Again - very similar, but the r7500 is an all Qualcomm design versus the NBG6816 incorporating Quantenna.
EDIT - just realized there's two versions. V1 of R7500 is Quantena... V2 is Qualcomm... my apologies. I do see where in the first post it states compatibility with both V1 and V2. Interesting.
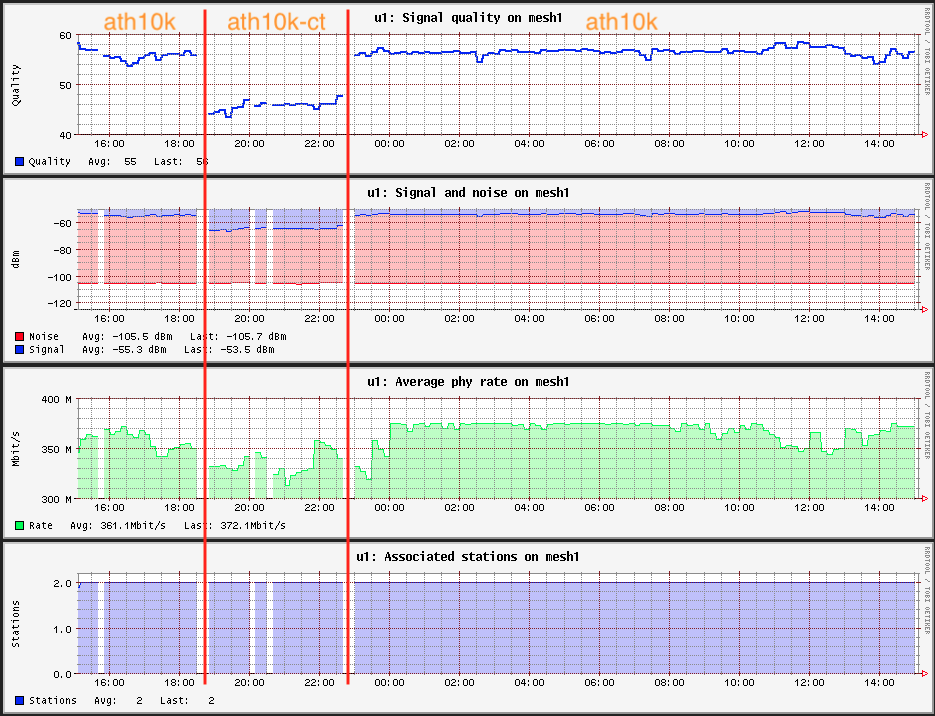
I also was under the same understanding that using ath10-ct driver is better, but never really know how's better besides what I read in some of the posts. Recently, I discovered that ath10k actually provide better performance between the mesh nodes... The metric below are from an environment that's setup exactly the same, the only change was switching from ath10k to ath10k-ct back to ath10k after realizing that I was getting better WiFi performance with the ath10k driver.
Add nssfq_codel to the SQM_CHECK_QDISCS option in file /etc/sqm/sqm.conf.
Add nss-ifb to ALL_MODULES on the last line in file /usr/lib/sqm/defaults.sh.
Configure SQM:
uci batch << EOF
set sqm.eth0.qdisc='fq_codel'
set sqm.eth0.script='nss.qos'
set sqm.eth0.interface='eth0'
set sqm.eth0.linklayer='ethernet'
set sqm.eth0.overhead=18
set sqm.eth0.tcMPU=64
set sqm.eth0.upload=110000
set sqm.eth0.download=990000
set sqm.eth0.debug_logging=0
set sqm.eth0.verbosity=5
set sqm.eth0.enabled=1
EOF
uci commit sqm
Reload SQM:
service sqm reload
Error messages?
When reloading SQM, some error messages are displayed which I lack to understand:
SQM: Starting SQM script: nss.qos on eth0, in: 990000 Kbps, out: 110000 Kbps
SQM: ERROR: cmd_wrapper: tc: FAILURE (2): /sbin/tc filter add dev eth0 parent 1:0 protocol ip prio 0 u32 match ip protocol 1 0xff flowid 1:13
SQM: ERROR: cmd_wrapper: tc: LAST ERROR: RTNETLINK answers: Not supported
We have an error talking to the kernel
SQM: ERROR: cmd_wrapper: tc: FAILURE (2): /sbin/tc filter add dev eth0 parent 1:0 protocol ipv6 prio 1 u32 match ip protocol 1 0xff flowid 1:13
SQM: ERROR: cmd_wrapper: tc: LAST ERROR: RTNETLINK answers: Not supported
We have an error talking to the kernel
SQM: WARNING: sqm_start_default: nss.qos lacks an egress() function
SQM: nss.qos was started on eth0 successfully
Anyone able to properly interpret them? Are they harmless?
