Given Starlink's steep steps, I would first jettison the "hold" on medium load logic, and maybe decrease the timeout after rate reductions somewhat. And maybe increase the temporal sensitivity by:
bufferbloat_detection_window=6 # number of samples to retain in detection window
I would not generally set this number higher than the number of concurrent reflectors...
bufferbloat_detection_thr=2 # number of delayed samples for bufferbloat detection
I would set this to a small number, so 2 or even 1, but I am biased to trying to remove the nasty RTT spikes over conserving throughput, so that is something for the OP to test.
Maybe split this into an increase and decrease variable to allow to differentiate how the base rate is approached depending on whether the last definitive analysis places us above or below that rate?
Makes sense to me. Presumably down from up should be more aggressive than up from down.
Is the medium load logic with the horizontal shaper rate holds hurting do you think? Could you elaborate if so?
In the second round of data the achieved rate lagged behind the shaper rate quite a lot. I presume the shaper rate hike was too high in this second time round because in the first the achieved rate nicely followed the shaper rate. In the first there was only a small amount of medium rate holding.
Do you think the medium rate holding will just never work well for variable rate connections? It seemed desirable to facilitate where there is some form of load that was about 50% of shaper rate so room to grow and not interfere with that steady flow but perhaps this is just an ideal in my mind that doesn't work in reality or if it does it's just an edge case overshadowed by the ruin it does in the majority cases. If the latter then I should just chop the idea entirely.
Yes that would be sane I believe, as before by setting base to either max or min it can be completely disabled, but still allowing it to be a bit more conservative seems desirable.
Well, it appears as it starlink has rather steep steps in rate and so our heuristic assume that rate stays stable if we have some load but not enough to trigger a rapid rate decrease will occasionally be wrong for starlink. But this relies on a few assumptions about starlink, that I have that might not actually reflect starlink's reality
But that should only happen if we cross the 80% load line (but it is enough to cross that occasionally since the hold-on-medium-load heuristic will keep the shaper rate high)... The more I think about it the less I like the hold logic :).
No, but I believe it is a heuristic that occasionally works better or worse and for starlink it seems to not work too well. Again this is based on my mental model of starlink having "hard" steps depending in rate... BTW, if my model is correct, we might do a better job with fewer but much larger rate decrease steps, or I am out to lunch
Just because I have theoretical concerns? No! I have been wildly off the mark in the past. But making it easy to disable for now might be a good idea so users like @gba can easily test whether it helps or hurts, which should give information to decide about this features fate, no?
# the load is categoried as low if < medium_load_thr, medium if > medium_load_thr and high if > high_load_thr relative to the current shaper rate
medium_load_thr=0.25 # % of currently set bandwidth for detecting medium load
high_load_thr=0.75 # % of currently set bandwidth for detecting high load
So this facility can be disabled by simply setting the medium_load_thr to be equal to the high_load_thr. Do the defaults seem reasonable and given capability to disable do you think this is all OK as is?
I guess that is a rather generous definition of 'medium' ;), but sure if setting this to the same value as high_load_thr will disable that fine...
Maybe set the default to 50%?
achieved_rate_adjust_bufferbloat=0.9 # how rapidly to reduce achieved rate upon detection of bufferbloat
shaper_rate_adjust_bufferbloat=0.9 # how rapidly to reduce shaper rate upon detection of bufferbloat
shaper_rate_adjust_load_high=1.01 # how rapidly to increase shaper rate upon high load detected
shaper_rate_adjust_load_low=0.98 # how rapidly to return to base shaper rate upon idle or low load detected
Should I make all these:
achieved_rate_adjust_down_bufferbloat=0.9 # how rapidly to reduce achieved rate upon detection of bufferbloat
shaper_rate_adjust_down_bufferbloat=0.9 # how rapidly to reduce shaper rate upon detection of bufferbloat
shaper_rate_adjust_up_load_high=1.01 # how rapidly to increase shaper rate upon high load detected
shaper_rate_adjust_up_load_low=0.9 # how rapidly to return to base shaper rate upon idle or low load detected
shaper_rate_adjust_down_load_low=0.98 # how rapidly to return to base shaper rate upon idle or low load detected
Or just split out the last two like:
achieved_rate_adjust_bufferbloat=0.9 # how rapidly to reduce achieved rate upon detection of bufferbloat
shaper_rate_adjust_bufferbloat=0.9 # how rapidly to reduce shaper rate upon detection of bufferbloat
shaper_rate_adjust_load_high=1.01 # how rapidly to increase shaper rate upon high load detected
shaper_rate_adjust_up_load_low=0.9 # how rapidly to return to base shaper rate upon idle or low load detected
shaper_rate_adjust_down_load_low=0.98 # how rapidly to return to base shaper rate upon idle or low load detected
I would split all of these out in the code. If it turns out that they are better in lockstep just use something like:
shaper_rate_adjust_up_load_low=0.9 # how rapidly to return to base shaper rate upon idle or low load detected
shaper_rate_adjust_down_load_low=${shaper_rate_adjust_up_load_low} # how rapidly to return to base shaper rate upon idle or low load detected
in config.sh...
