That depends on the details, we really have records of different length and can have multiple records in the FIFO, so we expect the read to give us a full line/record, but what happens if say a 20 bute control record is followed by a 100 byte data record in the FIFO and we read 100 bytes?
I really hope nothing bad happened to lynx, this project has been really innovative and its been amazing so far~ I was really looking forward to the progress
Wow, that was abrupt, and apparently without any explanation, so it's hard to know why. I do hope he comes back, he's been driving a lot of interesting stuff.
Sometimes you need to step away from things like this, but I think it's no biggie to just say "hey I'm taking a break from this for a few months" rather than anonymizing his account etc.
Without rehashing the original topic, he was outspoken in this thread and decided to leave on his own. He’s been active on Github since then, but hard to maintain a community project without interacting with the community.
Yes, I did. Besides autorate, I'm already monitoring cake itself, but went on a slightly different path from this, since I had already an "exporter" that I chose to keep. But I digress...
And thanks for the tip on the chrome extension.
Nice, so if I understand correctly, you managed to get cake statistics into Prometheus? Could you describe how you set this up or have a link to a guide? When I tried getting cake into Prometheus, I think there was a cake collectd package but had trouble getting Prometheus to scrape collectd Plugin:Write Prometheus.
First a disclaimer: my router isn't running OpenWrt, but Debian (it's an x86/64 small PC)
Actually, I first tried the collectd route, but I had issues getting it working, and I was eager to see cake stats on Grafana, so I ended up using a script I used to pull cake statistics into Cacti.
It simply outputs tc qdisc in json, and runs each 10 seconds.
Then I put in place a json api to publish the stats so that Prometheus could grab them thru json-exporter.
This approach is only a workaround, but as soon as I have the time I'll try collectd again. The main issue here seems to be the api lack of robustness, which I think explains the small gaps in the graphs (see below)
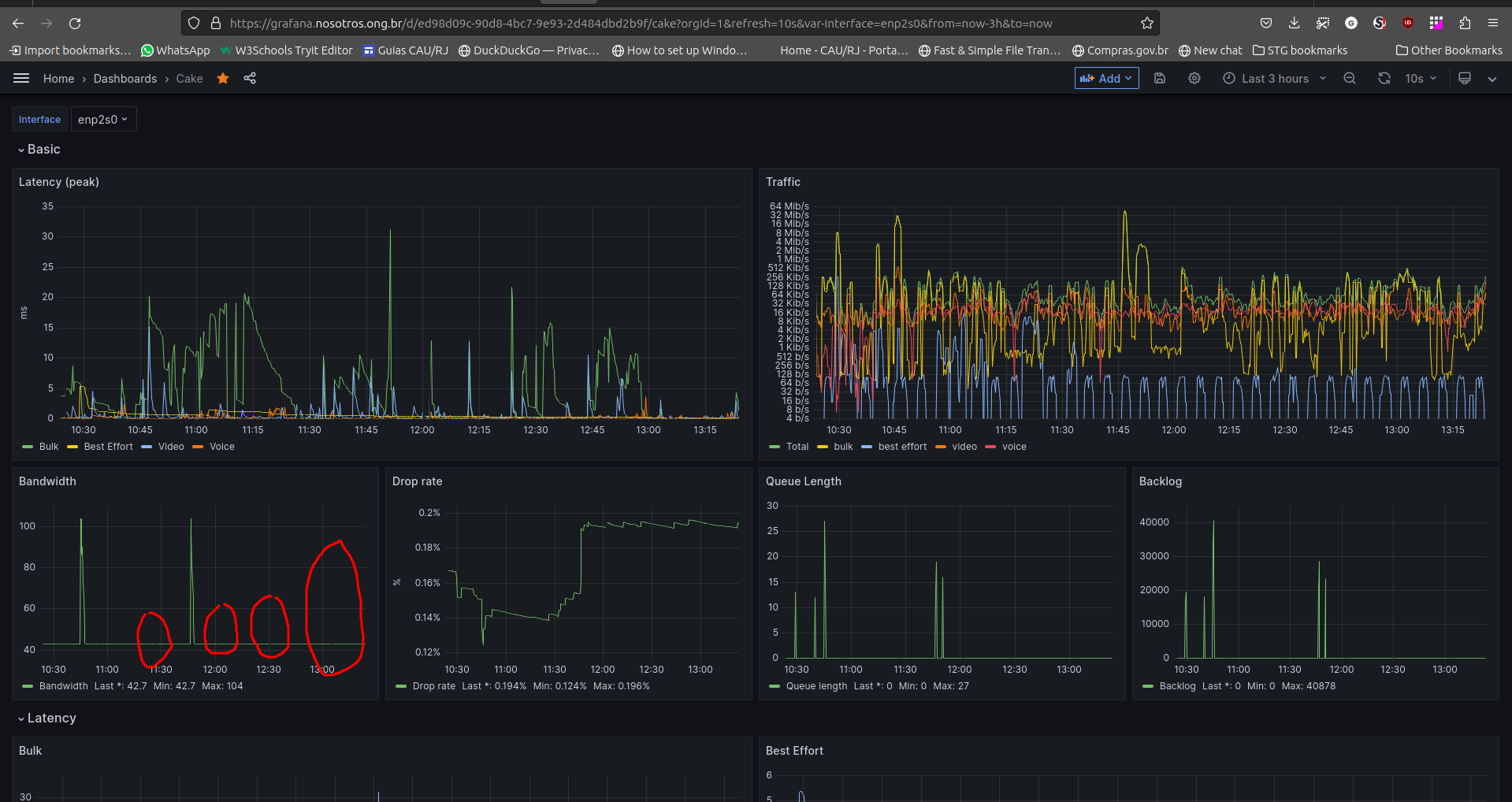
Hey @gadolf, would you be able to upload your script somewhere? Your Grafana Cake page is nice and I'm interested in setting up something similar. I like the way how you are showing the different traffic categories.
