I see, sorry for my initial misunderstanding.
Maybe check irtt which seems to offer a lot of the required functionality already?
I am all for it, especially since the lua script is somebody else's problem ![]()
I see, sorry for my initial misunderstanding.
Maybe check irtt which seems to offer a lot of the required functionality already?
I am all for it, especially since the lua script is somebody else's problem ![]()
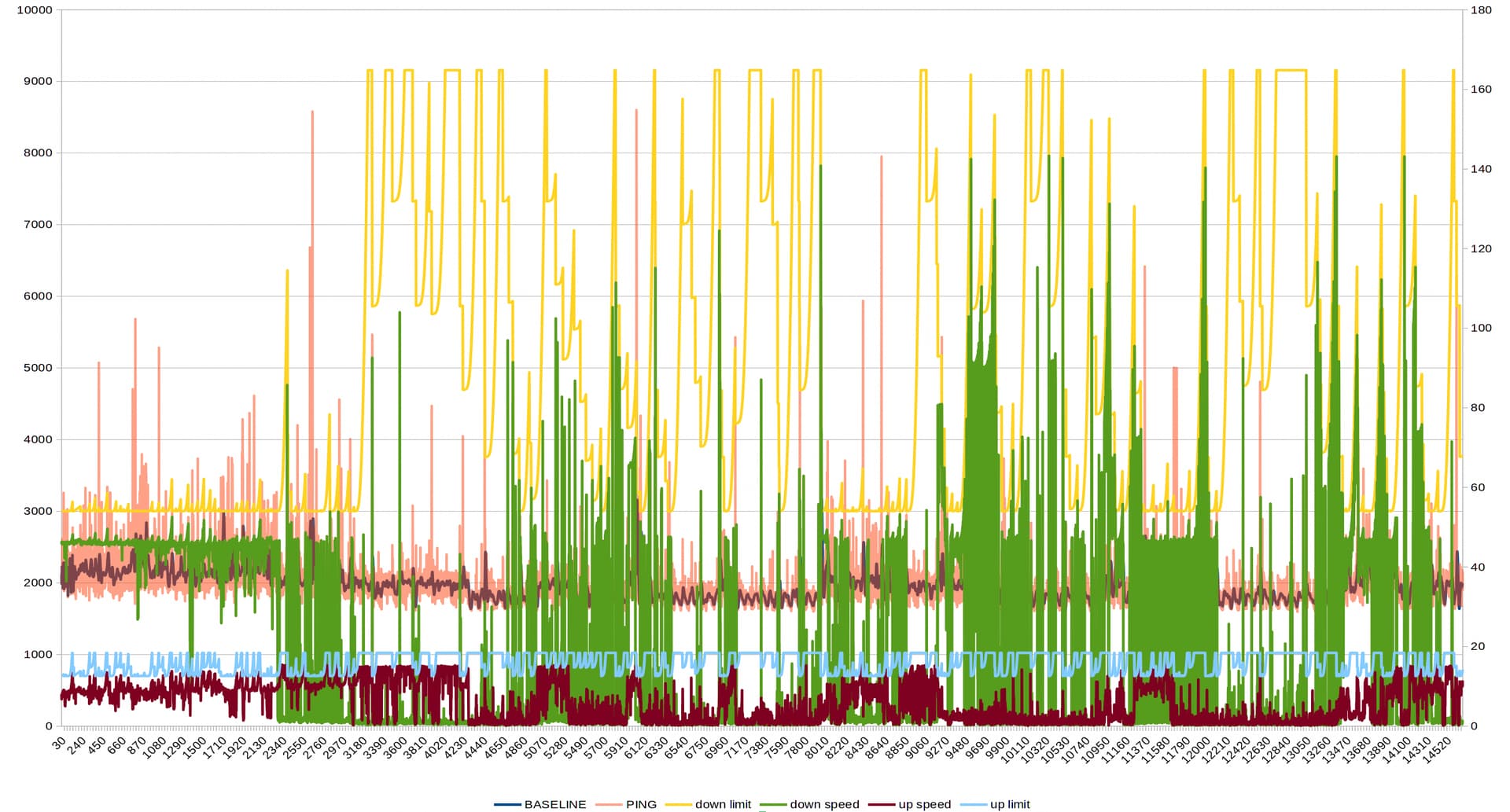
I 've implemented the digital filter proposed by @nbd and tcp cubic. The tcp cubic implementation that I did before had many calculation bugs into it. 
Here is the result.
