Would you mind providing an outline summary of how it works? I personally liked the simplicity of @Bndwdthseekr's bash script and the overall concept in the ICMP approach written by @dlakelan, albeit the latter seemed a little complicated.
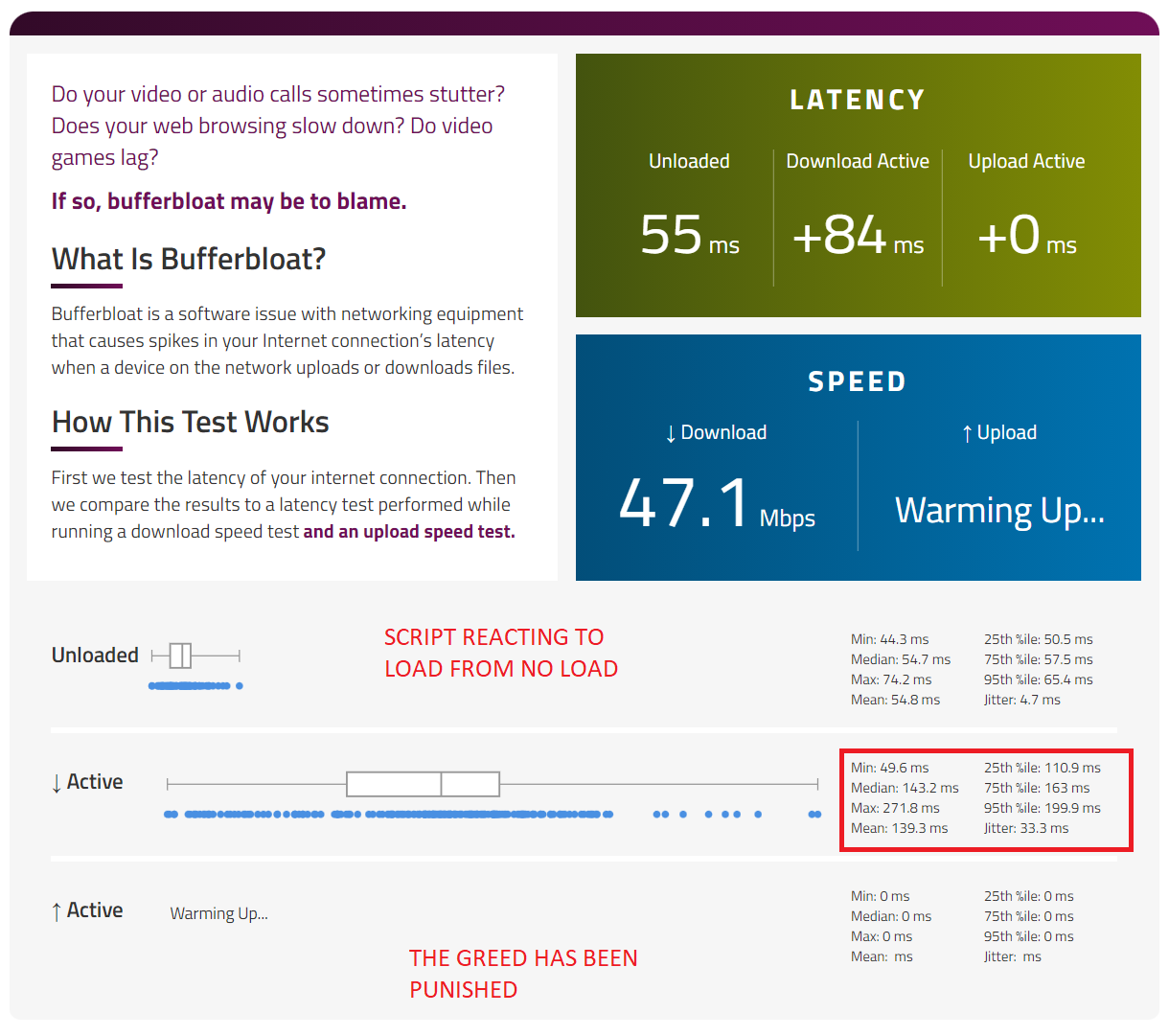
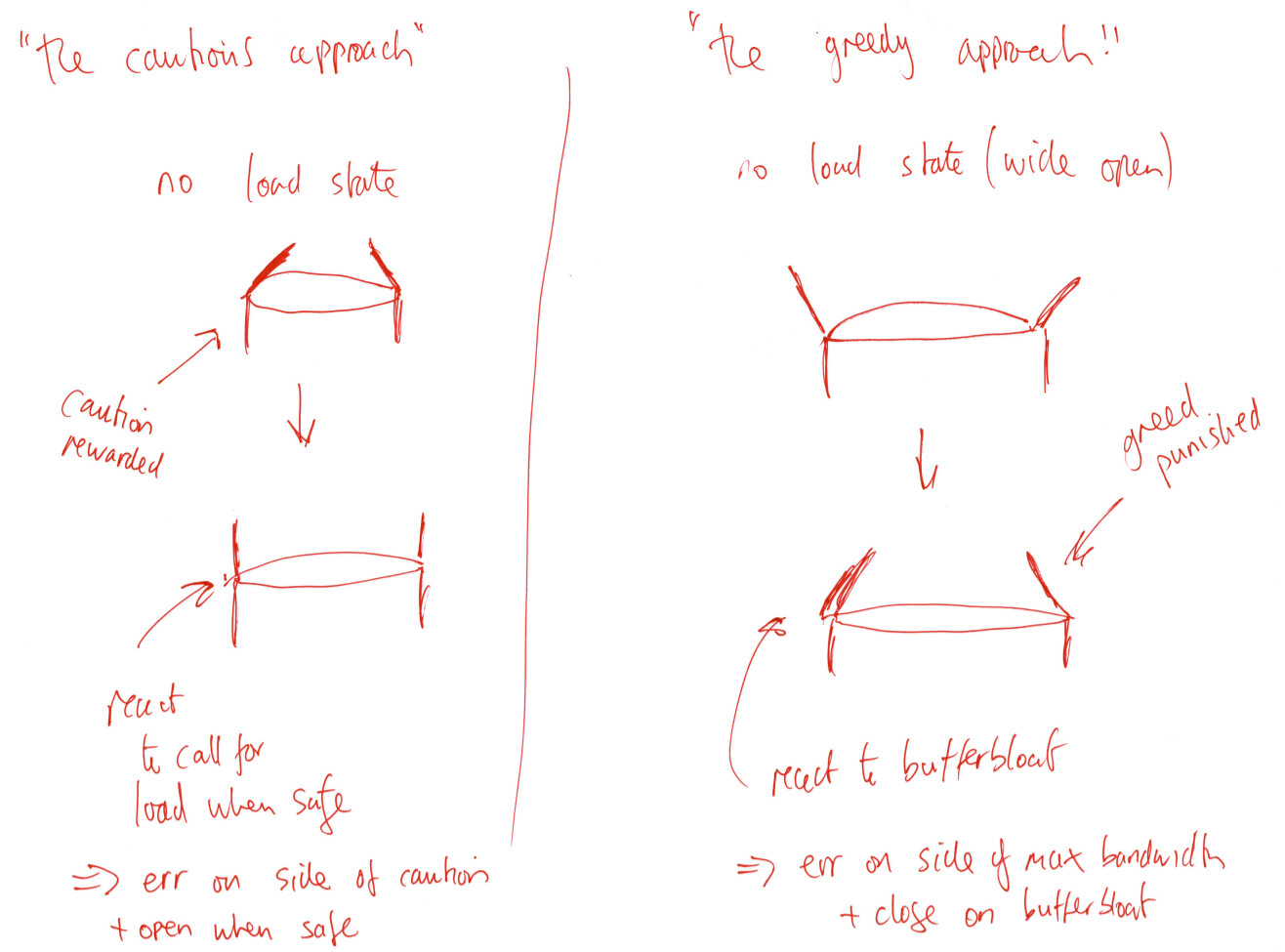
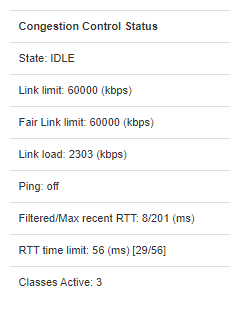
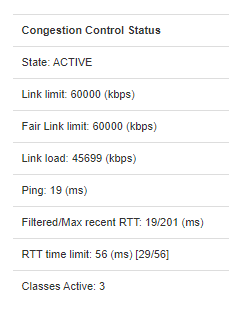
I don't think I really care about inconsistent ICMP performance because 8.8.8.8 inconsistency is surely peanuts compared to the huge bufferbloat issues I see on my LTE connection. I am not looking for perfection, just something that works to a sufficient degree. I don't mind some bufferbloat creeping in, so long as pings stay below 100ms from a baseline of 50ms. Since then in my experience everything will work fine. The problem comes when pings start to shoot up to more like 500ms and beyond, which is what happens when I disable SQM entirely.
