@dlakelan I have some thoughts about your script.
My experience with having tested it plenty so far is that its convergence under load works very well. So I think that problem has been solved. But I think the approach is incomplete owing to its load blindness. Specifically: increasing bandwidth based on no ping delays under no load seems flawed because the ping data in this condition is not indicative of more capacity.
Perhaps with the modification below this script could offer a good solution for the many OpenWrt users wanting autorate-ingress functionality?
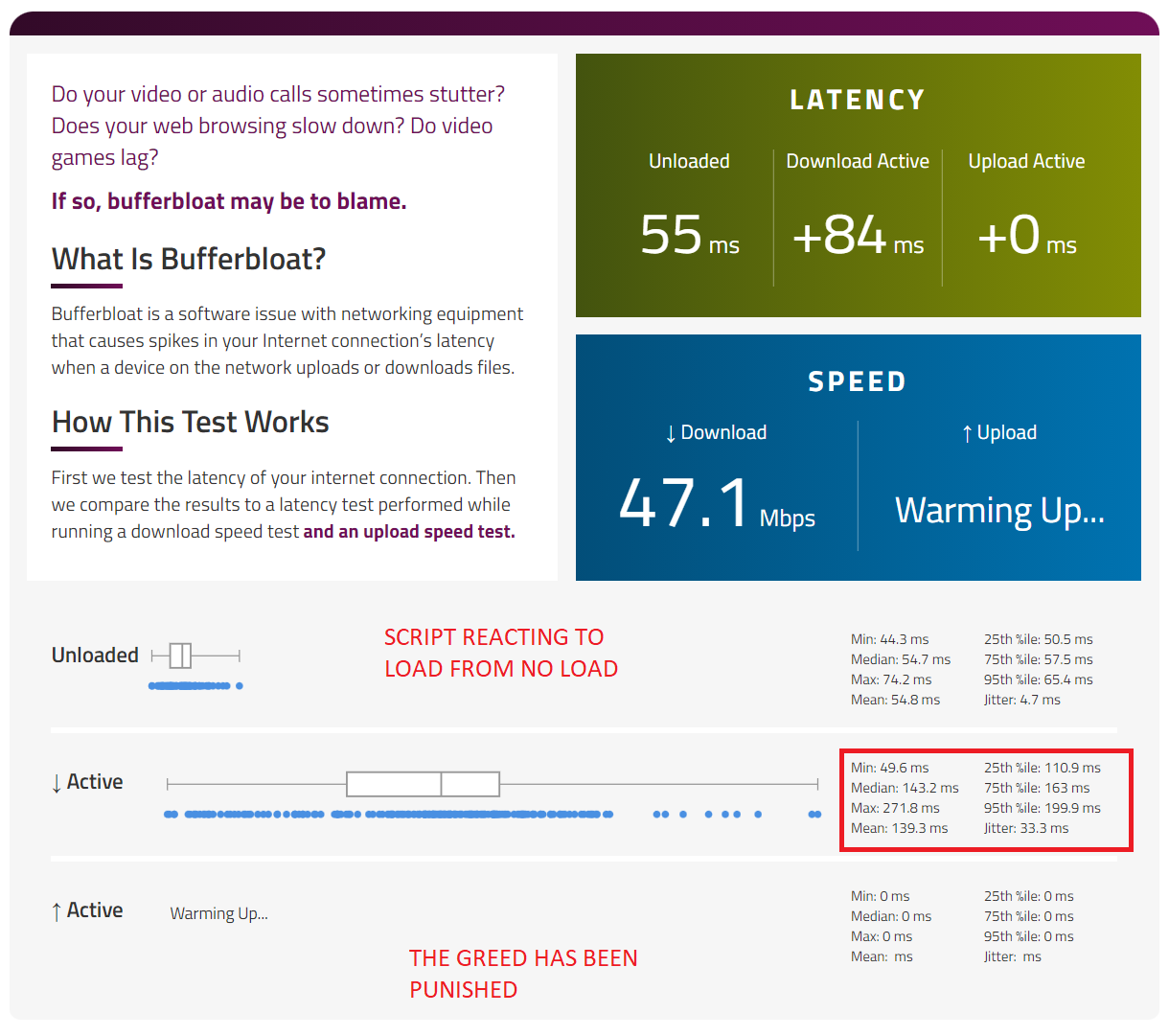
To illustrate the problem, the maximum bandwidth my LTE connection ever sees is 70Mbit/s. So I tried increasing the max bandwidth to 60Mbit/s to see what would happen.
