Maybe by writing an empty line on start-up?
Someone on #bash suggested this:
var='1684240105.316459 1684240111.376439 94.140.15.15 0 44911330 44911352 44911352 44911376 46 24' rest=${var%%+([0-9]).+([0-9]) +([0-9]).+([0-9]).+([0-9]).+([0-9])*}; printf %s "${var#"$rest"}"
But I'm also thinking we can alternatively kill parse_preprocessor and start a new instance up:
You see what happens is that we read in a partial line from the old killed tsping instance, then read in a new line from the new instance, and end up with:
REFLECTOR_RESPONSE 1684240105.316459 1684240111.376439 94.140.15.15 0 44911330 44911352 44911352 44911376 46 24 22
But if we shutdown the parse_preprocessor from the old tsping instance, that partial line is lost, then we can start it up afresh for the new tsping instance.
Like so:
START_PINGER)
exec {parse_preprocessor_fd}> >(parse_preprocessor)
parse_preprocessor_pid="${!}"
printf "SET_PROC_PID proc_pids %s %s\n" "${parse_id}_preprocessor" "${parse_preprocessor_pid}" >&"${main_fd}"
${ping_prefix_string} tsping ${ping_extra_args} --print-timestamps --machine-readable=' ' --sleep-time "0" --target-spacing "${ping_response_interval_ms}" "${reflectors[@ pinger_pid="${!}"
printf "SET_PROC_PID proc_pids %s %s\n" "${parse_id}_pinger" "${pinger_pid}" >&"${main_fd}"
continue
;;
KILL_PINGER)
terminate "${pinger_pid}" "${parse_preprocessor_pid}"
exec {parse_preprocessor_fd}>&-
continue
;;
This wasn't an issue with fping because we had this bash regex matching:
[[ "${seq_rtt}" =~ \[([0-9]+)\].*[[:space:]]([0-9]+)\.?([0-9]+)?[[:space:]]ms ]] || continue
which happened to fix this partial read issue in respect of fping lines by skipping over such mixed up lines.
But probably the safest thing to do is to wipe the slate clean properly and start up a new parse_preprocessor instance:
I'm hopeful that these recent commits, which address the similar but separate partial reads issues in respect of both IPC commands and tsping lines, will render cake-autorate with tsping stable. Time will tell!
@moeller0 I also have another question for you.
Should we restart the pingers, just once, on a stall timeout of 10s? At the moment we just leave the pinger instance(s) running on stall and hope for the best. But if an interface went down and later went back up might not a restart be a good idea? So for example say interface went down for a day. The first restart on initial 10s one off timeout would do nothing. But the second restart associated with end of stall given data transfer despite no reflector responses and subsequent stall and 10s timeout given no reflector responses would then work?
@patrakov do you know if ping or fping is running and an interface goes down and later back up, does the pinger binary need restarting or can we rely on the old one?
So has this issue appeared with normal messages or only with killing tsping?
If the latter we might ask @lochnair to have tsping synthesise and print a complete record on receiving a TERM signal?
Other than that, I think we should put an end marker at the last position of each record so detection of incomplete records becomes easy?
I am not sure because with fping we skipped over odd lines given regex check.
@Lochnair would it be easy enough to ensure tsping prints a complete line before it is killed?
Does anyone have any more thoughts on the points @patrakov raised about the timings:
Any thoughts on this?
Maybe at the very least maintain_pingers() should check that the pinger binary/binaries are actually running on the 10s stall or even as soon as the stall is identified.
Fair enough, let's implement my idea of adding a record-unique end-marker as last value per record (or if the first field is a timestamp simply repeat that same timestamps as last field).
Because conceptually the atomicity of FIFO writes an reads should avoid that situation ever happening...
Not for SIGKILL, but likely for SIGTERM...
I think I tested that with fping over pppoe reconnects and things just continued to work...
But generally I defer to @patrakov for the stall handling since he is actually experiencing them (and as much as I dislike the ad-hocery of the stall handling I think we should handle situations like his gracefully)...