NSS-accelerated SQM seems to work just fine though (1 GBit/s down, 100Mbit/s up, DOCSIS 3.1):
On my case non ct works better aswell but I noticed it because I have lot of smart relays and I saw in the log of openwrt that those relays where continuosly reconnecting to the wifi untill I switched to non ct and then wifi is working rock solid for my r7800
Salim,
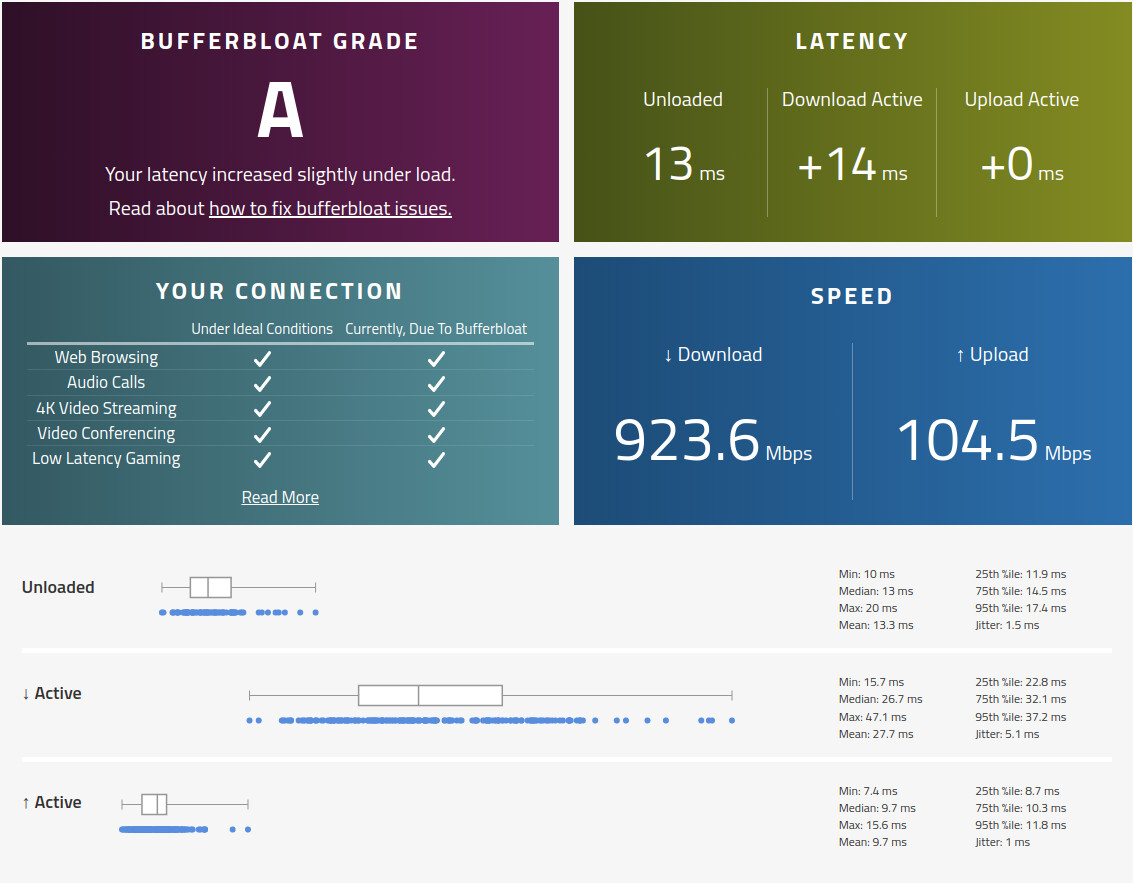
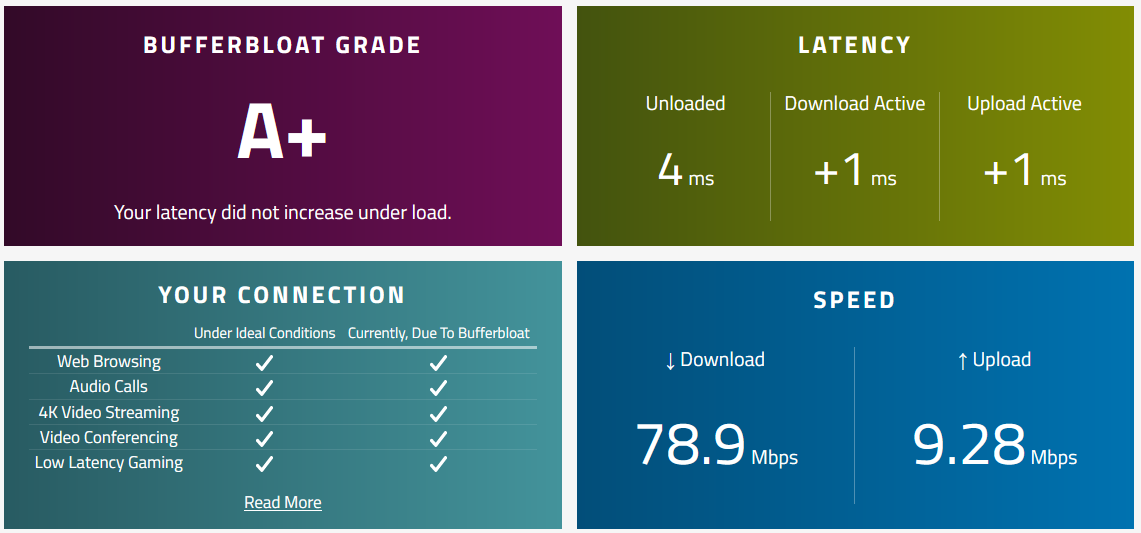
I just tried this and it made a change... My 'low latency gaming' went from exclamation point to none and my grade went from A to A+, but my speed decreased by 10x!?!
Before
The active latency went down, but the throughput dropped a lot. This does not seem to be an improvement.
I am on ATT fiber (1G)
I'm running: OpenWrt 21.02-SNAPSHOT r16461+16-5beaa75d94 / LuCI openwrt-21.02 branch git-22.007.66044-dd9390c
which is the archive called: R7800-20220109-Stable2012NSS-sysupgrade.bin
I followed the recipe but did not reboot. Is a reboot necessary? The nss_codel did not initially show up in luci:
I had to first select the setup script: nss.qos under 'Queue Discipline' and fq_codel
then under Basic Settings "enable SQM this instance" then "Save and Apply".
I am wondering if I used the correct interface, though. My WAN is on eth0.2
Is SQM for the LAN or the WAN? I followed your recipe line for line.
If I re-flash the firmware will it revert?
Keith
If you copied Salim-b's configuration exactly then that's very likely your problem, if I'm reading it right, he's very likely on 100/10Mbps connection and has the upstream and downstream rates set accordingly, which would certainly explain your results.
Given you are on a gigabit connection, you probably want to add another 0 to the values, although you'll probably need a bit of experimentation to find what works best for you ( I've been looking at values between 8800000 and 9600000 for my gig docsis connection)