Under no load your script will tend to revert to maximum set upload and download. But the ping data that led there is invalid because no delays would ever be experienced anyway since there is no load. And thus any impulse load following no load will tend to result in massive bufferbloat until the script reacts.
This does not seem optimal:
How about only converge upwards so long as load is greater than a set threshold? After all, there is no need to provide extra bandwidth if there is no demand for that extra bandwidth, right? I think @lantis1008's script sensibly factors this in.
By providing the extra bandwidth even when it is not even called for under no load (greed), aren't we setting up the system for a bufferbloat-related fall once the load happens?
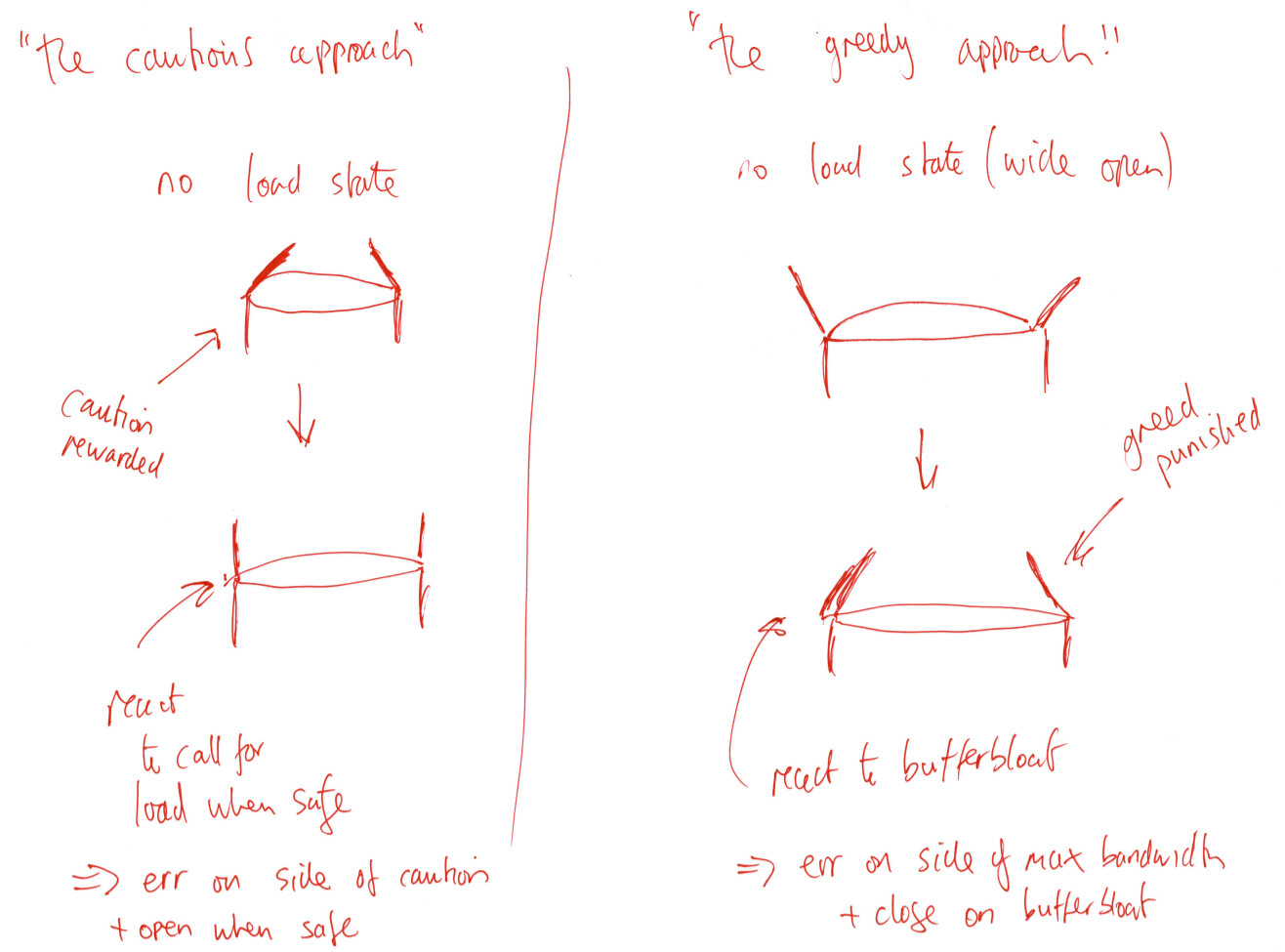
Wouldn't it be better to:
- [the cautious approach] cautiously increase bandwidth reactive to demand for load, whilst it is safe to do so (so under no load, system is at min bandwidth)
rather than:
