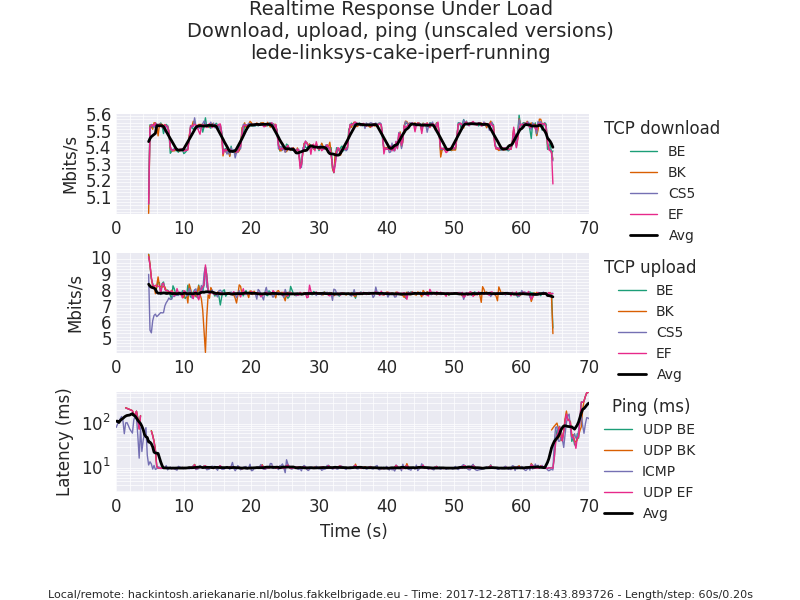
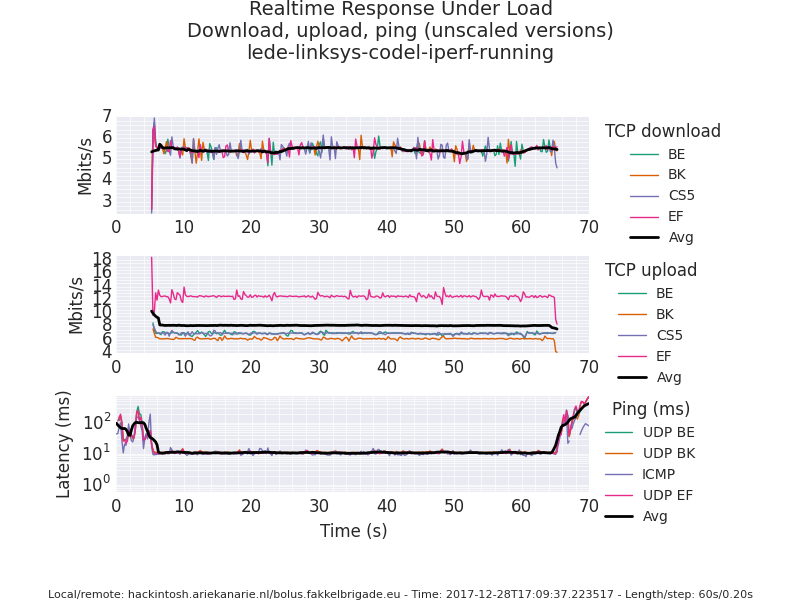
I'm having problems getting SQM to work properly with many downstreams. The downstreams can be a steam download, or windows update. But for testing I use 16 iperf3 downstreams from a remote server to a home server.
While iperf3 runs, pings for clients on my network can vary wildly, from as low as 10ms there are gradual spikes to 80-100ms before easing back down again. This is both for ICMP pings and UDP packets in games (e.g.: net_graph 5 in Team Fortress 2 while connected to a gameserver in the same country)
At first I thought this was my docsis connection being too full, but even shaping to just 20% of my actual cable speeds shows the same behavior (with bigger/longer ping spikes).
The thing that's most puzzling to me is that when I start a 'flent' test during these iperf3 downstreams (saturating the connection even more) pings drop to 10ms (for all clients on my network) as soon as flent starts uploading/downloading. They're rock solid for the 60s the flent test takes and immediately spike back up when flent finishes.
I've tried both fq_codel and cake, cake in besteffort, diffserv, dual and ingress modes (and various combinations), but the behavior stays the same: Many downstreams cause the ping to spike, until a flent test is run. I've attached two pictures that show the flent results while iperf3 is running. During the 10s "quiet" period at the start of flent the ping is high, during the test it's perfectly fine, and once the test is over the ping goes back up again.
Does anyone know what's causing this and if it's fixable?
I vaguely remember realtek or intel nics (and wifi?) have some sort of power saving facility that caused latency issues. Poke around driver settings and see if you can disable some power saving features and retest.