eth0 is, as far as I know, correct howver I'm not sure tcMPU is. It shows under advance in Luci with a comment that they are only required if the MTU is > 1500 which I don't think it would be. It's entirely possible that removing it will make absolutely no difference as the NSS script probably doesn't use it anyway...
In that case my settings are totally wrong and you should probably just ignore me
I've now corrected my settings, which has improved my test results. tc qdisc looks like a good way to check that the upstream/downstream settings are correct, as they are reported in Mbps (Useful if, like me, you are challenged by too many zeros) as well as confirming nss is actually being used for SQL
If tc shows two each of nsstlb and nssfq_codel then, with the original config, it should be giving good results without any real impact to throughput...
I am a little bit confused here. On step 3, we added nssfq_codel to the list, but from the UI, we selected fq_codel as the Queue Discipline. Shouldn't we select nssfq_codel instead? The nss.qos.help also stated to select fq_codel
HW-accelerated traffic shaping support. Select fq_codel as discipline and nss.qos as setup script.
If that's the case, what's the point of adding nssfq_codel to the list?
In theory it shouldn't matter what's selected via the UI as nssfq_codel is hardcoded in the nss.qos script, fq_codel will therefore give you nssfq_codel while cake gives you a warning it's not supported and that it's going to fall back to nssfq_codel
In practice, it looks like the script always works if 'fq_codel' is selected and always fails if cake is selected irrespective of whether nssfq_codel has been added to sqm.conf or not...
It seems it is related to pppoe. I tested ipv4, ipv6 and nat with ipv4. There the acceleration works. I also disabled the nss qos and the iptables mangle table. So for me looks related to pppoe. The module is loaded. So how can I debug it?
The ECM_dump shows for not working connections:
conns.conn.10646.front_end_v4.ported.can_accel=1
conns.conn.10646.front_end_v4.ported.accel_mode=-2
conns.conn.10646.classifiers.default.pr.accel=wanted