to keep in mind ;). The rest of the lot are really mostly names... but LE = 1, EF = 46 might be okay, but I genuinely do not care for the AFs, as far as I am concerned AF DSCPs should be returned to the pool (but DSCPs are never really taken from the pool so all is good) ;).
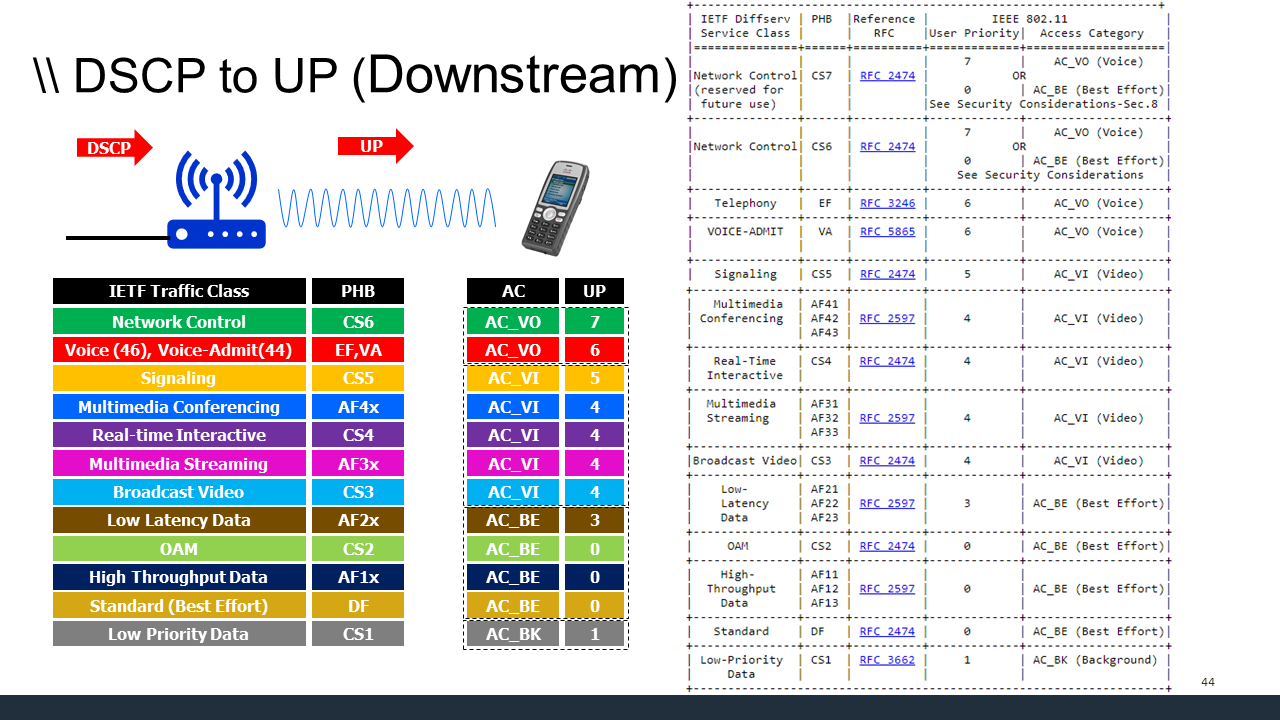
Why? Both in default WMM and cake diffserv3/4 CS6 and CS7 all end up in the highest priority tin/AC.
So 864 = 192 -? ping -Q 192 will do the right thing ![]()
And that is why qosify offers a way to change the default. I agree that without knowing much about a specific user leaving ICMP alone (+CS0) seems a decent approach, especially given that DSCPs themselves carry no reliable information about relative priorities.
The problem is, that even if you use something like +CS5 (to allow users to still use the -Q option to steer ping to any other DSCP) users will not be able to select BE/CS0 anymore, while defaulting to +BE allows access to all other DSCPs. But I get your point I believe, one size does not fit all and hence making it configurable is good engineering. And no default will be perfect for all situations.
I found this, maybe it will help you:
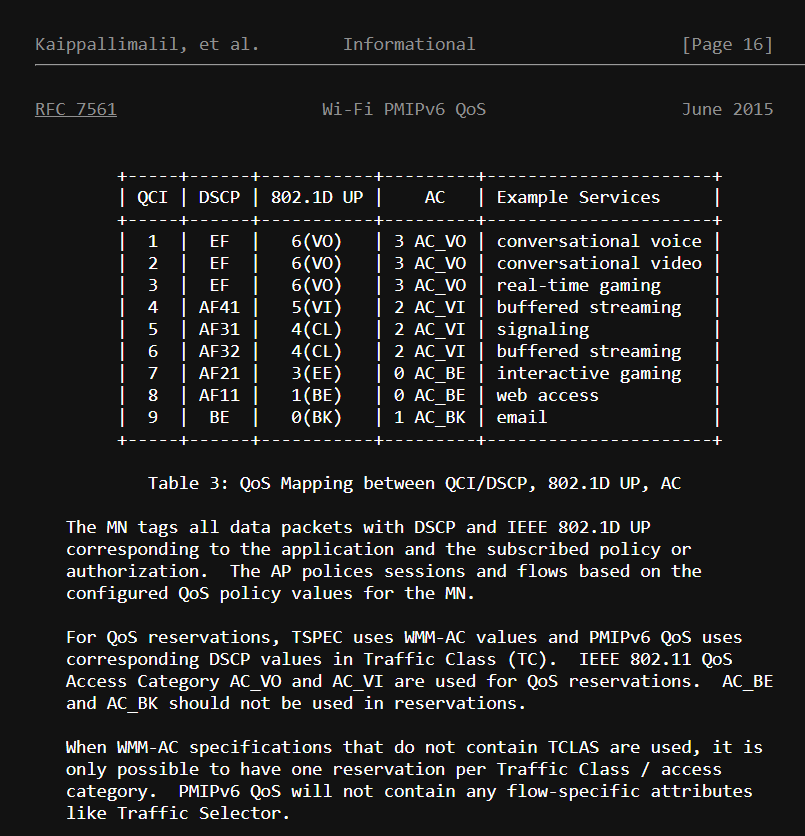
7 Likes
will all this values CS*, AF*, AC*, EF an so on work with a tp-link cheap easy smart switch (TL-SG105E for example) from manual i read:
DSCP/802.1P Based
DSCP priority determines the priority of packets based on the ToS (Type of Service) field
in their IP header. RFC 2474 re-defines the ToS field in the IP packet header as DS field.