This may well be some docsis behavior. Cable modems do time division multiplexing I think and so when only a little traffic is ready to go they may buffer until enough traffic is available to make it worthwhile to turn on the radio and request a time slot and send the data.
When you are heavy using the connection, the radio stays on with a dedicated time slot for the duration.
This is a guess. But it's consistent with the behavior you're seeing.
I've done some more testing and it's unrelated to my SQM settings. I've ruled out my LEDE version and router by using an Edgerouter ER-X with a different LEDE version and with stock Ubiquiti firmware (using Smart Queue QOS / fq_codel and a custom-compile cake)
It does seem to be some sort of DOCSIS or cable modem weirdness.
Sending about 300KB/s of empty UDP packets upstream improves my connection during downloads even with no SQM enabled. From 500ms of bufferbloat down to 100ms. With cake or fq_codel shaping the connection, whether it's shaping to 40Mbit down or 300Mbit down, this behavior stays the same.
If I flood my downstream with 16 iperf3 streams at 40, 100 or 300Mbit shaped (either by fq_codel+htb or cake), pings spike. As soon as I start a 300KB/s empty UDP upstream flow while the 16 stream download is running, pings drop dramatically and bufferbloat is perfectly controlled.
Ah thanks, I was wondering whether that might have bee related to issues with intel/lantiq's puma 6 docsis modem, but at least the 3925 seems to use a broadcom docsis chip; making my hypothesis obsolete.
Another question, are you testing over wifi or over a wired connection?
This probably explains why I could never get good audio on VoIP over cable. If I had just had a script to detect an audio call and send additional meaningless udp upstream I'd have been ok
So this looks like the modem is buffering upstream packets in largish batches that cause latency under load increase (due to your ICMP packets idling in the modems queue) unless the upstream rate is large enough to guarantee that the largish queue buckets are emptied often enough?
Does the DSCPs of the upstream packets make a difference?
Is the rate or the bandwidth of the "UDP pipe cleaner flow" the relevant measure?
It's not the bandwidth, but the rate of packets that seems to make the difference. Sending the same bandwidth of packets at a slower interval has worse latency. Sending empty UDP packets with hping3 at -i u100 is the sweet spot.
DSCP marking had no effect.
Interesting because 100usec is a lot faster than the 20000 usec between VOIP packets. If you figure maybe there's a buffer trigger that causes the modem to negotiate a send window after N packets are in the queue, or t usecs have passed, and N is something like say 10 then you'll get a send window every ms with hping3 -i u100 whereas with a VOIP flow you'd never hit the N limit, instead you'd hit the timeout t which evidently is something like 100ms based on your ping results, and that is 5 VOIP packets. Lots of VOIP jitter buffers really can't handle that level of jitter, and besides you really start to talk over the top of each other.
This kind of behavior makes good sense as an explanation for why my VOIP behavior was truly terrible on the local DOCSIS network, people would just refuse to talk to me on the phone at times. and I would be concerned about trying to prevent too much background traffic, little did I know that if I'd just run a flood of udp everything would have been great
EDIT: it also seems like this upstream pipe cleaner flow affects downstream latency as well, and that is consistent with the model of why it's going on. I'm not sure about the details, but I can imagine that the modem is basically completely off the network when it's not sending. It probably has a periodic poll in which it negotiates a window and sends a "keepalive" and that also triggers a receive windows. So upstream is buffering until it hears the modem come online. Forcing the modem to come online every ms by filling up its send buffer to the trigger point means that in both directions the latency drops to ~ 1ms. Since the modem knows nothing about how many packets are queued on the other end waiting to be sent to it... no amount of downstream traffic will make it connect, things have to wait for the keepalive or a send-buffer trigger.
Interesting experiment idea: run your test with hping3 -i u100 and u250 and u500 and u1000 and u5000 and u10000 etc, and see how your latency depends on the ping interval. Plot latency vs ping interval. If there's a trigger at N packets, I'd expect a linear increasing relationship. If there's also a keepalive, I'd expect it would then saturate to a fixed latency as interval goes past some threshold.
The problem has disappeared. My modem was offline for a short while this morning and when I just went to test for the problem, it was gone. Checked the modem page for any changes, can't find any.
Nothing changed on my end, but now, even without the "UDP pipe cleaner" I already get perfect bufferbloat scores.
I wonder if it has something to do with how congested the local loop cable network is. I can definitely confirm that this doesn't happen on my fiber connection.
Can you try running ping in one terminal and a series of hping3 with different wait times in another, and see how the ping time changes with hping3 interval?