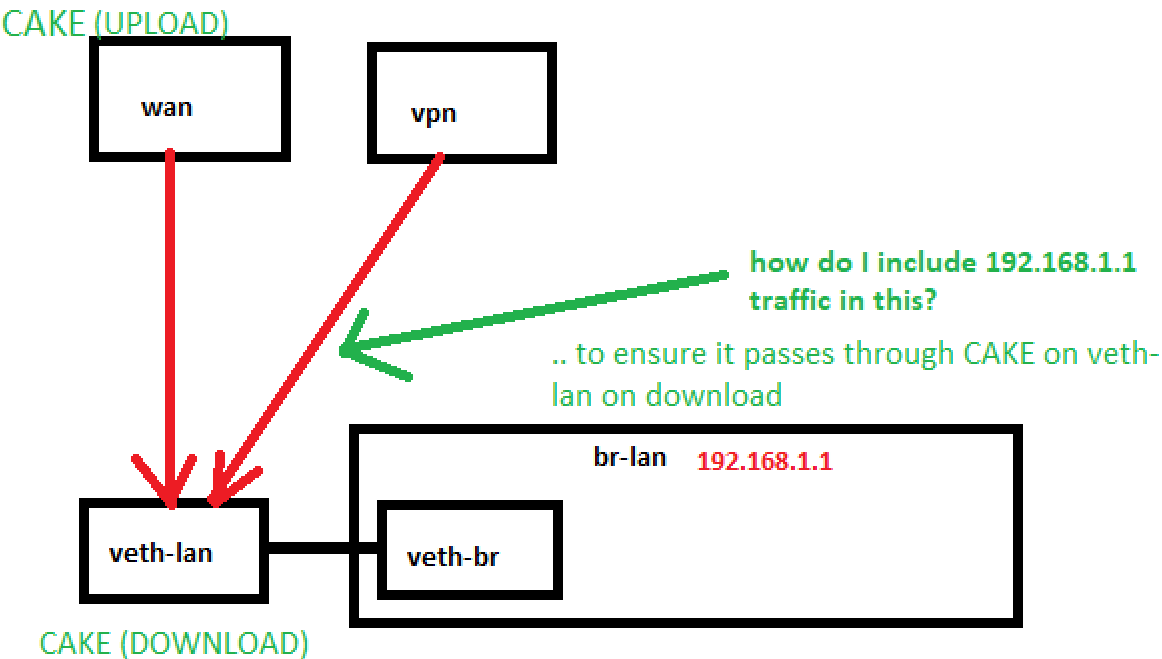
Hopefully this will allow users like me to claim back some more bandwidth rather than having to unduly sacrifice bandwidth to get CAKE to work properly.
Update: I have looked into @dlakelan's script more now. Actually it doesn't seem as complicated as I thought. My RT3200 already has all the erlang dependencies. How would I go about using this script? Is it as simple as running something like:
erlang sqmfeedback.erl
After editing the lines at the bottom:
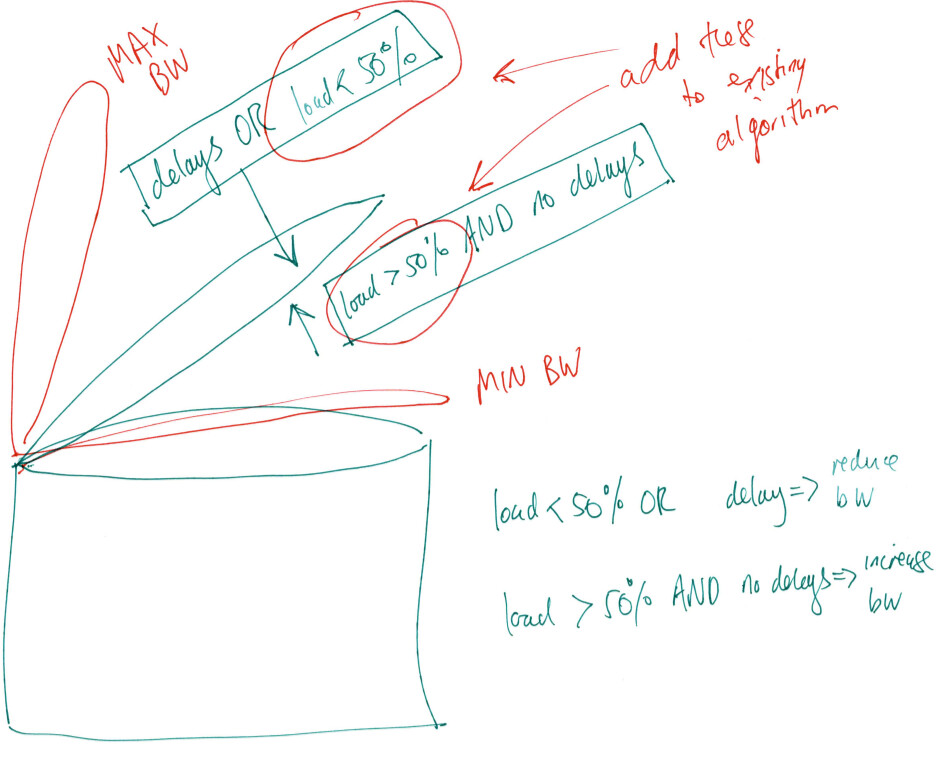
monitor_ifaces([{"tc qdisc change root dev eth0.2 cake bandwidth ~BKbit diffserv4 dual-srchost overhead 34 ", 4000, 6000, 8000},
{"tc qdisc change root dev ifb4eth0.2 cake bandwidth ~BKbit diffserv4 dual-dsthost nat overhead 34 ingress",15000,30000,35000}],
["dns.google.com","one.one.one.one","quad9.net","facebook.com",
"gstatic.com","cloudflare.com","fbcdn.com","akamai.com","amazon.com"]),
No point in me reinventing the wheel. The more I look at this code the more I like it.
 )
)