The "check if actually running" seems to be a good idea... except I would make parse_pinger do this, as parse pinger knows the PID and the exact command line the pinger was started with so it could check very selectively whether the pinger it started actually is still running...
For now I've just opted for the simple option of restarting pingers on a global ping response timeout:
The recent adjustments should preclude any lost IPC commands and deals with a partial tsping write (which is just discarded).
Please can anyone test the main branch with tsping now? There have been many fixes and improvements based on my own testing. And things seem like they might be stable now with tsping.
@rb1 any chance that you could update to the latest version on 'master' and test?
@moeller0 any chance you could test on your system?
Based on the discussion here, I see that we can launch individual instances from the procd script directly and bypass the separate launcher script. The procd service status is bugged right now, but @jow has worked on a fix. Hopefully this will make it into 22.03 or at least future versions of OpenWrt.
Instead of actually checking for incomplete records? I would guess these two things to be complimentary, keeping it simple AND checking for correctness ![]()
Do you think this is worthwhile?
If so, I'll pull it in - I don't think it'll eat up many extra CPU cycles.
I thouigh that would be an easy way just sandwich the data between the same time stamp and then on reading a record check that both timestamp fields have identical content.
I've implemented that above. The question is whether it adds value. What happened before was that we'd have a partial line write on tsping getting terminated. That partial line write would then get combined with the next good line up until the newline. But I've prevented that by terminating the parse_preprocessor (and hence discarding partial line) on terminating the pinger binary. Could there still be situations in which lines get mixed up? Maybe if the pinger binary messes up or other issues. What do you think? Shall we keep it or ditch it?
Keep it, this kind of sanity checking is something we should only abandon if we are sure it costs too much performance...
1 Like
I forget whether on your setup you can easily test tsping? If so, any chance you could test the latest cake-autorate code? It's got a super easy installer now that always pulls the latest code.
No, I would first need to build tsping against the turrisOS SDK something I a have not yet tried...
I looked into building custom packages here: https://gitlab.nic.cz/turris/os/build, and I also came across this example. But I think it would take me a while to figure out exactly how to proceed. @Lochnair put together very helpful instructions for the simple OpenWrt SDK case here.
@moeller0 I also just added an autogenerated 'log_file_rotate' script that sits in the /var/run directory together with the existing autogenerated 'log_file_export' script:
I think this is useful because it means you can locally or remotely and manually or via a script:
- rotate the log file to start afresh by calling /var/run/cake-autorate/primary/log_file_rotate
- perform speed tests
- export the log file by calling /var/run/cake-autorate/primary/log_file_export
- process the exported log file data using your Matlab/Octave script or otherwise
Example output:
root@OpenWrt-1:~# /var/run/cake-autorate/primary/log_file_rotate
Successfully signalled maintain_log_file process to request log file rotation.
root@OpenWrt-1:~# /var/run/cake-autorate/primary/log_file_export
Successfully signalled maintain_log_file process to request log file export.
Log file export complete.