Just like I would also treat the RTT as ul_OWD and dl_OWD ;), but it is easy for me to pontificate, I am neither using the code nor maintaining it, so you should make the decisions you consider striking the best balance between maintainability and exposing enough control...
Loving seeing you all go to town. A couple notes - when I first tested last year, it seemed starlink had 3 steps, and optimized on a 16s interval, with about a 40ms switch between sats. These may no longer be the case, but it was seemed to be then about
# rate adjustment parameters
# bufferbloat adjustment works with the lower of the adjusted achieved rate and adjusted shaper rate
# to exploit that transfer rates during bufferbloat provide an indication of line capacity
# otherwise shaper rate is adjusted up on load high, and down on load idle or low
# and held the same on load medium
achieved_rate_adjust_down_bufferbloat=0.9 # how rapidly to reduce achieved rate upon detection of bufferbloat
shaper_rate_adjust_down_bufferbloat=0.9 # how rapidly to reduce shaper rate upon detection of bufferbloat
shaper_rate_adjust_up_load_high=1.01 # how rapidly to increase shaper rate upon high load detected
shaper_rate_adjust_down_load_low=0.9 # how rapidly to return down to base shaper rate upon idle or low load detected
shaper_rate_adjust_up_load_low=1.01 # how rapidly to return up to base shaper rate upon idle or low load detected
So returning to @gba I think the new parameters for testing are:
reflector_ping_interval_s=0.15 # (seconds, e.g. 0.2s or 2s)
no_pingers=6
delay_thr_ms=75 # (milliseconds)
medium_load_thr=0.75 # % of currently set bandwidth for detecting medium load
high_load_thr=0.75 # % of currently set bandwidth for detecting high load
bufferbloat_detection_window=6 # number of samples to retain in detection window
bufferbloat_detection_thr=2 # number of delayed samples for bufferbloat detection
achieved_rate_adjust_down_bufferbloat=0.85 # how rapidly to reduce achieved rate upon detection of bufferbloat
shaper_rate_adjust_down_bufferbloat=0.85 # how rapidly to reduce shaper rate upon detection of bufferbloat
shaper_rate_adjust_up_load_high=1.02 # how rapidly to increase shaper rate upon high load detected
shaper_rate_adjust_down_load_low=0.8 # how rapidly to return down to base shaper rate upon idle or low load detected
shaper_rate_adjust_up_load_low=1.01 # how rapidly to return up to base shaper rate upon idle or low load detected
@moeller0 do you propose any further changes for next test for @gba to try? And in particular in the light of @dtaht's post above?
@gba could you retest with these once @moeller0 has commented?