In the next days I will try again the following baseline algorithms, fame median, fame 95%, fame 5% and @Lynx original algorithm with cubic.
My thoughts from the graph is that current upload speed impacts a lot ping, causing cubic to limit the download speed in order to keep ping low.
Yes that's not been addressed yet in the shell script either (properly handling flow direction). So whilst download and upload separately increases on load, upon detection of an RTT spike both are decreased. Which is suboptimal.
@openwrticon is your code on GitHub? The RTT seems to spike quite a lot. Too much would you say? What do you think of the sprout algorithm discussed above for bandwidth estimation? Doesn't look so insane to code, no? They report great results on variable rate connection and although end to end I wonder if the receiver side could be leveraged. Tempted to try it? Sections 3.1 to 3.3 of paper and instead of reporting bandwidth to sender it is just used to set CAKE bandwidth. But as @moeller0 has explained above this may not improve things dramatically. In any case I'd be interested in your thoughts.
@moeller0 I just had a thought when reading up about the preserving of skb->hash to allow CAKE to work on upload in the context of WireGuard tunnel.
Wouldn't it be possible to have the WireGuard protocol itself offer end to end bufferbloat management such as is employed in sprout in which receiver feeds back to sender to give super low latency for high bandwidth?
Its just I imagine VPN tunnels often overlap with last mile links so wonder if that could be exploited to help facilitate feedback from receiver to other end of link close to sender.
Would it matter in that case that sender (e.g. a fast NordVPN server) is not quite at the sending end of the last mile link? I'm imagening the latency increase from NordVPN to ISP is small compared to last mile link increase.
If this is a crazy idea, which it might well be, would it still work to provide end to end congestion control by purchasing server and having traffic routed through that?
Or is that also doomed to fail?
How much does end to end help vs just received end?
Just seems such a shame that hasn't been properly implemented by ISPs for all last mile links to ensure clients are not only provided with bandwidth but also low latency. Is it just a matter of time I wonder.
I'm doing just that, running a VPN on a rented VPS and running all traffic through that. Then CAKE does its magic for download on that end, instead of running it in ingress mode on an IFB.
In my experience this works much better than shaping on ingress, as you can then actually control the queue before it reaches the last mile link, given that there's nothing else using bandwidth outside the tunnel.
It worked even better on DSL, where the sync rate rarely changed and I could get by using a script polling the sync rates from the modem every few minutes - then setting the shaper rates from that.
Now with LTE the issues I'm seeing is well covered in this thread. Beyond that one annoyance is the fact that I'm routing an extra IP address to my home router so I'm doing NAT on the VPS. Meaning the host isolation modes in CAKE doesn't work for download.
I've been toying with the idea of something that reads the conntrack table on the home router and sends that to the VPS (not literally sync the tables, just so it can be used to tag the flows to the right host in CAKE) and lets CAKE use that.
Yes theoretically that is not nice, but typically only one direction is loaded, so that moving the other un-loaded direction back to the configured minimum rate is the desired outcome anyway it is just happening a bit faster, no?
I would hypothesize this comes from CUBIC, as larger shaper increase steps will cause larger overshoots of the true bottleneck capacity, which in turn will lead to more data in flight and that in turn will cause larger/longer bufferbloat episodes. That can be an acceptable trade-off, but it certainly appears to be a consequence of faster rate "learning".
I am not sure that without a proper reflector this is going to work as they need packet spacing information at the receiver. Not impossible but that means a dedicated program at the other end.... at which point one needs an VPS an might be able to simply set up sprout as a tunnel for all traffic...
In theory that might work, in practice however I am not sure how hard this would be, given that wireguard is multi-threaded and will decrypt in parallel un multiple CPUs, I would assume piping wiregourd through a sprout tunnel might be easer to achieve.
The challenge with "auto-back-off" protocols is always that they are open to being crowded out if competing with less reactive flows.
So the problem is, end to end does not solve the issue reliably, otherwise we would not be in the mess that we are in. IMHO consistent low latency requires cooperation of end-points and network nodes.
Yes.
One would hope, but the problem here is that unless end-users are willing to pay a premium for low latency there is very little incentive for ISPs to invest in the additional hardware capabilities that enable reasonably low latency over their links to the end users. In 5G low latency has been turned into a marketing term, but looking at what they offer right now, it seems a bit optimistic....
Sure, we all agree that egress shaping is more immediate and more precise than ingress shaping, but "much better" really? ![]() (I am still impressed how well ingress shaping does work, especially with cake and its
(I am still impressed how well ingress shaping does work, especially with cake and its ingress keyword).