Log file available at location: /var/log/cake-autorate.primary_2023_05_19_10_29_32.log.gz
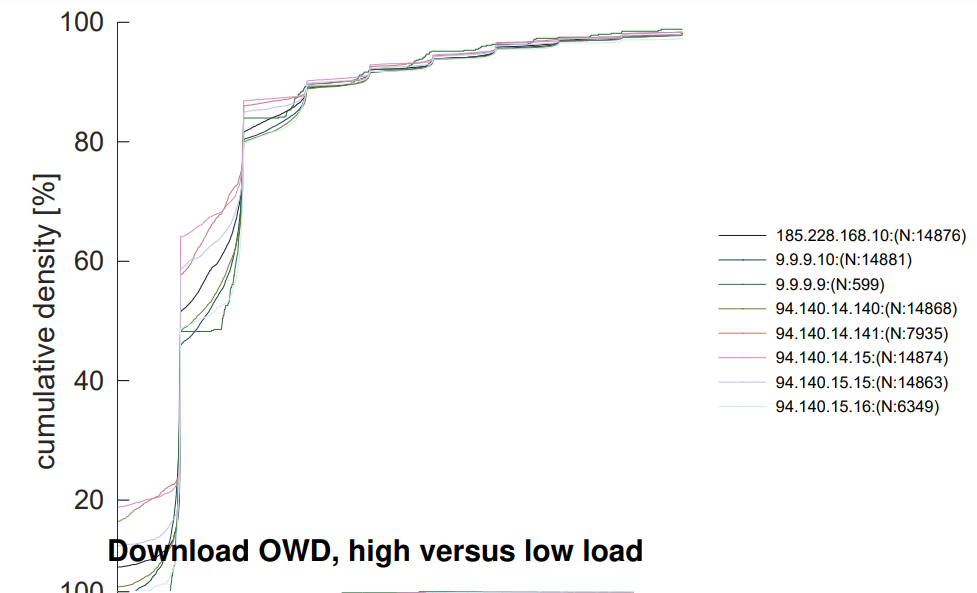
@moeller0 and for fun, here is a new plot for almost two hours of tsping data during light use:
timecourse:
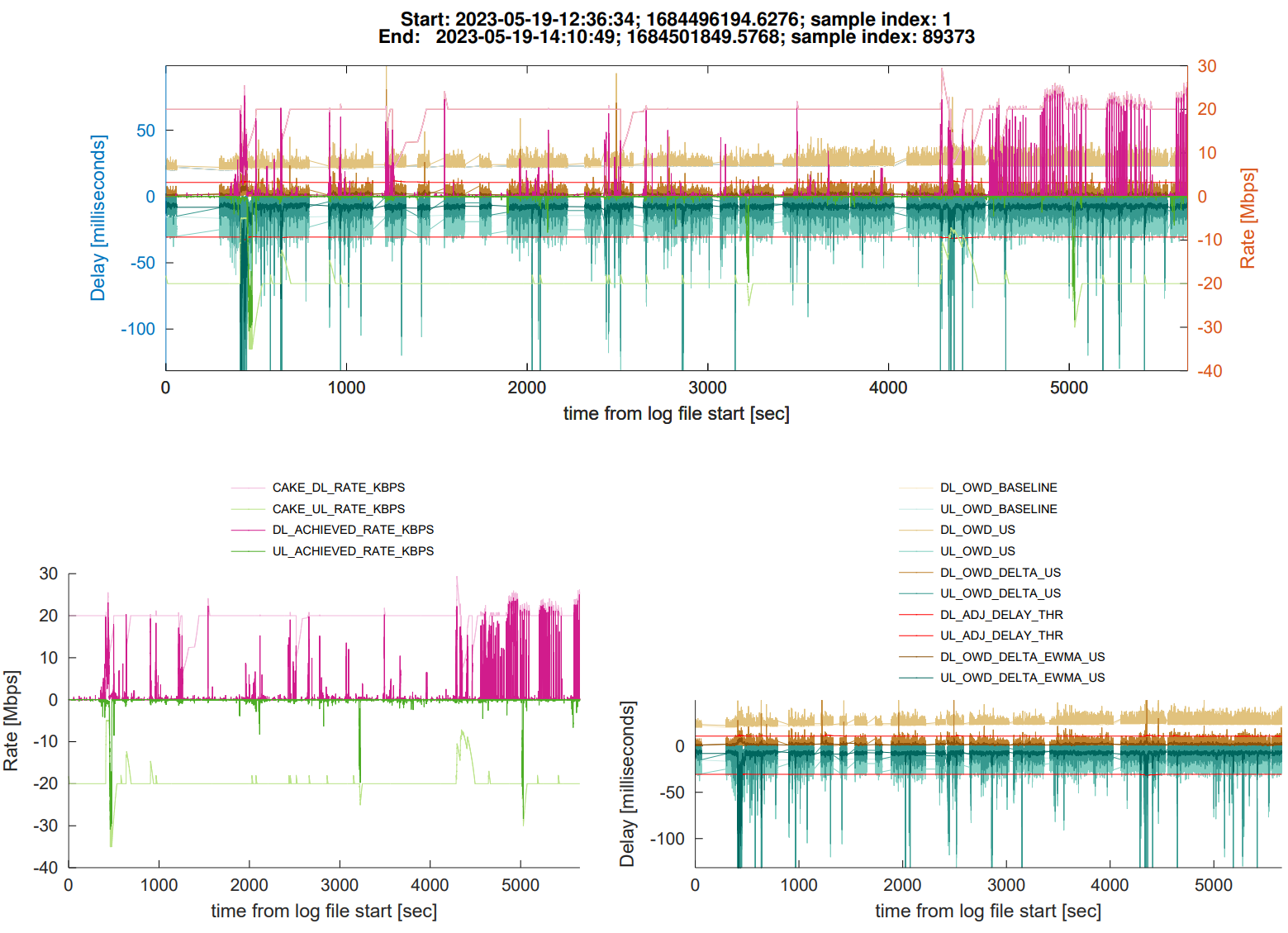
raw CDFs:

delta CDFs:

What are these funky shapes about I wonder:
Compressed log file here:
Ya, I should upgrade the router at some point, it is more a matter of time right now. I will try that earlier commit to see if the CPU changes at all. I will report that I just logged on and on the current version (pulled from github May 6) cake-autorate stopped working right around 2 days ago based on the last entry in the log.
So there are no entries in the log after 2 days ago but cake-autorate is still "running". According to ps, there are 199 processes of cake-autorate.sh, most of them being zombie processes. fping is still running.
Here is the end of the meaningful part of the log file. After this there is just a few hundred more lines of LOAD and then it stops:
LOAD; 2023-05-17-22:20:27; 1684380027.094564; 1684380027.093594; 426; 26; 14925; 2060
DEBUG; 2023-05-17-22:20:27; 1684380027.094500; Warning: no reflector response within: 0.500000 seconds. Checking loads.
DEBUG; 2023-05-17-22:20:27; 1684380027.097071; load check is: ((426 kbps > 10 kbps && 597 kbps > 10 kbps))