Hey @rb1 , sure, I can share the script. I'm currently at work and just came to realize that my wireguard tunnel to my server is down so I can only share it lately.
Meanwhile, shouldn't we split this discussion into a new thread, or even proceed from the SQM Reporting thread, where it suits better?
EDIT: @rb1 In case you want to start something without waiting for my script, I can advance some details:
The script reads the json output from tc -s -j qdisc dev ...., then it uses jq to save each metric into a small file named the same as the metric. So, at each run, it updates the files bytes, bandwidth, drops and so on. I set it to run each 10 seconds as a systemd process, started by a timer. Warning: for each metric a jq execution, so the script isn't exactly resource friendly;
I created some extended snmp oid's, one for each metric. Each oid is obtained simply by cat the metrics files;
In collectd, I use the snmp plugin, and set it up with all metrics oid's.
By the way, there are two servers (x86/64) involved here: the router (where the script and snmp runs) and the grafana/prometheus/collectd server.
After starting all this, I noticed an increase in the router CPU usage from around 1% to 8%, mainly due to the script running each 10 seconds, as well as snmp being called (by collectd) each 10 seconds.
This is a messy setup, I recognize, but like I said before, I took the script + snmp processes that were already running as collectors for my now dead Cacti monitoring. It can certainly be improved and simplified. But since I have spare resources in the router, I kinda relaxed (well... maybe I should look closely to the energy bill...)
(I'm really embarassed to share this dumb, inefficient piece of code ...)
Having all these small files available, then a correctly configured snmp daemon is able to deliver them whenever needed:
(excerpt from /etc/snmpd.conf)
Hi @gadolf, thanks for taking the time explaining in detail how you get the data into prometheus. Very interesting. When I get some time, see if I can set up something similar in Grafana.
Thanks for pointing me towards the SQM Reporting thread. Yeah I guess this could be split into a different thread, it is a bit off topic, I haven't explored this forum much beyond this topic.
One more question, just curious with your cake setup, looks like you have 4 tins: bulk, best effort, video and voice. I'm happy with the built in piece of cake with the one tin but if I use layer_cake.qos or simple.qos, tins I get are bulk, best effort and voice. What do you use to get the video tin?
gustavo@srv:/etc/sqm$ cat enp2s0.iface.conf
# Default SQM config; the variables defined here will be applied to all
# interfaces. To override values for a particular interface, copy this file to
# <dev>.iface.conf (e.g., "eth0.iface.conf" for eth0).
#
# When using ifupdown, the interface config file needs to exist for sqm-scripts
# to be activated on that interface. However, these defaults are still applied,
# so the interface config can be empty.
# Uplink and Downlink values are in kbps
#UPLINK=9000
#UPLINK=37000
UPLINK=85000
#DOWNLINK=270000
DOWNLINK=450000
# SQM recipe to use. For more information, see /usr/lib/sqm/*.help
#SCRIPT=piece_of_cake.qos
SCRIPT=layer_cake.qos
# Optional/advanced config
ENABLED=1
QDISC=cake
#LLAM=tc_stab
LINKLAYER=ethernet
OVERHEAD=22
#STAB_MTU=2047
#STAB_TSIZE=512
STAB_MPU=64
#ILIMIT=
#ELIMIT=
#ITARGET=
#ETARGET=
# ECN ingress resp. egress. Values are ECN or NOECN.
IECN=ECN
EECN=ECN
# Extra qdisc options ingress resp. egress
IQDISC_OPTS="diffserv4 nat dual-dsthost"
#EQDISC_OPTS="diffserv4 nat dual-srchost ack-filter"
EQDISC_OPTS="diffserv4 nat dual-srchost"
# CoDel target
#TARGET=5ms
#ZERO_DSCP_INGRESS=1
#IGNORE_DSCP_INGRESS=1
As for the whole grafana/prometheus/collectd setting, I was thinking that if you use a single machine, there's no need to bring snmp into the equation, and just use collectd_exec plugin, as proposed in that thread I pointed before.
I would probably be able to also eliminate snmp from my setup. All I had to do is installing collectd in the router machine and have prometheus on the monitor machine pointing to collectd url. Maybe I'll do that soon.
Please, remember: All this setup is under Debian machines, not Openwrt.
Ok thanks. SQM and cake is something I want to learn more about.
I'm thinking about making another python prometheus exporter starting off with the json values in your first script. I've played around with collectd a long time ago, (I know there is the collectd-mod-sqm package) but had some troubles with collectd exporter getting data from it into Prometheus. I believe there is another way using collectd to influx then grafana but haven't tested that yet. Looks like in that SQM reporting thread, there are some nice grafana plots using collectd-influx.
Can't tell, I typically do a separate git clone/pull on a separate machine, look at the scripts and manually copy them to my router, so I never tried the installation script. But maybe open a new issue on the github page, so you get the developr's attention to the issue?