- [the greedy approach] greedily increase bandwidth even when there is no demand for it, and then have to react to increased ping upon load (so under no load, system is at max bandwidth)
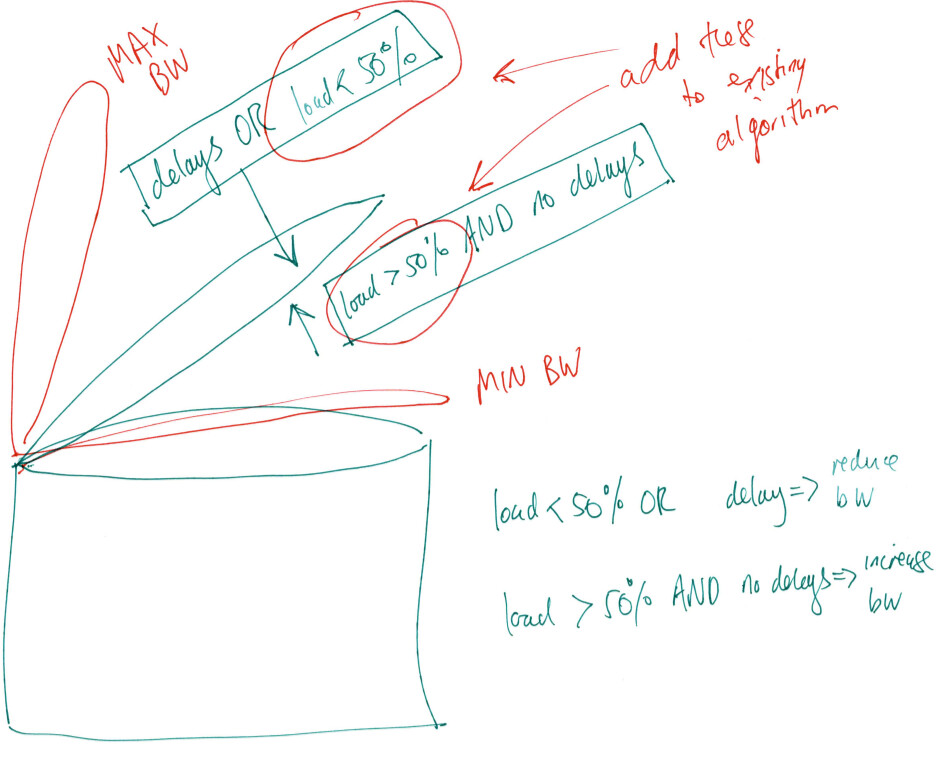
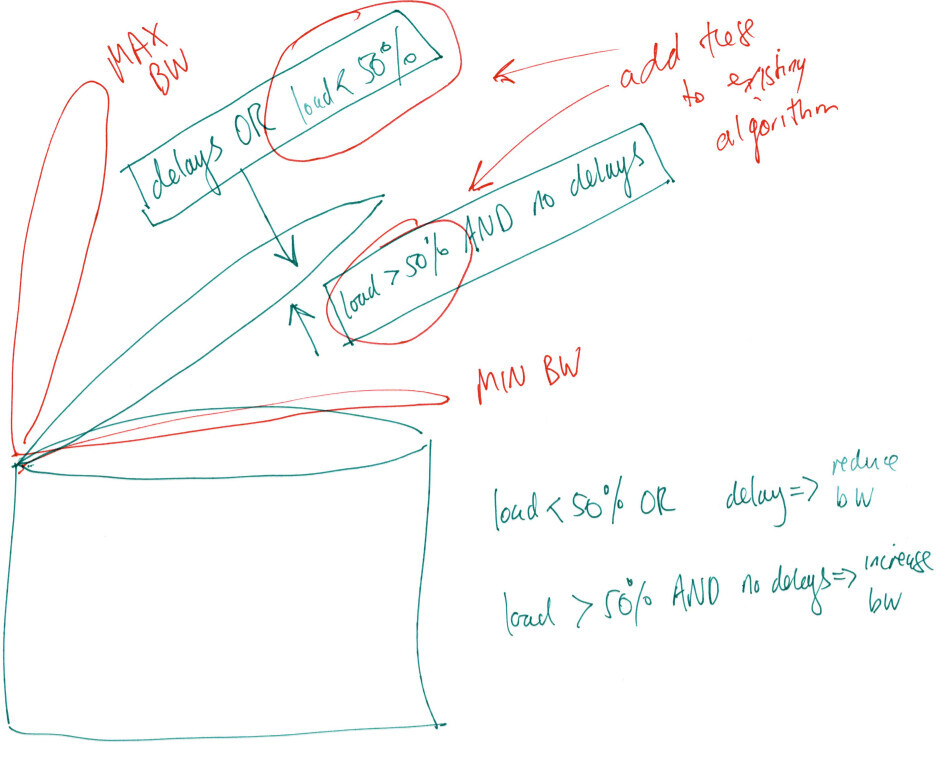
How about only allow an increase in bandwidth when the load is greater than say 50%. And perhaps also converge downwards when load is less than 50%?
So the driving forces for opening and closing would then be:
- load > 50% AND no delay encountered → increase bandwidth
- load < 50% OR delay encountered → reduce bandwidth
Here is an illustration of the above:
This would mean that under no load the system is low latency and ready to react to an increased demand for load. It will deal with impulse loads better. Also I think we are always reacting to meaningful ping data.
Obviously keeping things simple seems highly desirable, but the modification proposed herein seems simple enough and potentially of significant benefit.
What do you think?
Would there be an easy way to take into account load in this way (or similar) in this part of your script:
monitor_delays(RepPid, Sites) ->
receive
{delay,Site,Delay,Time} ->
NewSites=[{Site,Delay,Time}|Sites],
monitor_delays(RepPid,NewSites);
{timer,_Time} ->
io:format("Checking up on things: ~B\n",[erlang:system_time(seconds)]),
Now=erlang:system_time(seconds),
RecentSites = [{Site, Del, T} || {Site,Del,T} <- Sites, T > Now-30],
io:format("Full Delayed Site List: ~w\n",[Sites]),
io:format("Recent Delayed Site List: ~w\n",[RecentSites]),
%% use random scaling factors, but make sure down followed
%% by up averages slightly less than 1, based on
%% simulations this averages around .98... this ensures
%% we don't grow too fast.
if length(RecentSites) > 2 ->
Factor = rand:uniform() * 0.15 + 0.85,
RepPid ! {factor,Factor};
true ->
Factor = rand:uniform() * 0.12 + 1.0,
RepPid ! {factor,Factor}
end,
monitor_delays(RepPid,RecentSites)
end.
Is there an already existing stock system command for obtaining instantaneous upload/download bytes transferred per second that could be called? Or perhaps rx/tx bytes transferred would need to be polled and compared with a timer?
@moeller0 and @lantis1008 I'd also be very interested in your thoughts on this.