DEBUG; 2023-05-17-22:20:27; 1684380027.099343; load above connection stall threshold so resuming normal operation.
DEBUG; 2023-05-17-22:20:27; 1684380027.103759; Warning: no reflector response within: 0.500000 seconds. Checking loads.
DEBUG; 2023-05-17-22:20:27; 1684380027.106654; load check is: ((426 kbps > 10 kbps && 26 kbps > 10 kbps))
DEBUG; 2023-05-17-22:20:27; 1684380027.109407; load above connection stall threshold so resuming normal operation.
DEBUG; 2023-05-17-22:20:27; 1684380027.113749; Warning: no reflector response within: 0.500000 seconds. Checking loads.
DEBUG; 2023-05-17-22:20:27; 1684380027.116646; load check is: ((426 kbps > 10 kbps && 26 kbps > 10 kbps))
DEBUG; 2023-05-17-22:20:27; 1684380027.119409; load above connection stall threshold so resuming normal operation.
DEBUG; 2023-05-17-22:20:27; 1684380027.123760; Warning: no reflector response within: 0.500000 seconds. Checking loads.
DEBUG; 2023-05-17-22:20:27; 1684380027.126652; load check is: ((426 kbps > 10 kbps && 26 kbps > 10 kbps))
DEBUG; 2023-05-17-22:20:27; 1684380027.129405; load above connection stall threshold so resuming normal operation.
LOAD; 2023-05-17-22:20:27; 1684380027.304570; 1684380027.303600; 5; 5; 14925; 2060
DEBUG; 2023-05-17-22:20:27; 1684380027.304487; Warning: no reflector response within: 0.500000 seconds. Checking loads.
