I replaced our main OpenWRT router two weeks ago with an netgear r7800 and 19.07.7 openwrt. It's main purpose is connecting five office branches via strongswan and a few clients via openvpn. It also acts an wlan access point for around 20 mainly mobile devices.
Today the system rebooted and left the following kernel panic in the log file.
I use the r7800 in other smaller branches and they are running for weeks without issues.
I wonder if such kernel panics are know issues. If not what would be an good strating point to track these issues down.
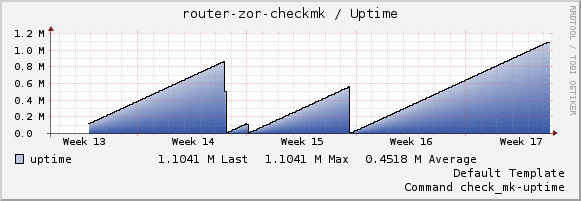
So far the router reboots around every five days. I added an check_mk client script which does not show irregularities in kontext switches or memory usage. Also i tried the ath10k-ct-smallbuffers module. But with no luck. An kern.alert does not always get logged. Today I found this one from an reboot on sunday, so at an time when no ones is at wor and the router is idling.
Sat Apr 17 14:03:24 2021 kern.alert kernel: [562221.709322] Unable to handle kernel NULL pointer dereference at virtual address 00000000
Sat Apr 17 14:03:24 2021 kern.alert kernel: [562221.709363] pgd = c0204000
Sat Apr 17 14:03:24 2021 kern.alert kernel: [562221.716608] [00000000] *pgd=00000000
19.07 w/ kernel 4.x had some reboot problems. Mine used to reboot every few days also. I haven't seen them on kernel 5.4, it may be worth trying a 21.02 or mainline build.
Thank you all for the feedback. I changed the min cpu frequency from 384MHz to 800MHz because this ws the easiest to do. Will have to wait a few days and report results here in a week.
I use the RS7800 with version 19.07 in threeother branches. These do not reboot and have an uptime of 20 and 40 days.
There are some caveats with ipq806x running at 384 MHz, on the one hand the ramp up time (longer latency than necessary, but not buggy behaviour) - on the other hand there are some intricacies with the silicon at this speed as well (and this can cause crashes). This pull request explains some of the reasoning (there are other fixes pending as part of the v5.10 kernel bump for ipq806x as well, touching L2 cache scaling and MDIO busy waits, which will improve the situation as well).
As far as 19.07.x with kernel 4.14 is concerned, there may be another issue looming on the stmmac (ethernet) driver when encountering jumbo frames (this is fixed in kernel >=4.19, but hasn't been backported as no one identified the commit fixing these).
If it is an L2 cache error as mentioned above chances are low that redirect logging to an other machine will help. Same goes for jumboframe introduced errors.
I configure all my router images via ansible scripts reading settings from netbox. Putted adding an option for log redirects on my list, but plant to wait for 21.02 stable before i switch to that.
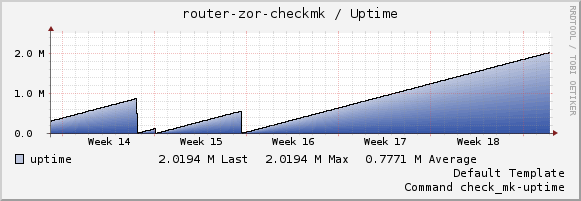
The router did not reboot the last 13 days. Before it usually rebooted every five days, one time the router had an uptime of 10 days, but it looks promising. Seems the min frequency fix did the trick.