A little update...
I have done a little more testing but I haven't had time to do a whole lot more. My goal is to isolate the Starlink specific test from the rest of autorate, in order to verify if reducing the CAKE bandwidth during the Starlink switches will reduce the latency spikes, since the latency spikes during the Starlink switches are predictable.
To do this, I altered the parameters in the autorate code to essentially keep CAKE at the maximum bandwidth (200/30 down/up) for all times except during the Starlink switch times, so it essentially wouldn't be doing any autorating except for the dropping to minimum during the Starlink switches.
Then I would ran a 5 minute flent test with that functionality followed by my control which is the exact same code EXCEPT I altered the Starlink times in the autorate code to subtract 7 seconds from each. So it is still lowering the CAKE bandwidth the same amount of time each minute, only it is doing it at the "wrong" times. If the Starlink specific code is useful, then there should be a clear difference in the results.
Unfortunately I didn't really see a clear difference.
So I'm working on validating to make sure it is actually switching at the correct time, as that could be one source of error. The autorate code is running on my OpenWrt router, but the other irtt and flent tests I've been running on my computer. Both are time synced with NTP but I haven't confirmed that the time on the router is synced right so that's what I'd like to do next.
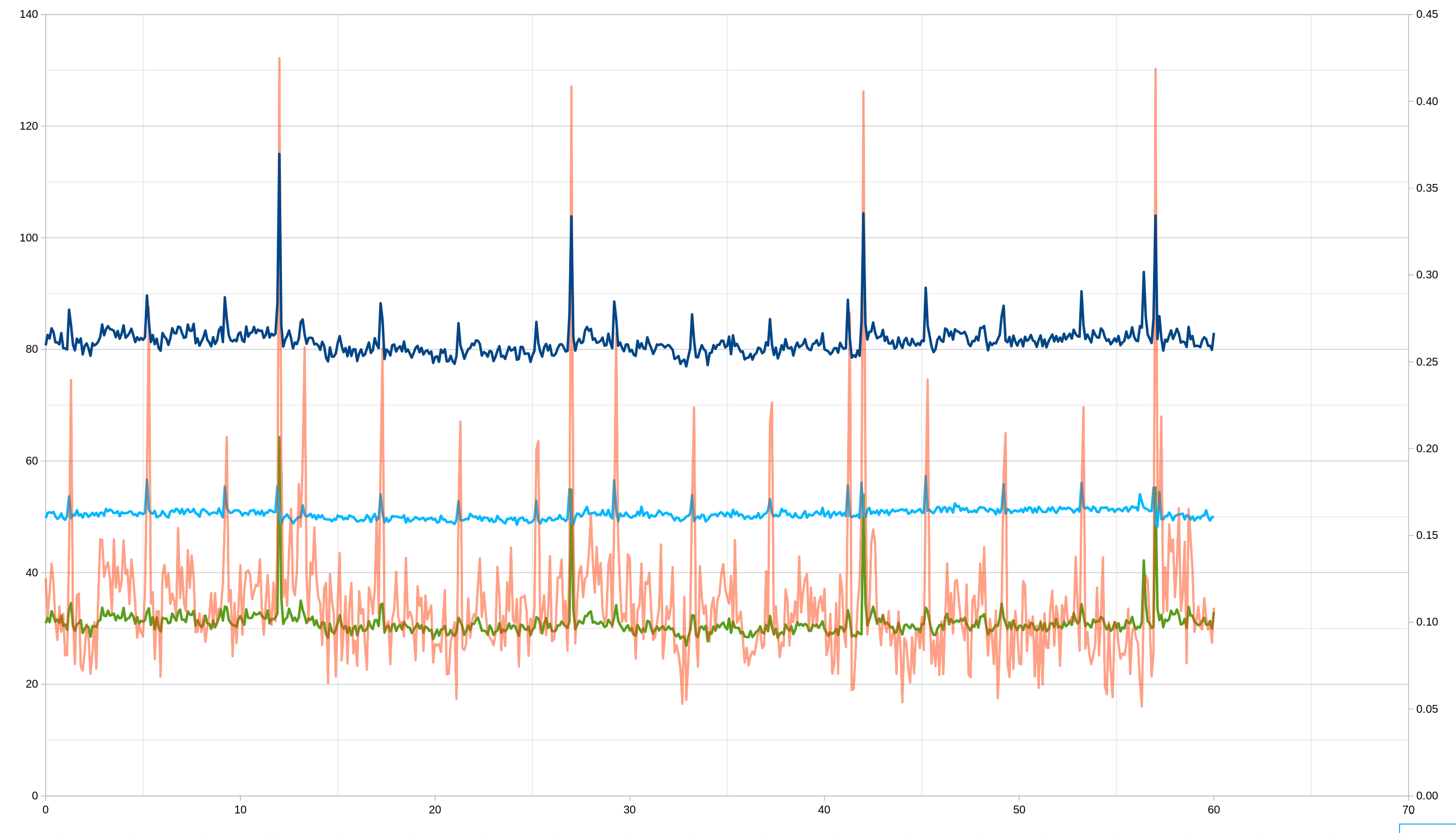
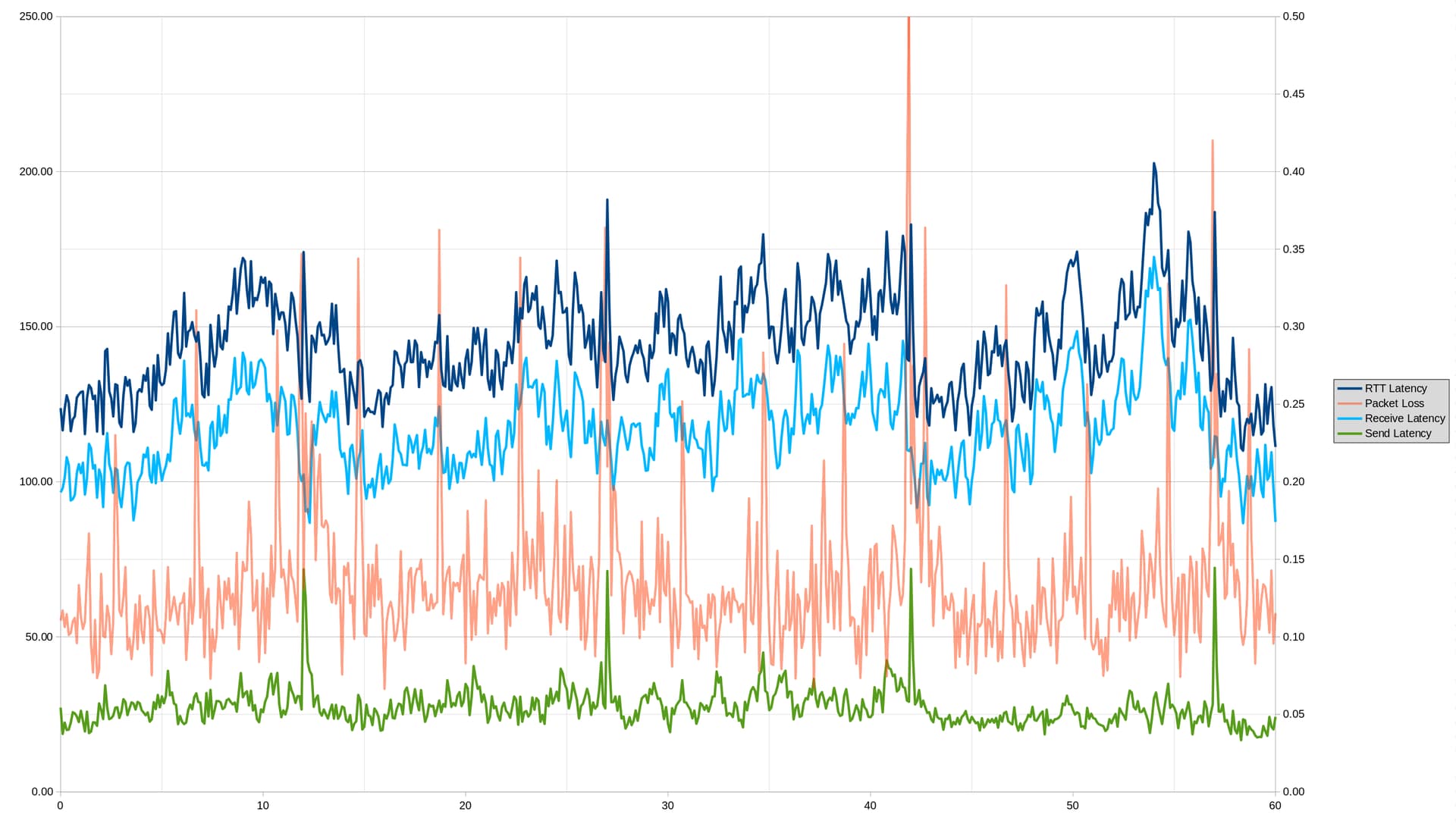
I did run a test on my computer that I thought was interesting, in order to kind of double-check the Starlink switches. So this is with autorate turned off, so CAKE is just set to a fixed rate of 200/30, and I did a 20 minute flent test while simultaneously doing a 20 minute irtt like "irtt client --dscp=0xfe -i3ms -d20m" as @dtaht suggested (so irtt was done under load).