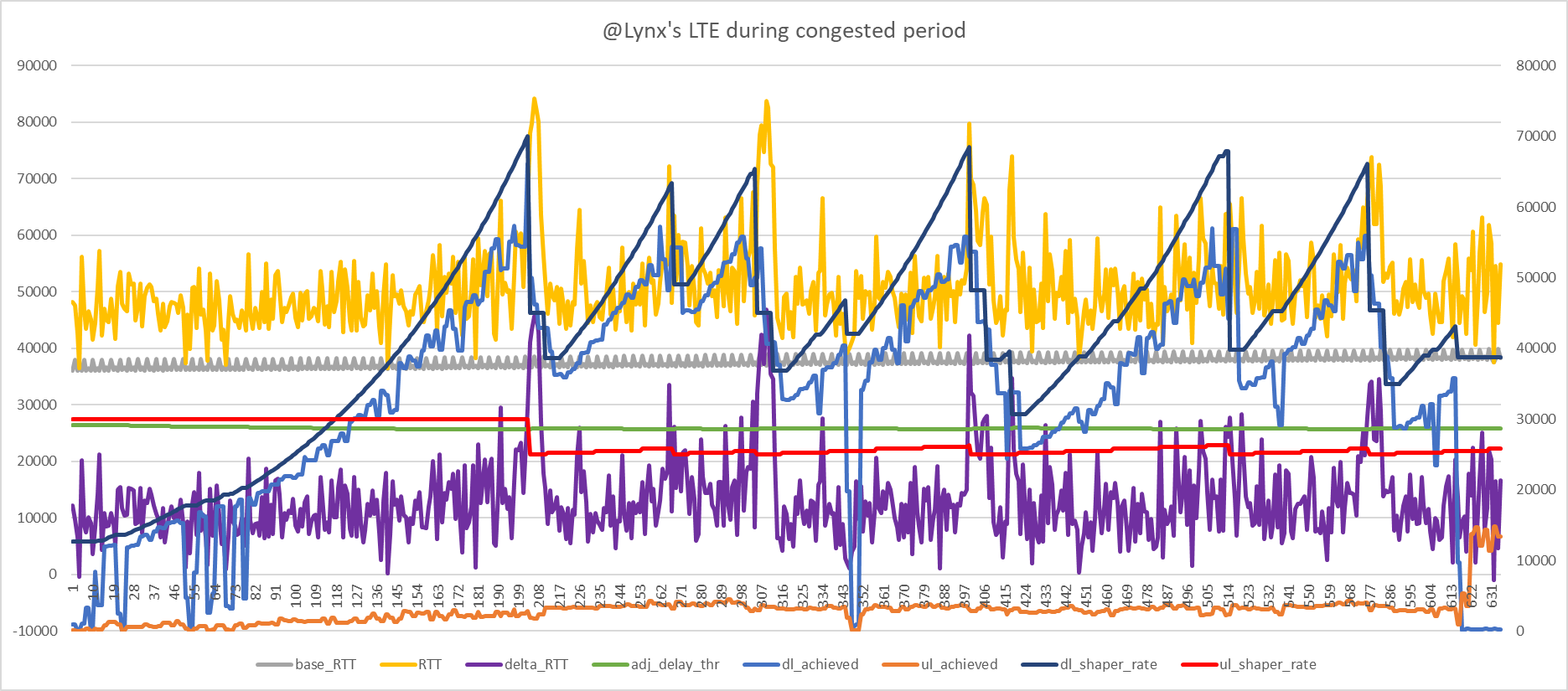
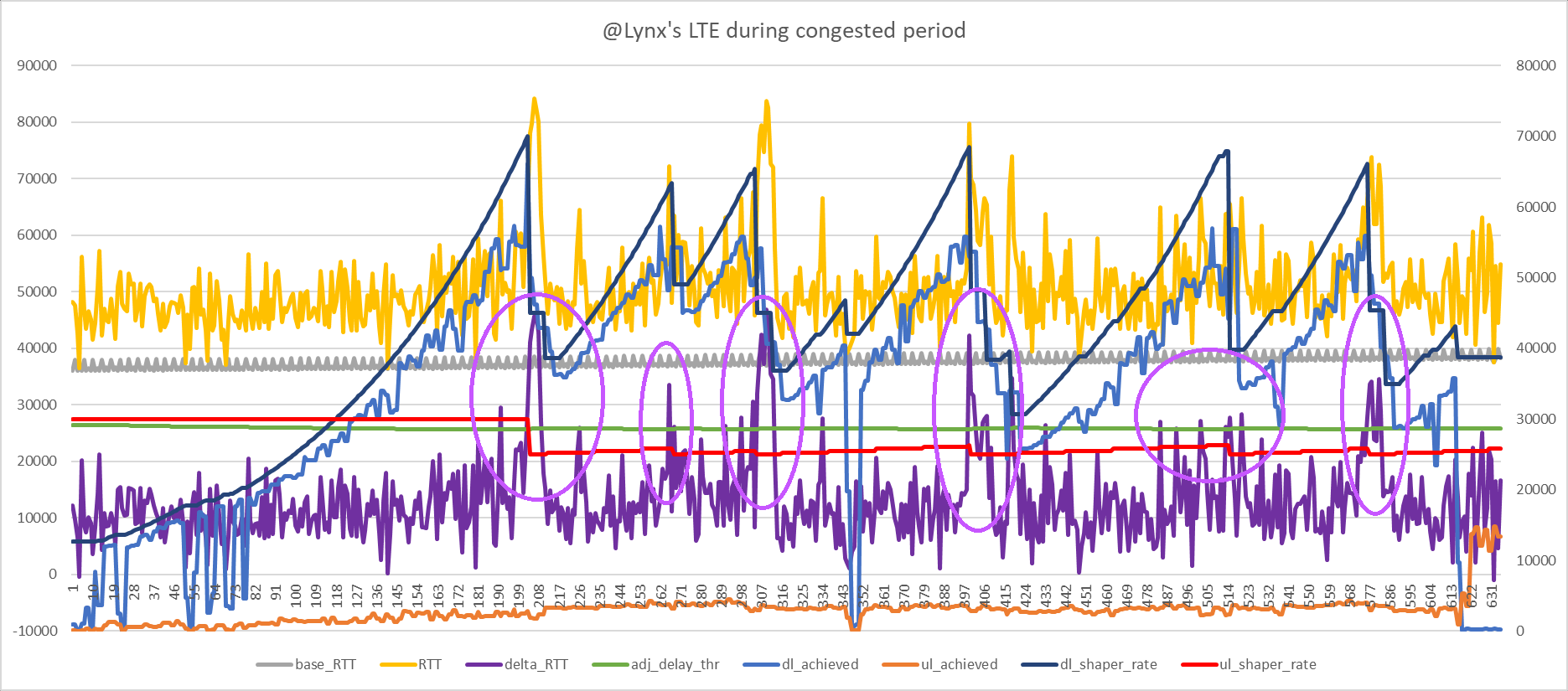
@moeller0 see what I mean about it being clearer on my connection the script is doing the right thing? For one thing the delta_RTT has rather more pronounced spikes as follows:
Oha, that are some harsh steps... to deal with that might require to increase the step granularity quite a lot into the 1.2-1.3 range for increases and 0.5 for decreases (this will help with the big steps, but might cause issues when tracking our share if capacity is congested).
...and a 40ms switching delay does not help either... that means occasionally we will get an >=40ms spurious increase in RTT (assuming we actually have inflight RTT data in that period)... this might last for a few samples, so maybe instead of my proposed 2 of 6 we would need something like 4 of 6 so we brush over such expected transient RTT increases?
I guess I need to look at @gba's flent traces to get a better feeling for rate switch dynamics.
I am conflicted, as above, not sure whether 2of6 will not get hung up on the described satellite switching delays... (I guess the easiest would be for @gba to test both and report back how they "feel")
Yes, I agree, I also fail to see the medium-load stay-the-course logic to trigger... My suspicion is that in @gba's case something limits the true bottleneck to below our shaper rate (somewhere between the old 25 and 75% thresholds so that the rate is kept unchanged) but that results in our load-percentage estimate to be artificially wrong. Maybe hidden by the fact that the RTT variance is so high that we can't tune for the true latency-under-load increase...
Does anybody know whether starlink uses any traffic shaper in any direction that already limit the normal queueing delay to something sane-ish (and where the satellite switching delay comes on top).
I'd intended these as starlink measurement nodes. They are fairly beefy servers in linode's cloud, in mumbai,de,ontario,dallas,atlanta,london,singapore,fremont
Excellent, except that I have no starlink link to actually use your infrastructure as intended
Not sure how interesting results from a bog-standard VDSL2 link would be
What format would you prefer (-o out.json.gz?) or just plain text from redirecting the output into a file?
I guess you do not care much about sqm enabled or disabled as in a quiet network this should not matter much?