Did your ISP use SRA and did you really see big rate sync rate fluctuations on your DSL link during "showtime"?
You could try to remedy this with an additional ingress cake instance in your home which could be run simply in dsthost mode, relaying on the VPS shaper to deliver pe flow fairness. Then again, I might be overlooking something here ad that might gloriously fail.
Confirmed... your version (or my lack of tainting the other one) indeed works once a download is started...
Pardon my ignorance, but can you point me to the line(s) that govern this? And elaborate a little on where this restriction is tied to?
The thing is... without doing a download it doesn't work... once you do a big download... the script 'works' (i.e. it doens't just decay back to the no-download low afaik... and continues to dynamically scale around the correct top values in the case of my non-lte connection)
Capacity of the connection is known via max/min_dl_rate is it not? (or you are referring to
link bw counters and such?)
in otherwords...
The following lines in get_next_shaper_rate implement the rate selection for all handled conditions:
if awk "BEGIN {exit !($cur_delta_RTT >= $cur_max_delta_RTT)}"; then
next_rate=$( call_awk "int(${cur_rate} - ${cur_rate_adjust_RTT_spike} * (${cur_max_rate} - ${cur_min_rate}) )" )
else
# ... otherwise take the current load into account
# high load, so we would like to increase the rate
if awk "BEGIN {exit !($cur_load >= $cur_load_thresh)}"; then
next_rate=$( call_awk "int(${cur_rate} + ${cur_rate_adjust_load_high} * (${cur_max_rate} - ${cur_min_rate}) )" )
else
# low load gently decrease the rate again
next_rate=$( call_awk "int(${cur_rate} - ${cur_rate_adjust_load_low} * (${cur_max_rate} - ${cur_min_rate}) )" )
fi
fi
This is called twice, once for download and once for upload...
Yes, but @Lynx goal is to decay back to the minimum, as on his LTE link he can only trust the minimum to be reliably available...
Yes, these set the limits for the rate adjustments, but when deciding whether to increase the shaper rate the script also looks whether the load (ration of actual traffic volume transferred during the last tick compared to the maximum that could have been transferred at the given shaper rate) exceeds a threshold (if the link is still massively underused increasing the shaper rate is not going to help much). The beauty of @Lynx's "look at the load" idea is that without load we have no chance of figuring out whether a given shaper setting is below the true bottleneck rate but we also would not profit from a higher shaper rate, so we just leave it alone in the case of low load. While bufferbloat tests require to generate saturating loads, here we simply use the existing "organic" load on the link which apparently works pretty well.
It does, it is just that the safe default is the configured minimum....
We discussed that in the past already, but without a decent use-case of such a functionality it is unlikely anybody will implement that.
That said, I think the solution would be to configure a third rate value per direction (resting_rate or default_rate) and control the decay such that without load the rate does not decay towards the minimum but towrds the default_rate, then @Lynx can set default_rate=$minimum_rate, you can set default_rate=$maximum_rate, and cautious users can set this somewhere between the extremes.... But again without a reason to implement that it might not actually happen.
I could imaging links which typically can sustain their maximum but during prime time might only be able to sustain say 50% and then setting the default to 100% and the minimum to 50% would still allow for better latency-uder-load at prime time without sacrificing throughput during the day... but I digress.
yes... this is sort of what i'd had in mind... a sort of 'decay_bias/rate_change_bias' if you will...
a good place to factor in some exponential / express scaling perhaps (which will greatly benefit LTE due to jumpy physical layer properties)...
I guess there are quite a few good ways to define / overlay bias motivations...
i.e.
calc_median_jump() {
#store and calc the median rate_jump for the last X(15?) reads
#actually medians not the right word...
#total_max_jump over last 15 reads etc. etc.
#optional> what percent of max_rate-min_rate is this delta
#SMALL MED LARGE -> scale the jump_rate further?
#if last jump was in same direction... add some more bias
#or change SMALLJUMP > MEDJUMP etc. etc.
}
(thankyou for the other explanations btw)
Just keep in mind, that by changing our shaper we only indirectly affect the actually load-generating flows, so we need to not over do things by changing too quickly or in too big steps (mostly down) to avoid creating oscillations/resonances. A slower/dampened control loop is IMHO less likely to experience such effects (says my gut-feeling).
agreed... unless other metrics are factored into said changes...