Then I took the rtt and lost packets and put them in bins based on what tenth of a second after a minute they were sent. Here is the result:
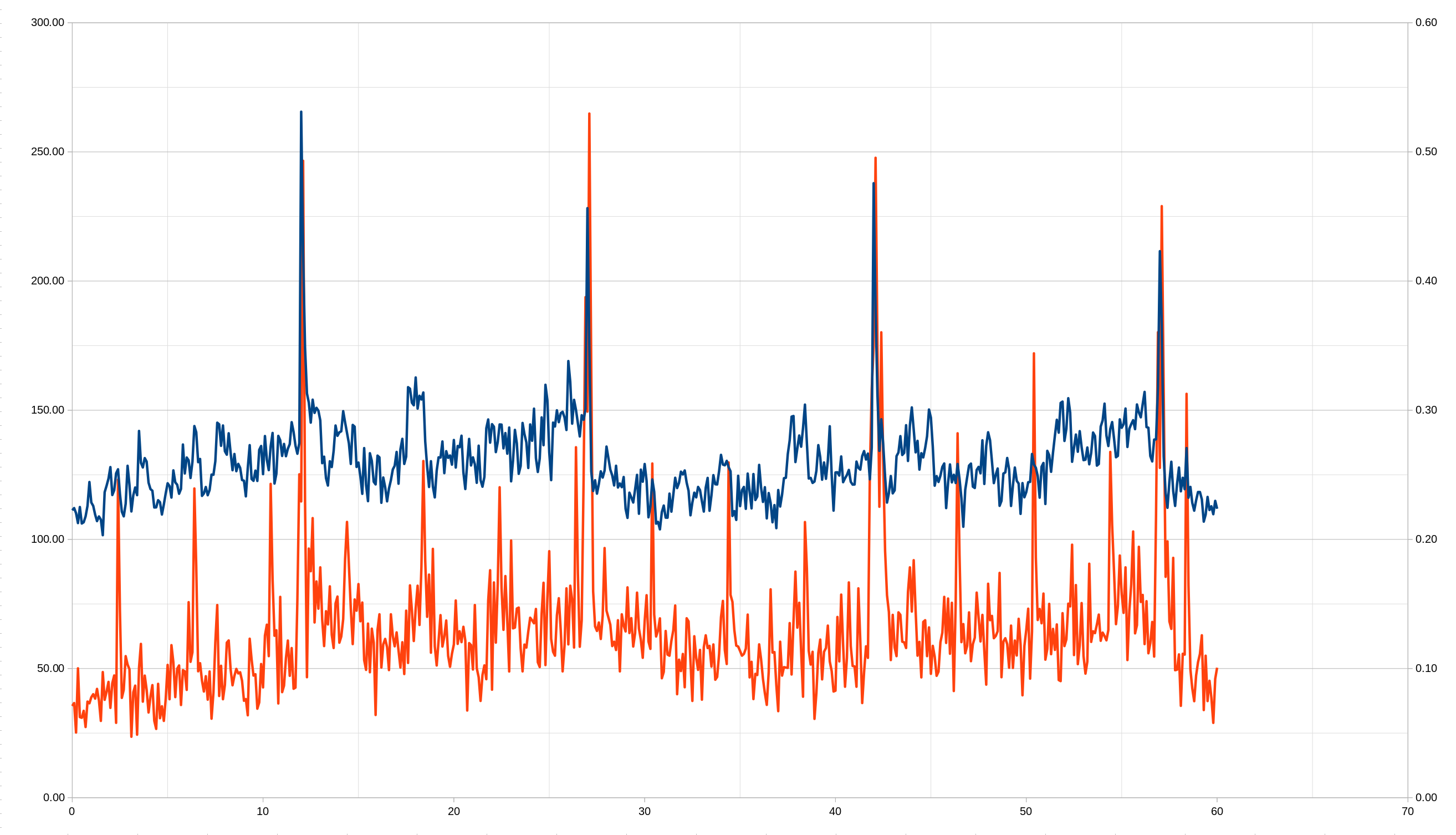
So the irtt mean RTT is 129.5 ms (send delay is 20.9 ms and receive delay 108.6 ms) and the packets lost were 13.02% (12.41% were lost up and 0.70% lost down)...side note, I'm wondering if anyone has a Starlink theory why the send delay was so much shorter than the receive delay but the packets lost sending is a lot higher than the packets lost receiving?
On the graph, the X axis is the number of seconds after the minute, the left Y axis is the RTT latency (blue), the right Y axis is the % packet loss (red). There is clearly a big spike in latency and packets lost around the time of the Starlink switches, although it is curious that there does look to be a spike in packets lost on a regular shorter interval as well.
Data around the switches:
| Seconds | Latency | Packet Loss |
|---|---|---|
| 11.6 | 141.60 | 0.08 |
| 11.7 | 136.31 | 0.09 |
| 11.8 | 133.16 | 0.15 |
| 11.9 | 137.28 | 0.25 |
