it appears that the machine hosting the forum and nameserver for openwrt.org became inaccessible some time between sunday, 6th and monday 7th. We tried to contact the admin about the problem but didn't receive a direct response so far. According to a statement made by Zoltan, a hardware fault is the probable cause for the outage.
Since the server didn't come back online within the last ten hours and since we didn't hear about any ETA on repairs yet, we decided to take the matter to the SPI Inc., the non profit organization handling the openwrt.org domain, and asked them to redelegate the zone to the Digital Ocean name servers which are also already hosting the lede-project.org domain.
At this point in time we unfortunately cannot give any estimation on when these issues will be sorted out as we're still waiting for a positive confirmation from SPI. Depending on the reaction time of SPI's registrar and the time it takes for the DNS changes to propagate it could happen anytime within the next 12 to 96 hours.
It is also possible that the server hosting the authoritative DNS is getting online sooner, intermittently fixing DNS resolving.
Update Tuesday, May 8th 07:00 CEST
The authoritative name servers have been changed two hours ago and should slowly propagate down the DNS chain now.
If you find yourself to be unable to reach any of the openwrt.org hosts, e.g. http://downloads.openwrt.org or http://archive.openwrt.org and happen to run an OpenWrt or LEDE router, you can temporarily configure it to use the DigitalOcean DNS servers to resolve *.openwrt.org addresses:
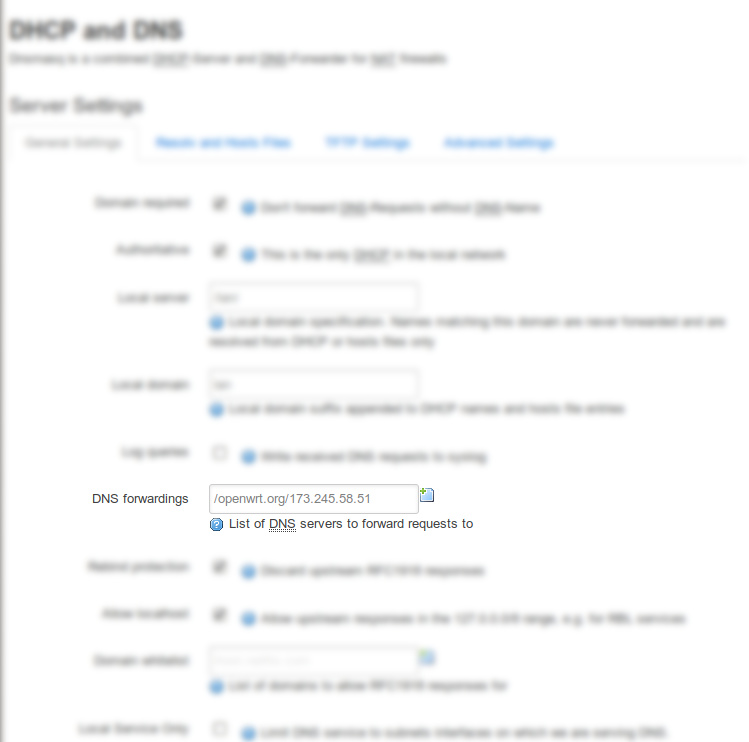
Log into LuCI
Navigate to Network --> DHCP and DNS
Enter the following value into the DNS forwardings field: /openwrt.org/173.245.58.51
If you happen to run dnsmasq on non-OpenWrt systems or if you prefer to use the native configuration, you can add server=/openwrt.org/173.245.58.51 to /etc/dnsmasq.conf as well.
You know you can speed up the process considerably if you still have access to the previously delegated slvaes, and can reconfigure them to pull the zone from the new master? Even only one of them would help at this point, when all the other servers are "gone" (master down and slaves failing). It would bring openwrt.org back online immediately without the need to wait for delegation updates and propgation delays