Happy to implement this if you think worthwhile for some. Might another use case be those rather weak LTE connections where more latency has to be sacrificed to get bandwidth so decaying down to minimum would mean too little bandwidth.
So I understand this correctly it will decay down to this value and stay there until load is detected at which point it will increase the rate as usual? So if this rate is set at maximum the effect would be steady state unless say the ISP becomes exceptionally congested and then will scale down to address that. What happens when load is dropped after that scaling down following RTT spike? It decays upwards rather than downwards?
That sounds painful, give that posix shell has no real arrays... But I guess one could do the array manipulations in AWK and construct strings as inputs and outputs, so that shell only ever sees single strings... but that would still require some nasty code to massage said strings (as these would need to carry both AWKs result, as well as the last sate of the array)
Well, that depends, if the last set rata was below the default it will technically not "decay" but grow up, but always with the same long term alpha....
Exactly, and if it is set to the minimum it wil give the current behaviour.
Yes, it will either decay or grow depending on where it was when the load ceased, we could/should implement two independent alphas here....
Not just a case of alpha sign flipping but also the rate? Like would we want to decay up and down towards steady state at same rate of different rates?
Flipping sign would be easy I suppose and maybe you still want to return to steady state slowly. So rate same?
Mmmh, you are right, let's start simple....
Hehe, ingress shaping has gotten rather good I'll admit, but on low bandwidth links like the ADSL line we had, CAKE on ingress couldn't handle things like Steam downloads that fire up multiple connections without RTT going through the roof. I likely could've gotten ingress mode to work alright, but that would mean sacrificing a big percentage of the bandwidth.
They did, and they also switched automatically between fastpath and interleave modes depending on line conditions, so when that happened I could lose/gain a fair bit of bandwidth. I should add that we're 4.5 km from the central office, so it was a miracle really that it worked as well as it did.
Could very well work, if it does it'd save me a lot of time figuring out another way : )
I do note that as long I'm not limited by radio conditions the PGW does a pretty alright job shaping the link to the subscription rate, obviously not a FIFO there, so as long as the signal is good, I could probably get away with just running CAKE on ingress. Should be easier if I could get a modem that doesn't mess me about with changing LTE bands by itself
Is that when using TCP? Vodafone UK applies 10Mbit/s throttling on port 443 and otherwise I think many LTE providers employ various forms of traffic shaping in times of congestion. Since I don't want to be subjected to restrictions like the 10Mbit/s on port 443 I use a VPN (NordVPN). But WireGuard is UDP only. So I think I am in this weird situation where I need to use VPN to circumvent overly restrictive / dubious throttling practices by my ISP and then my own SQM to address increased bufferbloat associated with UDP and thus not benefitting from TCP's congestion control? That stated, I think I'd still want to use SQM anyway because although the latency increase without VPN was not as bad, it was still there.
How do you signal to your sender the bandwidth for it to use?
Also why don't you try sprout?
No I haven't tested that. I currently run everything over WireGuard, so my ISP only sees UDP.
I would've done more testing without a tunnel, but I've had some weird issues where connections start failing after a while if I do.
You'd still benefit from TCP congestion control though, no? Sure the encapsulated packets won't directly, but everything using TCP inside the tunnel still would. I might be wrong, but my understanding is that it shouldn't act any different than if it wasn't encapsulated.
But you are of course subject to any buffering WireGuard might do, not sure if it does anything that could affect latency.
If you mean the rate for CAKE on the VPS, I currently do not.
Since I'm mostly hitting the limit for the PGW shaper on the ISP side, I can just set it to the subscription rate and it'll for the most part work fine.
The problem I'm seeing is mostly that the rate can be too low for it to ramp up speed sometimes, so sqm-autorate should be great for this, but I'd have to change it to allow for only egress. And of course, ideally it should be able to see if it's download or upload rates than needs changing, haven't read the whole discussion on that.
I might've missed it, but I haven't seen anything that's "ready to use"?
Is one of the examples in https://github.com/keithw/sprout/tree/master/src/examples something worth testing? Didn't see any documentation anywhere on what's what.
@moeller0 any thoughts? I found on my connection by not going over WireGuard I didn't get such high bufferbloat. It is true that my ISP seems to do a lot of funky management like the 10Mbit/s throttling per 443 stream, which presumably could actually help with bufferbloat for those individual streams (not that I am happy with that because it limits downloads and I think even OneDrive activity). But I think there was more to it than that which I do not understand. Maybe the traffic management that ISP puts in has a good component and an evil component, and that by removing the evil component by using VPN I lose out on the good component.