| 12 | 265.56 | 0.23 |
| 12.1 | 211.20 | 0.49 |
| 12.2 | 174.33 | 0.23 |
| 12.3 | 156.53 | 0.09 |
| 12.4 | 152.92 | 0.19 |
| 12.5 | 145.20 | 0.18 |
| 26.7 | 148.08 | 0.14 |
| 26.8 | 146.29 | 0.25 |
| 26.9 | 150.48 | 0.39 |
| 27 | 228.21 | 0.30 |
| 27.1 | 174.67 | 0.53 |
| 27.2 | 126.35 | 0.33 |
| 27.3 | 118.72 | 0.16 |
| 27.4 | 122.90 | 0.13 |
| 41.7 | 133.21 | 0.11 |
| 41.8 | 123.27 | 0.25 |
| 41.9 | 135.52 | 0.32 |
| 42 | 237.87 | 0.35 |
| 42.1 | 188.84 | 0.50 |
| 42.2 | 155.85 | 0.35 |
| 42.3 | 134.27 | 0.23 |
| 42.4 | 146.50 | 0.36 |
| 42.5 | 136.88 | 0.26 |
| 42.6 | 124.22 | 0.19 |
| 56.6 | 130.16 | 0.14 |
| 56.7 | 138.63 | 0.11 |
| 56.8 | 138.74 | 0.22 |
| 56.9 | 159.06 | 0.36 |
| 57 | 211.56 | 0.26 |
| 57.1 | 183.13 | 0.46 |
| 57.2 | 132.16 | 0.32 |
| 57.3 | 118.03 | 0.17 |
| 57.4 | 112.22 | 0.20 |
So I still think it seems like it should be helpful to reduce the CAKE bandwidth around the switches, but if anyone knows CAKE a lot better than me and thinks differently then let me know!