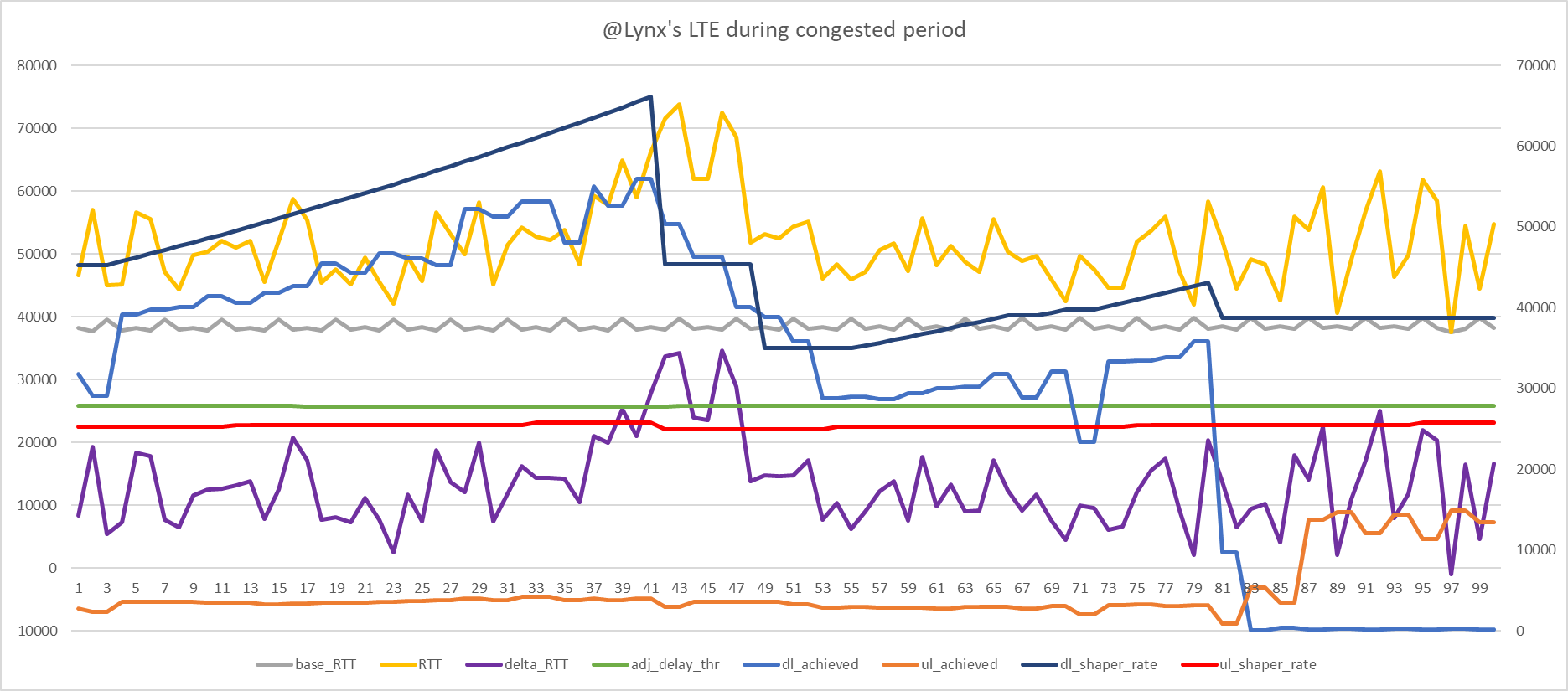
But bufferbloat wasn't resolved in that period so another drop was needed. Does this suggest the refractory period should be slightly increased in my case?
Or perhaps it's more complicated than that since my detection window takes time to clear.
So there is maybe an unresolved matter for consideration relating to the size of the detection window? Like on bufferbloat correction it should be cleared? Should I set them all to zero on bufferbloat detection rather than wait for the count to drop?
Well, try it if that period is too short the controller will dip too low, simply because it takes a bit to service the already full buffers so immediately after a "brake" signal we are likely to pick the next one immediately since the senders might not have had enough time to adjust to the new speed ceiling... so I guess if that is set too low you should see weird oscillations, but hey, I have not tested that assumption empirically so this might be less of an issue in practice.
I guess try with a shorter refractory period and just look whether it still behaves well enough.
OK makes sense to me. What about the detection window though. I have that set to 4 samples and detection at 2. So out of last 4 samples if 2 are delayed its bufferbloat. On bufferbloat we see count reach all 4 strikes. And it takes time then for that to get back down to 1 such that bufferbloat is no longer detected. Is it correct to wait for the window to naturally clear or should the whole window be cleared on detection to prevent a second artificial detection of the window hasn't cleared naturally in time if you see what I mean? I mean should I reset the count of strikes to 0 whenever bufferbloat is detected?