DEBUG; 2023-05-17-22:20:27; 1684380027.307027; load check is: ((5 kbps > 10 kbps && 26 kbps > 10 kbps))
DEBUG; 2023-05-17-22:20:27; 1684380027.309756; Changing main state from: RUNNING to: STALL
LOAD; 2023-05-17-22:20:27; 1684380027.515499; 1684380027.514085; 0; 11; 14925; 2060
LOAD; 2023-05-17-22:20:27; 1684380027.725437; 1684380027.724071; 168; 183; 14925; 2060
DEBUG; 2023-05-17-22:20:27; 1684380027.725149; Connection stall ended. Resuming normal operation.
LOAD; 2023-05-17-22:20:27; 1684380027.934557; 1684380027.933552; 125; 29; 14925; 2060
LOAD; 2023-05-17-22:20:28; 1684380028.144503; 1684380028.143515; 4; 0; 14925; 2060
LOAD; 2023-05-17-22:20:28; 1684380028.354535; 1684380028.353538; 5; 0; 14925; 2060
LOAD; 2023-05-17-22:20:28; 1684380028.564544; 1684380028.563543; 5; 6; 14925; 2060
LOAD; 2023-05-17-22:20:28; 1684380028.774456; 1684380028.773466; 0; 0; 14925; 2060
LOAD; 2023-05-17-22:20:28; 1684380028.984427; 1684380028.983422; 0; 0; 14925; 2060
I've double-checked and there is plenty of room on the filesystem. Have you been letting it run for long periods or do you restart the script periodically?
Yes - I think I tracked that issue down and resolved it. I think it was caused by the forking of sleep reads and is resolved by:
Since May 6 I have pushed a lot of different commits with various important fixes and improvements - see here:
Things seem stable again for me now.
It is hard to say with 100% certainty as the CPU usage for the CAKE component is variable depending on the current download speed which is highly variable with Starlink, but I went back and forth a couple times between the commit I pulled on May 6 and the pre-FIFO change commit you linked to above and it does seem like the CPU usage for me is lower before the FIFO change. Before that point, when the download speed gets around 100 Mbps, one core gets 90-100% in htop but the other 3 cores are lower, around 60-70%. After the FIFO change when the download speed is around 100 Mbps then all 4 cores are around that 90-100%.
I just saw your PM about the latest change, I will pull that commit and try now.
Please try the latest commit as of now. Take care to update all the files (at the least: cake-autorate.sh, cake-autorate_lib.sh, cake-autorate_defaults.sh, the service script cake-autorate) - a run from @rany2's installer should suffice to update everything to the latest commit. The latter was designed to rapidly update to the latest commit, whilst retaining the custom config.
Are you using fping or tsping by the way? I've switched across to tsping but am still maintaining support for ping and regular iputils-ping.
I'm running cake-autorate for long periods myself now - circa 24 hours per run between code updates and re-run as service.
Again, sorry about the stability issues with the latest code on 'master' - some time ago I substantially rewrote many aspects of cake-autorate and there were (and possible still are) a few things needing ironed out. As you can see from the commit history I've been pretty busy!
I'd really appreciate input from a couple of users to help ensure we get things 100% stable again on 'master'.
Once things look stable, I'm keen to finally settle on a commit for a version 2.0.0 release.
Great, thanks for your work on this! I updated to the latest commit and your sleep fix definitely made a difference. Now when it gets above 100 Mbps down one core is still getting 90-100% CPU but the other 3 are more like 60-70%, so there is a little breathing room on my little router. The bandwidth while waveform is sometimes showing above 130 Mbps which I didn't see before with cake-autorate running, although once it settled down it ended up right around 100 Mbps download. I'll have to try it earlier in the morning sometime when Starlink tends to be a little faster, but of course 100 Mbps is not a problem at all if we can keep latency down. Previously it seems like the CPU was limiting the speed when cake-autorate was running but now I think I might be getting the full bandwidth.
I'm still using fping. I'd like to try tsping once it is in the OpenWrt package repository.
I've just been letting cake-autorate run so in the latest run it had been going for 11 days before it got in that weird state. Do you think I should be restarting it every day?