The first six bits of the DS field is used to represent DSCP priority. The DSCP values are
from 0 to 63. The IP packets are mapped to 4 priority levels based on the DSCP value
(Lowest=0-15; Normal=16-31; Medium=32-47; Highest=48-63).
In this mode, the switch prioritizes packets with IP header based on DSCP priority first.
Then, the switch prioritizes packets with VLAN tag but without IP header based on the PRI
field. Finally, the switch prioritizes packets without VLAN tag or IP header based on port
priority.
if so would it be worth to turn on this while using Qosify?
Thanks! The problem with all of that is, that currently one can not rely on incoming DSCPs to actually mean anything specific (unless on has a contract with all ASs along a pass). Any party is free and permitted to essentially re-set the DSCP bits to basically any value. This is why RFCs typically describe a named per-hop-behaviour and then recommend a specific bit-pattern to be used, but allow each Diffserv-domain to use any bit pattern they like. The consequence of that is that DSCPS reaching a leaf network are highly dubious. Studies show that especially the three high bits are prone to be changed (which essentially means any DSCP that is supposed to survive end-2-end, better leaves these bits at zero, which is exactly what LE does (decimal DSCP value 1)).
Now that is ingress, but what about egress? In the leaf network one surely can configure the schedulers/shapes to honor DSCP values in accordance with RFC, and that is what cake mainly does, as at least some application self-mark packets in accordance with RFCs. But honestly in a leaf network all that matters is internal consistency so DSCP values are essentially variables not constants.... (with WiFI's WMM throwing a spanner into the works, WiFi DSCP to AC mapping can in be configured, but no cheap wifi router I know off exposes a simple way to configure it*).
In windows all of this is moot, as one can easily configure any DSCP on an application by application basis, but for linux and macos that is considerably trickier as the OS does not have a syste of forcing a specufic DSCP on all packets of a given application, so the easiest way is to see which DSCP an application uses (a few tools like ping and irtt actually allow to configure the DSCP from the command line, but these are typically not the applications that would need it the most (torrent clients, I am looking at you)).
*) Sure you can build your own OpenWrt with a different version of hostapd that allows to set qos_maps, but you need to build and patch your own and you need to get these configured outside of UCI, doable but not simple or convenient.
1 Like
This smells like strict priority/precedence. Which is great in that it is very predictable (lower priority traffic will only be transmitted if no higher priority packets could be serviced). The catch is without admission control on the higher priorities, lower priority tiers can be completely starved; which can be annoying, especially if one realizes that by default basically all/most packets will use DSCP0 and that ends up in the lowest priority level...
So in short, whether using that or not is a good thing really depends on your local traffic. Say, if you have relatively little high priority traffic (like only VoIP) prioritizing that in the switch seems reasonable (albeit something I would only resort to if I would observe VoIP problems in the first place). But you should take measures that mis-marked (by accident of bad faith) traffic will not starve the rest of your network...
So while I am fan of precedence due to its simplicity and unforgiveness I think a priority system should by default make sure that capacity-share scales inversely with priority (which cake does, but your switch apparently does not).
1 Like
didn't find any other info on this, it's just an on/off flag in the switch.. pretty sure you are correct ![]() dirty cheap switch with vlans i'm already happy with that.. will follow your suggestion and see what happends if give prioroty only to some gaming packets.. thanks.
dirty cheap switch with vlans i'm already happy with that.. will follow your suggestion and see what happends if give prioroty only to some gaming packets.. thanks.
The TPlink switches at least use wrr (not drr) last I looked. So it's not possible to starve anything. Typically there is an exponential weights, something like 1,2,4,8 or 1,4,16,64
I think it mentions this somewhere in the admin manual.
It isn't explicit in the more recent manuals but this older manual mentions the WRR algorithm with weights 1,2,4,8 https://static.tp-link.com/res/down/doc/TL-SG108E_V2_UG.pdf
2 Likes
Just a heads-up for any one on VM in the UK overhead should be set to 8 docsis 3.1
" option options "overhead 8"