There must be some interaction between this window size and the refractory period and I'm not sure how the width of the window and refractory period should correspond.
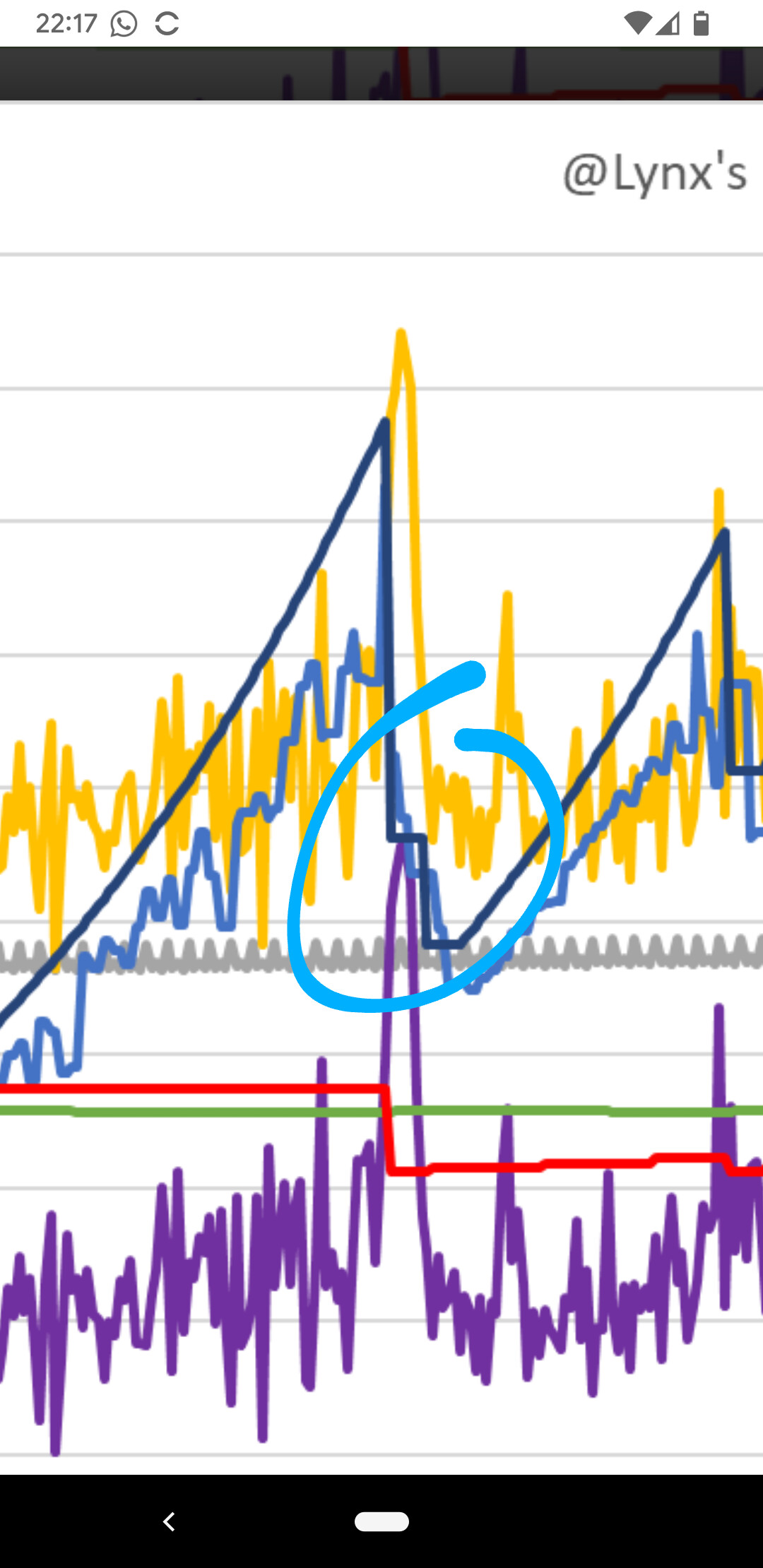
See in this data there are technically two bufferbloat detections but perhaps the second was false?
Cause it takes new good samples coming in to knock out the old strikes. So old strikes that counted towards a previous bufferbloat detection can contribute to new bufferbloat detection. Maybe that makes no sense. I'm not sure.