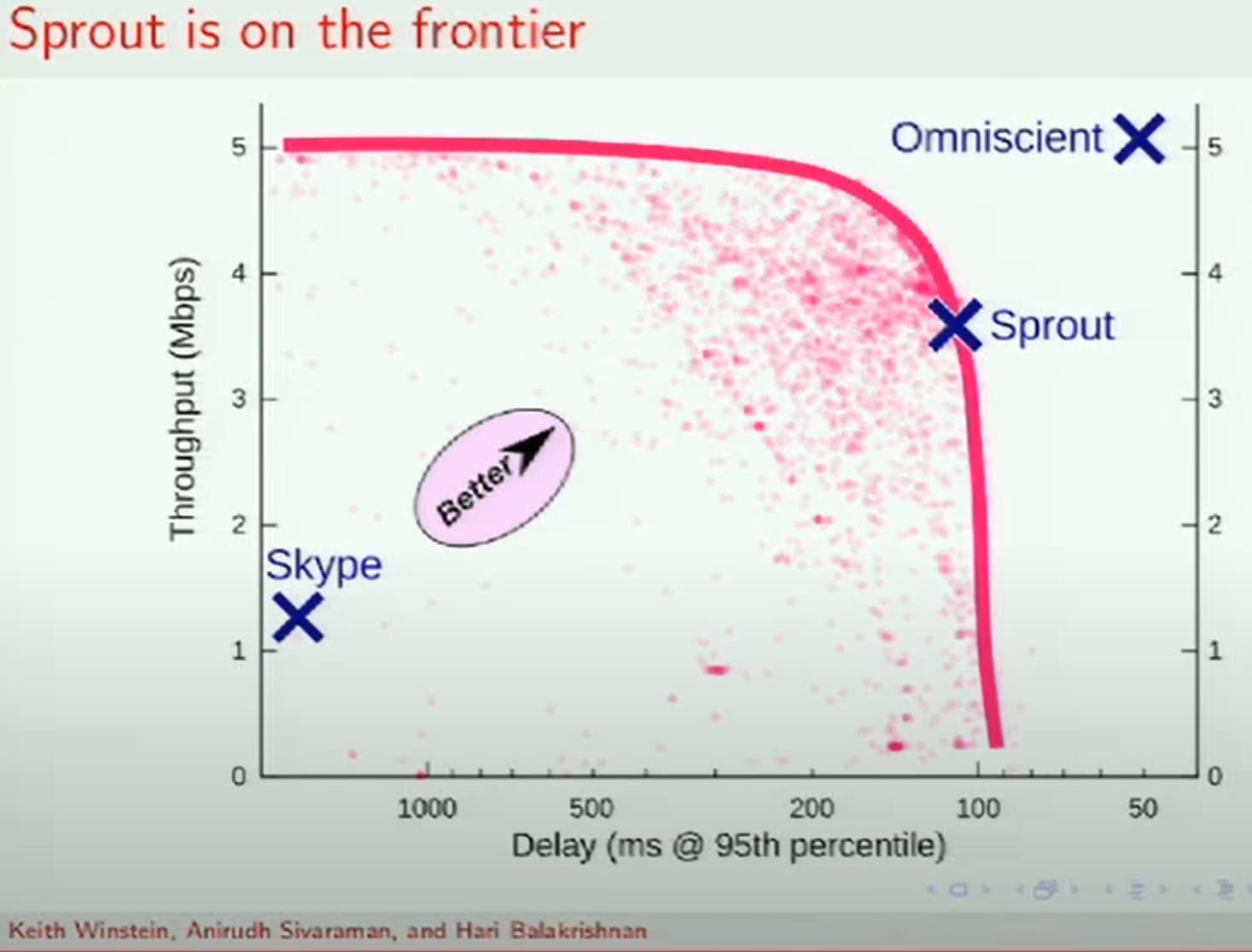
I am not sure. It is just the MIT paper and video looked promising. But it might just be me being gullible. As @moeller0 points out, why didn't sprout get widely adopted and stay as obscure as it has done. Then again it could still be amazing. They set MIT students the task of addressing this problem and found a frontier of latency/bandwidth tradeoff, with sprout sitting in a nice place:
not really... as discussed...;
feel free to unpack my(well based on your) tar.gz and give it a try... it has enough comments and such and most of the foundation logic to work around all these things...
be aware tho' it is far from finished... but it's enough to grapple with whats involved...